
Az AI-képzési projektek ritkán buknak meg modellszinten. Akkor kerülnek nehéz helyzetbe, ha a kísérletek, a dokumentáció és az érdekelt felek frissítései túl sok eszközön vannak szétszórva.
Ez az útmutató végigvezeti Önt a Databricks DBRX-szel történő modellek képzésén – ez egy LLM, amely akár kétszer olyan számítási hatékonyságú, mint más vezető modellek –, miközben a vele kapcsolatos munkát a ClickUp-ban szervezi.
A beállítástól és finomhangolástól a dokumentációig és a csapatok közötti frissítésekig megismerheti, hogyan segít egy egységes, konvergált munkaterület megszüntetni a kontextus szétszóródását, és hogyan segít a csapatnak a keresés helyett a fejlesztésre koncentrálni. 🛠
Mi az a DBRX?
A DBRX egy hatékony, nyílt forráskódú nagy nyelvi modell (LLM), amelyet kifejezetten vállalati AI-modellek képzésére és következtetések levonására terveztek. Mivel a Databricks Open Model License nyílt forráskódú, csapata teljes hozzáféréssel rendelkezik a modell súlyozásaihoz és architektúrájához, így saját feltételei szerint ellenőrizheti, módosíthatja és telepítheti azt.
Két változatban érhető el: a DBRX Base a mély előzetes képzéshez, a DBRX Instruct pedig a készre szabott utasításkövető feladatokhoz.
A DBRX architektúrája és a szakértők keverékének kialakítása
A DBRX a Mixture-of-Experts (MoE) architektúrát használja a feladatok megoldásához. A hagyományos nagy nyelvi modellektől eltérően, amelyek minden egyes számításhoz több milliárd paraméterüket használják, a DBRX csak a teljes paraméterek egy részét (a legrelevánsabb szakértőket) aktiválja egy adott feladat elvégzéséhez.
Gondoljon rá úgy, mint egy szakértői csapatra: ahelyett, hogy mindenki minden problémán dolgozna, a rendszer intelligensen irányítja az egyes feladatokat a legalkalmasabb paraméterekhez.
Ez nemcsak a válaszidőt rövidíti le, hanem első osztályú teljesítményt és eredményeket is biztosít, miközben jelentősen csökkenti a számítási költségeket.
Íme egy rövid áttekintés a legfontosabb specifikációkról:
- Összes paraméter: 132 milliárd az összes szakértőnél
- Aktív paraméterek: 36B előrehaladásonként
- Szakértők száma: összesen 16 (MoE Top-4 routing), ebből 4 aktív bármely adott token esetében
- Kontextus ablak: 32K token
DBRX képzési adatok és token specifikációk
Az LLM teljesítménye csak annyira jó, mint az adatok, amelyekkel edzették. A DBRX-et előzetesen egy hatalmas, 12 billió tokenből álló adatkészleten edzették, amelyet a Databricks csapata gondosan válogatott össze fejlett adatfeldolgozó eszközeivel. Pontosan ezért teljesített olyan jól az iparági benchmarkok során.
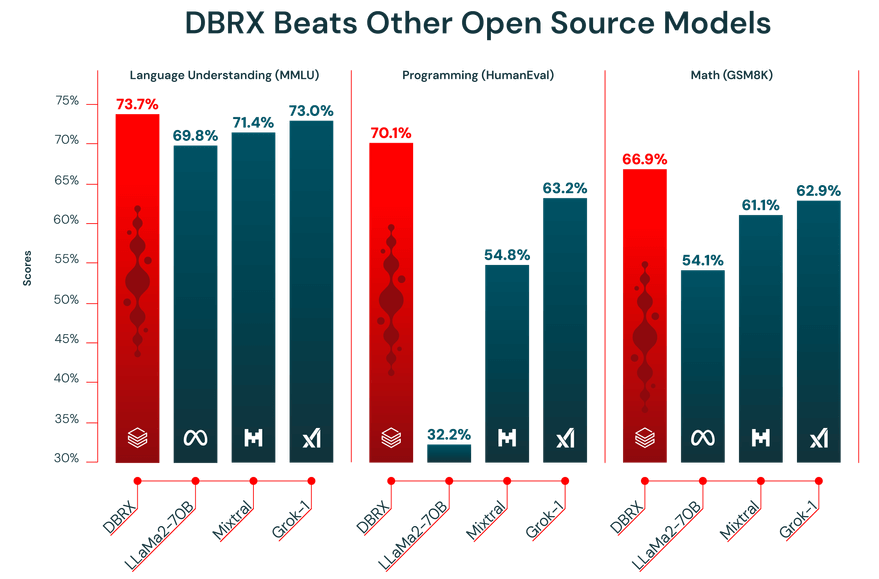
Ezenkívül a DBRX 32 000 tokenes kontextusablakkal rendelkezik. Ez az a szövegmennyiség, amelyet a modell egyszerre képes feldolgozni. A nagy kontextusablak rendkívül hasznos komplex feladatokhoz, például hosszú jelentések összefoglalásához, hosszú jogi dokumentumok átnézéséhez vagy fejlett visszakereséssel kiegészített generációs (RAG) rendszerek építéséhez, mivel lehetővé teszi a modell számára, hogy a kontextust megőrizze anélkül, hogy információkat csonkítana vagy elfelejtene.
🎥 Nézze meg ezt a videót, hogy megtudja, hogyan tudja a racionalizált projektkoordináció átalakítani az AI-képzési munkafolyamatot, és kiküszöbölni a különálló eszközök közötti váltás okozta súrlódásokat. 👇🏽
Hogyan lehet hozzáférni és beállítani a DBRX-et
A DBRX két fő hozzáférési útvonalat kínál, amelyek mindegyike teljes hozzáférést biztosít a modell súlyozásaihoz engedékeny kereskedelmi feltételek mellett. A maximális rugalmasság érdekében használhatja a Hugging Face-t, vagy közvetlenül a Databricks-en keresztül érheti el a még integráltabb élmény érdekében.
Hozzáférés a DBRX-hez a Hugging Face-en keresztül
Azok számára, akik értékelik a rugalmasságot és már jól ismerik a Hugging Face ökoszisztémát, a Hubon keresztül történő DBRX-hozzáférés az ideális megoldás. Ez lehetővé teszi a modell integrálását a meglévő transzformátor-alapú munkafolyamatokba.
Így kezdheti el:
- Hozzon létre vagy jelentkezzen be Hugging Face-fiókjába
- Keresse meg a DBRX modellkártyát a Hubon, és fogadja el a licencfeltételeket.
- Telepítse a transzformátorok könyvtárát a szükséges függőségekkel együtt, például az accelerate-tel.
- Használja az AutoModelForCausalLM osztályt a Python szkriptjében a DBRX modell betöltéséhez.
- Konfigurálja az inferencia-pipeline-t, szem előtt tartva, hogy a DBRX hatékony működéséhez jelentős GPU-memória (VRAM) szükséges.
📖 További információ: Az LLM hőmérséklet beállítása
Hozzáférés a DBRX-hez a Databricks segítségével
Ha csapata már használja a Databricks-et adatfeldolgozáshoz vagy gépi tanuláshoz, a legegyszerűbb módszer a DBRX-hez való hozzáférés a platformon keresztül. Ezzel elkerülhető a beállítási nehézségek, és minden MLOps-hoz szükséges eszköz a már meglévő munkakörnyezetben elérhetővé válik.
Kövesse az alábbi lépéseket a Databricks munkaterületén, hogy elindulhasson:
- Lépjen a Model Garden vagy a Mosaic AI szakaszra.
- Válassza ki az Ön igényeinek megfelelő DBRX Base vagy DBRX Instruct verziót.
- Konfiguráljon egy kiszolgáló végpontot az API-hozzáféréshez, vagy állítson be egy notebook környezetet interaktív használatra.
- Kezdje el tesztelni a következtetést mintautasításokkal, hogy megbizonyosodjon arról, hogy minden megfelelően működik, mielőtt AI-modelljének képzését vagy bevezetését kiterjesztené.
Ez a megközelítés zökkenőmentes hozzáférést biztosít olyan eszközökhöz, mint az MLflow a kísérletek nyomon követéséhez és a Unity Catalog a modellek irányításához.
📮 ClickUp Insight: Az átlagos szakember naponta több mint 30 percet tölt munkával kapcsolatos információk keresésével – ez évente több mint 120 óra, amelyet e-mailek, Slack-szálak és szétszórt fájlok átkutatásával veszít el.
A munkaterületébe beágyazott intelligens AI-asszisztens megváltoztathatja ezt. Ismerje meg a ClickUp Brain-t.
Azonnali betekintést és válaszokat nyújt azáltal, hogy másodpercek alatt előkeresi a megfelelő dokumentumokat, beszélgetéseket és feladatokat, így Önnek nem kell tovább keresnie, hanem azonnal munkához láthat.
Hogyan lehet finomhangolni a DBRX-et és betanítani az egyedi AI modelleket
Egy kész modell, bármilyen hatékony is legyen, soha nem fogja megérteni vállalkozása egyedi sajátosságait. Mivel a DBRX nyílt forráskódú, finomhangolhatja, hogy olyan egyedi modellt hozzon létre, amely a vállalat nyelvét beszéli, vagy elvégzi azt a konkrét feladatot, amelyet szeretne, hogy elvégezzen.
Ehhez három általános módszer áll rendelkezésre:
1. Finomítsa a DBRX-et a Hugging Face adatkészletekkel
Azok számára, akik most kezdik vagy közös feladatokon dolgoznak, a Hugging Face Hub nyilvános adatkészletei kiváló források. Előre formázottak és könnyen betölthetők, így nem kell órákat töltenie az adatok előkészítésével.
A folyamat meglehetősen egyszerű:
- Keressen a Hubon egy adatállományt, amely megfelel a feladatának (pl. utasítások követése, összefoglalás).
- Töltse be az adatkészletek könyvtárából.
- Győződjön meg arról, hogy az adatok utasítás-válasz párokba vannak formázva.
- Konfigurálja a képzési szkriptjét olyan hiperparaméterekkel, mint a tanulási sebesség és a kötegméret.
- Indítsa el a képzési feladatot, és ügyeljen arra, hogy rendszeresen mentse a ellenőrzőpontokat.
- Értékelje a finomhangolt modellt egy visszatartott validációs készleten, hogy mérje a javulást.
2. Finomítsa a DBRX-et helyi adatkészletekkel
Általában a legjobb eredményeket a saját, saját tulajdonú adatokkal végzett finomhangolással érheti el. Ez lehetővé teszi, hogy a modellt a vállalatának sajátos terminológiájára, stílusára és szakterületi ismereteire tanítsa. Ne feledje azonban, hogy ez csak akkor kifizetődő, ha az adatok tiszták, jól előkészítettek és elegendő mennyiségűek.
Kövesse az alábbi lépéseket a belső adatok előkészítéséhez:
- Adatgyűjtés: Gyűjtsön össze kiváló minőségű példákat a belső wikikből, dokumentumokból és adatbázisokból.
- Formátumkonverzió: Szervezze adatait konzisztens utasítás-válasz formátumba, gyakran JSON sorok formájában.
- Minőségi szűrés: Távolítson el minden alacsony minőségű, duplikált vagy irreleváns példát.
- Validációs felosztás: Tegyen félre egy kis részt az adataiból (általában 10-15%) a modell teljesítményének értékeléséhez.
- Adatvédelmi felülvizsgálat: Távolítson el vagy maszkoljon el minden személyes azonosításra alkalmas információt (PII) vagy érzékeny adatot.
3. Finomítsa a DBRX-et a StreamingDataset segítségével
Ha az adatkészlete túl nagy ahhoz, hogy elférjen a gépe memóriájában, ne aggódjon, használhatja a Databricks Streaming Dataset könyvtárát. Ez lehetővé teszi, hogy a modell képzése közben közvetlenül a felhőalapú tárolóból streamelje az adatokat, ahelyett, hogy egyszerre töltené be az összeset a memóriába.
Így teheti meg:
- Adatelőkészítés: Tisztítsa meg és strukturálja a képzési adatait, majd tárolja azokat streamelhető formátumban, például JSONL vagy CSV formátumban a felhőalapú tárolóban.
- Streaming formátum konverzió: Konvertálja adatkészletét streaming-barát formátumba, például Mosaic Data Shard (MDS) formátumba, hogy az edzés során hatékonyan olvasható legyen.
- A képzési betöltő beállítása: Konfigurálja a képzési betöltőt úgy, hogy a távoli adatkészletre mutasson, és határozza meg a helyi gyorsítótárat az ideiglenes adattároláshoz.
- Modell inicializálás: Indítsa el a DBRX finomhangolási folyamatát egy olyan képzési keretrendszer segítségével, amely támogatja a StreamingDataset-et, például az LLM Foundry-t.
- Streaming-alapú képzés: Futtassa a képzési feladatot, miközben az adatok a képzés során kötegekben streamelnek, ahelyett, hogy teljes egészében a memóriába töltenék őket.
- Ellenőrzési pontok és helyreállítás: Ha a futtatás megszakad, folytassa a képzést zökkenőmentesen, anélkül, hogy az adatokat duplikálná vagy kihagyná.
- Értékelés és telepítés: Ellenőrizze a finomhangolt modell teljesítményét, és telepítse azt a kívánt kiszolgálási vagy következtetés-beállítással.
💡Profi tipp: Ahelyett, hogy a DBRX képzési tervét a nulláról építené fel, kezdje a ClickUp AI és gépi tanulási projektek ütemterv sablonjával , és igazítsa azt csapata igényeihez. Ez egyértelmű struktúrát biztosít az adatkészletek, a képzési fázisok, az értékelés és a bevezetés tervezéséhez, így Ön a munkafolyamatok szervezésére koncentrálhat, ahelyett, hogy a munkafolyamatokat strukturálná.
DBRX felhasználási esetek AI-modell képzéshez
Az egyik dolog, hogy rendelkezünk egy hatékony modellel, de egy másik dolog, hogy pontosan tudjuk, hol érvényesül a legjobban.
Ha nincs világos képe a modell erősségeiről, könnyen előfordulhat, hogy időt és erőforrásokat pazarol arra, hogy olyan területen próbálja működésre bírni, ahol egyszerűen nem illik. Ez alacsony színvonalú eredményekhez és frusztrációhoz vezet.
A DBRX egyedülálló architektúrája és képzési adatai kivételesen alkalmassá teszik több fontos vállalati felhasználási esetre. Ezen erősségek ismerete segít a modell üzleti céljaival való összehangolásában és a befektetés megtérülésének maximalizálásában.
Szöveggenerálás és tartalomkészítés
A DBRX Instruct finoman hangolt, hogy utasításokat kövessen és kiváló minőségű szöveget generáljon. Ez egy hatékony eszközzé teszi a tartalommal kapcsolatos feladatok széles körének automatizálásához. Nagy kontextusablaka jelentős előnyt jelent, mivel lehetővé teszi hosszú dokumentumok kezelését anélkül, hogy elveszítené a fonalat.
A következőkre használhatja:
- Műszaki dokumentáció: Termék kézikönyvek, API-referenciák és felhasználói útmutatók létrehozása és finomítása
- Marketingtartalom: Blogbejegyzések, e-mail hírlevelek és közösségi média frissítések vázlatai
- Jelentéskészítés: Összegezze a komplex adatokat, és készítsen tömör vezetői összefoglalókat.
- Fordítás és lokalizálás: A meglévő tartalom új piacokhoz és közönségekhez való igazítása
Kódgenerálás és hibakeresési feladatok
A DBRX képzési adatainak jelentős része kódot tartalmazott, így hatékony LLM-támogatást nyújt a fejlesztőknek. Segíthet a fejlesztési ciklusok felgyorsításában azáltal, hogy automatizálja az ismétlődő kódolási feladatokat és segít a komplex problémák megoldásában.
Íme néhány módszer, ahogyan mérnöki csapata kihasználhatja ezt:
- Kódkiegészítés: automatikusan generáljon függvénytesteket megjegyzésekből vagy dokumentációs karakterláncokból.
- Hibajelzés: Kódrészletek elemzése a potenciális hibák vagy logikai hiányosságok azonosítása érdekében.
- Kód magyarázat: Fordítsa le a komplex algoritmusokat vagy a régi kódokat egyszerű angol nyelvre.
- Tesztgenerálás: Hozzon létre egységteszteket egy funkció aláírása és várható viselkedése alapján.
RAG és hosszú kontextusú alkalmazások
A visszakereséssel kiegészített generálás (RAG) egy hatékony technika, amely a modell válaszait a vállalat magánadataira alapozza. A RAG-rendszerek azonban gyakran küszködnek a kis kontextusablakokkal rendelkező modellekkel, ami agresszív adatdarabolást kényszerít ki, ami fontos kontextusok elvesztéséhez vezethet. A DBRX 32K-s kontextusablaka kiváló alapot biztosít a robusztus RAG-alkalmazásokhoz.
Ez lehetővé teszi olyan hatékony belső eszközök létrehozását, mint például:
- Vállalati keresés: Hozzon létre egy chatbotot, amely a belső tudásbázis felhasználásával válaszol a munkavállalók kérdéseire.
- Ügyfélszolgálat: Hozzon létre egy ügynököt, amely a termék dokumentációján alapuló támogatási válaszokat generál.
- Kutatási segítség: Fejlesszen ki egy eszközt, amely több száz oldalnyi kutatási cikkből származó információkat képes szintetizálni.
- Megfelelőségi ellenőrzés: automatikusan ellenőrizze a marketing szövegeket a belső márkairányelvek vagy a szabályozási dokumentumok alapján.
Hogyan integrálhatja a DBRX képzést a csapat munkamenetével?
A sikeres AI-modell-edzési projekt nem csupán kódolásról és számításról szól. Ez egy együttműködés, amelyben ML-mérnökök, adatelemzők, termékmenedzserek és érdekelt felek vesznek részt.
Ha ez az együttműködés Jupyter notebookokra, Slack csatornákra és különálló projektmenedzsment eszközökre oszlik szét, akkor kontextus-szétszóródás keletkezik, vagyis olyan helyzet, amikor a kritikus projektinformációk túl sok eszközön vannak szétszórva.
A ClickUp megoldja ezt a problémát. Ahelyett, hogy több eszközzel kellene bajlódnia, egyetlen konvergált AI munkaterületet kap, ahol a projektmenedzsment, a dokumentáció és a kommunikáció együtt működik, így kísérletei a tervezéstől a végrehajtáson át az értékelésig összekapcsolódnak.
Soha ne veszítse szem elől a kísérleteket és az előrehaladást
Több kísérlet futtatásakor a legnehezebb rész nem a modell betanítása, hanem a folyamat során bekövetkezett változások nyomon követése. Melyik adatkészlet-verziót használták, melyik tanulási sebesség teljesített a legjobban, vagy melyik futtatás került kiszállításra?
A ClickUp rendkívül egyszerűvé teszi ezt a folyamatot. A ClickUp Tasks alkalmazásban minden egyes képzési futást külön nyomon követhet, és a feladatokon belül az egyéni mezők segítségével naplózhatja:
- Adatkészlet verzió
- Hiperparaméterek
- Modellváltozat (DBRX Base vs DBRX Instruct)
- Képzési állapot (sorba állítva, futás közben, értékelés alatt, telepítve)
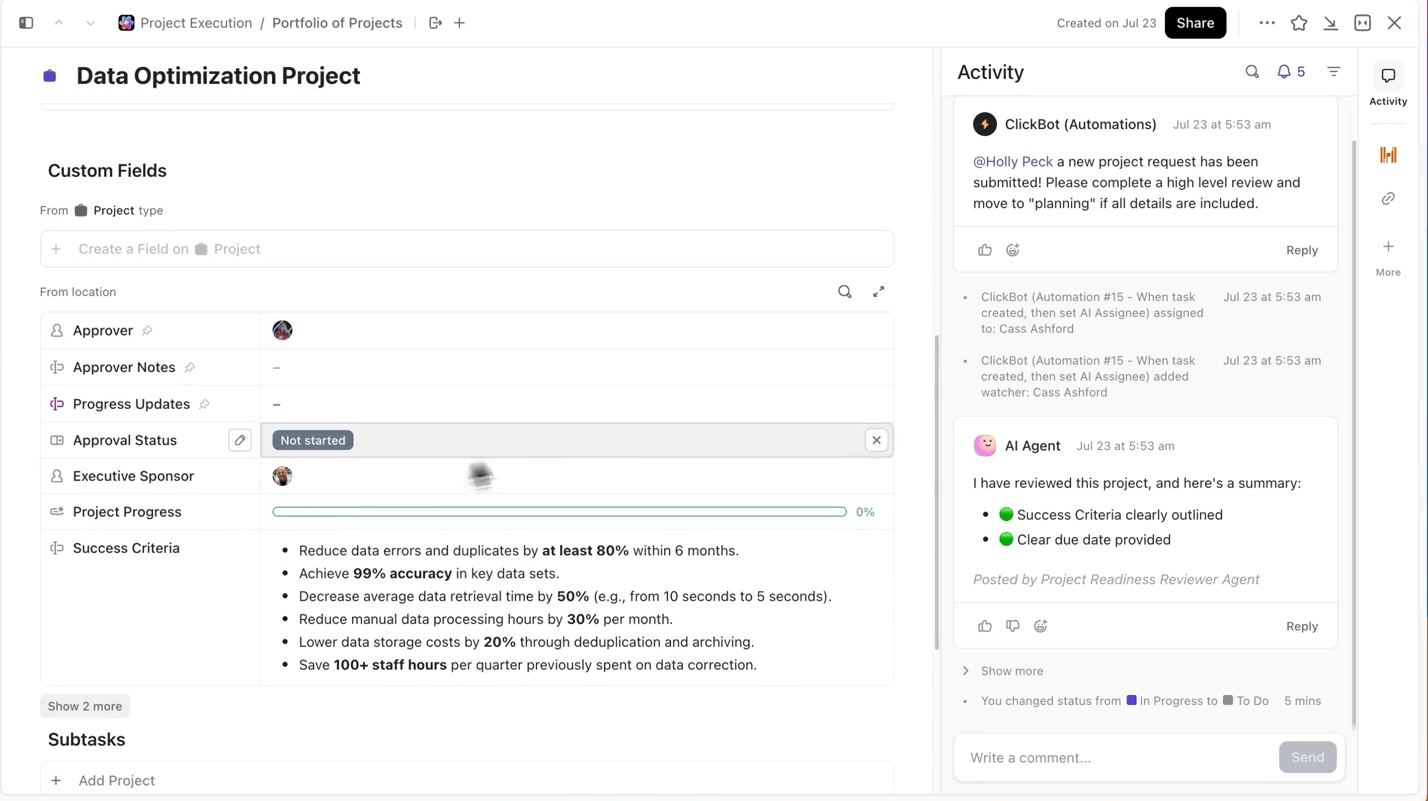
Így minden dokumentált kísérlet kereshető, könnyen összehasonlítható másokkal és reprodukálható.
Tartsa a modellek dokumentációját a munkához kapcsolva
Nem kell Jupyter notebookok, README fájlok vagy Slack szálak között ugrálnia, hogy megértse a kísérlet feladatának kontextusát.
A ClickUp Docs segítségével rendezett és hozzáférhető módon tárolhatja modellarchitektúráját, adatelőkészítő szkripteit vagy értékelési mutatóit , ha azokat egy kereshető dokumentumban dokumentálja, amely közvetlenül kapcsolódik az eredeti kísérleti feladatokhoz.

💡Profi tipp: Tartson fenn egy élő projektleírást a ClickUp Docs-ban, amely minden döntést részletesen leír, az architektúrától a telepítésig, így az új csapattagok mindig naprakészek lehetnek a projekt részleteivel, anélkül, hogy régi szálakat kellene átnézniük.
Valós idejű átláthatóságot biztosít az érdekelt felek számára
A ClickUp Dashboards valós időben mutatja a kísérletek előrehaladását és a csapat munkaterhelését. I
A frissítések kézi összeállítása vagy e-mailek küldése helyett a műveletek automatikusan frissülnek a feladatokban szereplő adatok alapján. Így az érdekelt felek bármikor ellenőrizhetik a helyzetet, és soha nem kell megzavarniuk Önt „mi a helyzet?” kérdésekkel.
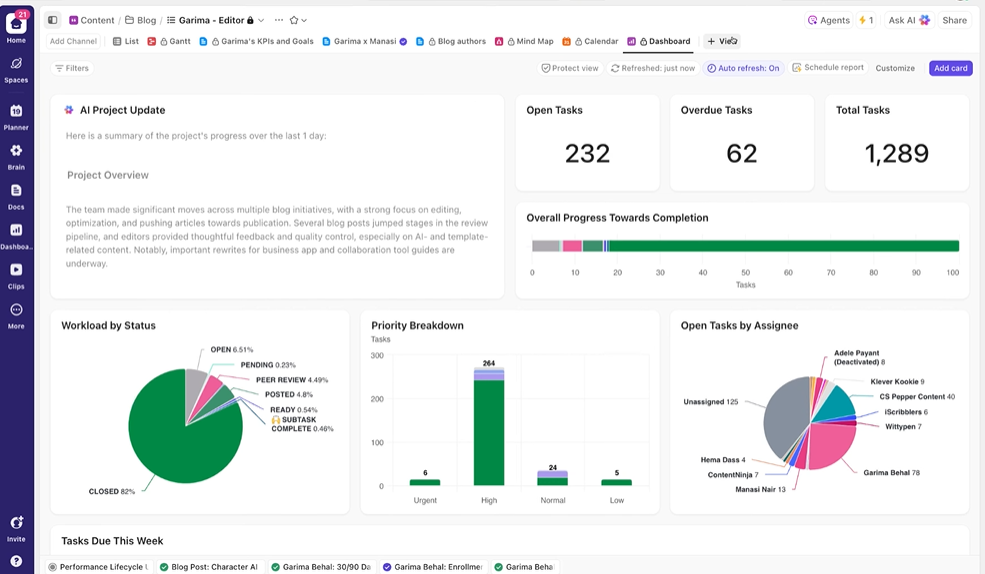
Így a kísérletek végrehajtására koncentrálhat, ahelyett, hogy folyamatosan kézzel kellene jelentést készítenie róluk.
Tegye az AI-t intelligens projekt-segédjévé
Nem kell manuálisan átnéznie a több hetes képzési adatokat, hogy összefoglalót kapjon az eddigi kísérletekről. Csak említsen meg @Brain-t bármely feladat megjegyzésében, és a ClickUp Brain megadja Önnek a szükséges segítséget a korábbi és folyamatban lévő projektek teljes kontextusával.
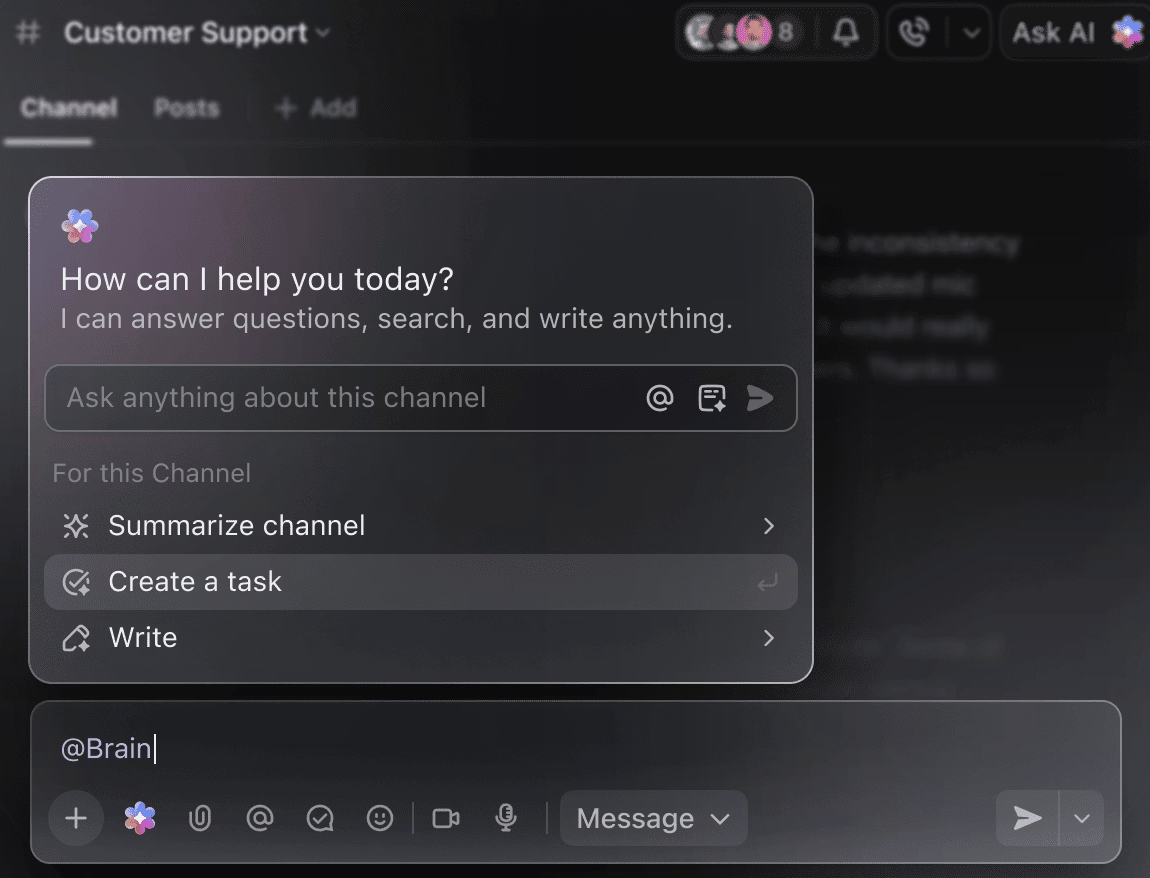
Megkérheti a Brain-t, hogy „Összegezze az elmúlt hét kísérleteit 5 pontban” vagy „Készítsen egy dokumentumot a legújabb hiperparaméter eredményekkel”, és azonnal kap egy kifinomult eredményt.
🧠 A ClickUp előnye: A ClickUp Super Agents ennél sokkal tovább megy – nemcsak a kérdéseire válaszolnak, hanem automatizálják a teljes munkafolyamatot az Ön által megadott kiváltó események alapján. A szuperügynökökkel automatikusan létrehozhat új DBRX képzési feladatot, amikor adatállományt töltenek fel, értesítheti a csapatát, és összekapcsolhatja a releváns dokumentumokat, amikor a képzés befejeződik vagy elér egy ellenőrzési pontot, valamint hetente összefoglalót készíthet az előrehaladásról, és elküldheti az érdekelt feleknek anélkül, hogy bármit is tennie kellene.
Gyakori hibák, amelyeket el kell kerülni
A DBRX képzési projektbe való belevágás izgalmas, de néhány gyakori buktató megakadályozhatja az előrehaladást. Ezen hibák elkerülésével időt, pénzt és sok frusztrációt takaríthat meg.
- A hardverkövetelmények alábecsülése: A DBRX hatékony, de nagy méretű is. Ha nem megfelelő hardveren próbálja futtatni, memóriakifogyásos hibák és sikertelen képzési feladatok lesznek a következmény. Ne feledje, hogy a DBRX (132B) legalább 264 GB VRAM-ot igényel 16 bites következtetéshez, vagy körülbelül 70–80 GB-ot 4 bites kvantálás használata esetén.
- Az adatminőség-ellenőrzés kihagyása: Ha rossz adatokat adunk be, akkor rossz eredményeket kapunk. A rendezetlen, alacsony minőségű adatkészlet finomhangolása csak arra tanítja a modellt, hogy rendezetlen, alacsony minőségű eredményeket produkáljon.
- A kontextus hosszának figyelmen kívül hagyása: Bár a DBRX 32K-s kontextusablaka bőséges, nem végtelen. Ha a modellt ezzel a határértékkel meghaladó bemenetekkel táplálja, az néma csonkításhoz és gyenge teljesítményhez vezet.
- A Base használata, amikor az Instruct megfelelő: A DBRX Base egy nyers, előre betanított modell, amelyet további, nagyszabású betanításra szántak. A legtöbb utasításkövető feladat esetében a DBRX Instruct-tal kell kezdeni, amelyet már erre a célra finomhangoltak.
- A képzési munka elszigetelése a projektkoordinációtól: Ha a kísérletek nyomon követése egy eszközben, a projektterv pedig egy másikban történik, akkor információs szigetek jönnek létre. Használjon integrált platformot, például a ClickUp-ot, hogy a technikai munkát és a projektkoordinációt szinkronban tartsa.
- A telepítés előtti értékelés elhanyagolása: Egy modell, amely jól teljesít a képzési adatokon, a valós világban látványosan kudarcot vallhat. Mindig ellenőrizze a finomhangolt modellt egy visszatartott tesztkészleten, mielőtt azt termelésbe állítaná.
- A finomhangolás komplexitásának figyelmen kívül hagyása: Mivel a DBRX egy Mixture-of-Experts modell, a standard finomhangolási szkriptekhez speciális könyvtárakra lehet szükség, például Megatron-LM vagy PyTorch FSDP, hogy kezelni tudják a paraméterek több GPU-n történő felosztását.
DBRX vs. más AI-edzőplatformok
Az AI-edzési platform kiválasztása alapvető kompromisszumot jelent: kontroll kontra kényelem. A saját fejlesztésű, kizárólag API-t használó modellek könnyen használhatók, de a gyártó ökoszisztémájához kötik Önt.
A DBRX-hez hasonló nyílt súlyozási modellek teljes ellenőrzést kínálnak, de több technikai szakértelmet és infrastruktúrát igényelnek. Ez a választás olyan érzést kelthet, hogy elakadt, és nem biztos benne, melyik út támogatja valójában hosszú távú céljait – ez egy olyan kihívás, amellyel sok csapat szembesül az AI bevezetése során.
Ez a táblázat bemutatja a legfontosabb különbségeket, hogy megalapozott döntést hozhasson.
| Súlyok | Nyitott (egyedi) | Saját fejlesztésű | Nyitott (egyedi) | Saját fejlesztésű |
| Finomhangolás | Teljes ellenőrzés | API-alapú | Teljes ellenőrzés | API-alapú |
| Saját hosztolás | Igen | Nem | Igen | Nem |
| Licenc | DB Open Model | OpenAI feltételek | Llama közösség | Antropikus kifejezések |
| Kontextus | 32K | 128K – 1M | 128K | 200 000 – 1 millió |
A DBRX a megfelelő választás, ha teljes ellenőrzést szeretne gyakorolni a modell felett, biztonsági vagy megfelelőségi okokból saját szerveren kell tárolnia, vagy rugalmas, engedékeny kereskedelmi licencet szeretne. Ha nincs dedikált GPU-infrastruktúrája, vagy a mélyreható testreszabásnál fontosabbnak tartja a gyors piacra lépést, akkor az API-alapú alternatívák lehetnek a megfelelőbbek.
Kezdje el az intelligens képzést a ClickUp segítségével
A DBRX egy vállalati szintű alapot biztosít az egyedi AI-alkalmazások fejlesztéséhez, olyan átláthatósággal és ellenőrzési lehetőséggel, amelyet a saját fejlesztésű modellek nem nyújtanak. Hatékony MoE architektúrája alacsonyan tartja a következtetés költségeit, nyitott kialakítása pedig megkönnyíti a finomhangolást. De a erős technológia csak a feladatok felét jelenti.
Az igazi siker a technikai munkád és a csapatod együttműködési munkafolyamatának összehangolásából származik. Az AI-modellek képzése csapatmunka, ezért elengedhetetlen a kísérletek, a dokumentáció és az érdekelt felekkel való kommunikáció összehangolása. Ha mindent egyetlen konvergált munkaterületre hozol, és csökkenteted a kontextus szétaprózódását, akkor jobb modelleket tudsz gyorsabban szállítani.
Kezdje el ingyenesen a ClickUp használatát, hogy egy munkaterületen koordinálhassa AI-képzési projektjeit. ✨
Gyakran ismételt kérdések
A képzést olyan szabványos ML eszközökkel figyelheti, mint a TensorBoard, a Weights & Biases vagy az MLflow. Ha a Databricks ökoszisztémán belül végez képzést, az MLflow natívan integrálva van a kísérletek zökkenőmentes nyomon követéséhez.
Igen, a DBRX integrálható a szabványos MLOps folyamatokba. A modell konténeresítésével olyan koordinációs platformok segítségével telepítheti, mint a Kubeflow vagy az egyedi CI/CD munkafolyamatok.
A DBRX Base egy alapvető, előre betanított modell, amely olyan csapatok számára készült, akik domain-specifikus folyamatos előzetes betanítást vagy mély architektúra-finomhangolást szeretnének végrehajtani. A DBRX Instruct egy finomhangolt változat, amely utasítások követésére van optimalizálva, így a legtöbb alkalmazásfejlesztés számára jobb kiindulási pontot jelent.
A fő különbség a kontroll. A DBRX teljes hozzáférést biztosít a modell súlyozásaihoz a mélyreható testreszabás és az önálló hosztolás érdekében, míg a GPT-4 csak API-szolgáltatás.
A DBRX modell súlyozások ingyenesen elérhetők a Databricks Open Model License alatt. Azonban Ön felelős a modell futtatásához vagy finomhangolásához szükséges számítási infrastruktúra költségeiért.