
Projekty trénování AI málokdy selžou na úrovni modelu. Problémy nastávají, když jsou experimenty, dokumentace a aktualizace pro zúčastněné strany roztříštěny do příliš mnoha nástrojů.
Tato příručka vás provede trénováním modelů pomocí Databricks DBRX – LLM, který je až dvakrát výpočetně efektivnější než jiné přední modely – a zároveň udržuje práci kolem něj organizovanou v ClickUp.
Od nastavení a doladění až po dokumentaci a aktualizace napříč týmy uvidíte, jak jediný sjednocený pracovní prostor pomáhá eliminovat rozptýlení kontextu a udržuje váš tým soustředěný na tvorbu, nikoli na hledání. 🛠
Co je DBRX?
DBRX je výkonný open-source model velkého jazyka (LLM) navržený speciálně pro trénování a inferenci modelů AI v podnicích. Protože se jedná o open-source model pod licencí Databricks Open Model License, má váš tým plný přístup k váhám a architektuře modelu, což vám umožňuje jej kontrolovat, upravovat a nasazovat podle vlastních potřeb.
Je k dispozici ve dvou variantách: DBRX Base pro hloubkové předběžné trénování a DBRX Instruct pro úkoly vyžadující okamžité plnění pokynů.
Architektura DBRX a design kombinace expertů
DBRX řeší úkoly pomocí architektury Mixture-of-Experts (MoE). Na rozdíl od tradičních velkých jazykových modelů, které pro každý jednotlivý výpočet využívají všechny své miliardy parametrů, DBRX aktivuje pro daný úkol pouze zlomek svých celkových parametrů (nejrelevantnější experty).
Představte si to jako tým specializovaných odborníků; místo toho, aby každý pracoval na všech problémech, systém inteligentně směruje každý úkol k nejvhodnějším parametrům.
To nejen zkracuje dobu odezvy, ale také poskytuje špičkový výkon a výstupy při současném významném snížení výpočetních nákladů.
Zde je stručný přehled jeho klíčových specifikací:
- Celkový počet parametrů: 132 miliard napříč všemi experty
- Aktivní parametry: 36B na jeden předávací průchod
- Počet expertů: celkem 16 (MoE Top-4 routing), z toho 4 aktivní pro daný token
- Okno kontextu: 32K tokenů
Specifikace trénovacích dat a tokenů DBRX
Výkon LLM je pouze tak dobrý, jak jsou data, na kterých je trénován. DBRX byl předem trénován na obrovském datovém souboru o velikosti 12 bilionů tokenů, který pečlivě sestavil tým Databricks pomocí svých pokročilých nástrojů pro zpracování dat. Právě proto dosáhl tak dobrých výsledků v průmyslových benchmarkech.
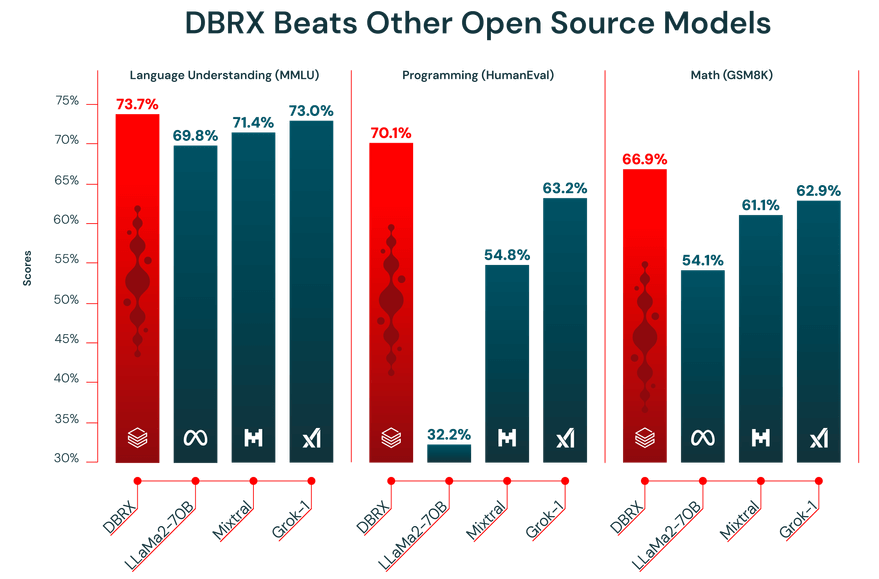
DBRX navíc nabízí kontextové okno s 32 000 tokeny. To je množství textu, které model může najednou zpracovat. Velké kontextové okno je velmi užitečné pro složité úkoly, jako je shrnování dlouhých zpráv, prohledávání rozsáhlých právních dokumentů nebo vytváření pokročilých systémů generování s rozšířeným vyhledáváním (RAG), protože umožňuje modelu zachovat kontext bez zkracování nebo zapomínání informací.
🎥 Podívejte se na toto video a zjistěte, jak může efektivní koordinace projektů transformovat váš pracovní postup při trénování AI a eliminovat potíže spojené s přepínáním mezi nesouvislými nástroji. 👇🏽
Jak přistupovat k DBRX a nastavit jej
DBRX nabízí dvě hlavní přístupové cesty, které obě poskytují plný přístup k váhám modelu za liberálních obchodních podmínek. Můžete použít Hugging Face pro maximální flexibilitu nebo k němu přistupovat přímo přes Databricks pro integrovanější zážitek.
Přístup k DBRX přes Hugging Face
Pro týmy, které si cení flexibility a již jsou zvyklé na ekosystém Hugging Face, je ideální cestou přístup k DBRX prostřednictvím Hubu. Umožňuje vám integrovat model do vašich stávajících pracovních postupů založených na transformátorech.
Jak začít:
- Vytvořte si účet Hugging Face nebo se přihlaste ke svému účtu.
- Přejděte na kartu modelu DBRX v Hubu a přijměte licenční podmínky.
- Nainstalujte knihovnu transformátorů spolu s nezbytnými závislostmi, jako je accelerate.
- Použijte třídu AutoModelForCausalLM ve svém skriptu Python k načtení modelu DBRX.
- Nakonfigurujte svůj inferenční pipeline a mějte na paměti, že DBRX vyžaduje pro efektivní provoz značnou paměť GPU (VRAM).
📖 Další informace: Jak nakonfigurovat teplotu LLM
Přístup k DBRX prostřednictvím Databricks
Pokud váš tým již používá Databricks pro datové inženýrství nebo strojové učení, nejjednodušší způsob je přístup k DBRX prostřednictvím této platformy. Eliminuje to potíže s nastavením a poskytuje vám všechny nástroje, které potřebujete pro MLOps, přímo tam, kde již pracujete.
Chcete-li začít, postupujte podle těchto kroků ve svém pracovním prostoru Databricks:
- Přejděte do sekce Model Garden nebo Mosaic AI.
- Vyberte si podle svých potřeb buď DBRX Base, nebo DBRX Instruct.
- Nakonfigurujte koncový bod pro přístup k API nebo nastavte prostředí notebooku pro interaktivní použití.
- Začněte testovat inferenci pomocí vzorových výzev, abyste se ujistili, že vše funguje správně, než rozšíříte trénink nebo nasazení svého AI modelu.
Tento přístup vám poskytuje plynulý přístup k nástrojům, jako je MLflow pro sledování experimentů a Unity Catalog pro správu modelů.
📮 ClickUp Insight: Průměrný profesionál stráví více než 30 minut denně hledáním informací souvisejících s prací – to je více než 120 hodin ročně ztracených prohledáváním e-mailů, vláken Slacku a roztroušených souborů.
Inteligentní AI asistent zabudovaný do vašeho pracovního prostoru to může změnit. Představujeme ClickUp Brain.
Poskytuje okamžité informace a odpovědi tím, že během několika sekund vyhledá správné dokumenty, konverzace a podrobnosti úkolů – takže můžete přestat hledat a začít pracovat.
Jak doladit DBRX a trénovat vlastní modely AI
Hotový model, bez ohledu na to, jak výkonný je, nikdy nepochopí jedinečné nuance vašeho podnikání. Protože DBRX je open source, můžete jej doladit a vytvořit vlastní model, který bude mluvit jazykem vaší společnosti nebo provádět konkrétní úkoly, které od něj očekáváte.
Zde jsou tři běžné způsoby, jak toho dosáhnout:
1. Vyladění DBRX pomocí datových sad Hugging Face
Pro týmy, které právě začínají nebo pracují na běžných úkolech, jsou veřejně dostupné datové sady z Hugging Face Hub skvělým zdrojem. Jsou předformátované a snadno se načítají, což znamená, že nemusíte trávit hodiny přípravou dat.
Proces je poměrně jednoduchý:
- Najděte na Hubu datový soubor, který odpovídá vašemu úkolu (např. dodržování pokynů, shrnutí).
- Načtěte jej pomocí knihovny datových sad.
- Zajistěte, aby data byla formátována do párů instrukce-odpověď.
- Nakonfigurujte svůj tréninkový skript pomocí hyperparametrů, jako je rychlost učení a velikost dávky.
- Spusťte tréninkovou úlohu a nezapomeňte pravidelně ukládat kontrolní body.
- Vyhodnoťte doladěný model na vyhrazené validační sadě, abyste změřili zlepšení.
2. Vyladění DBRX pomocí lokálních datových sad
Nejlepších výsledků obvykle dosáhnete jemným doladěním pomocí vlastních proprietárních dat. To vám umožní naučit model specifickou terminologii, styl a znalosti vaší společnosti. Mějte však na paměti, že se to vyplatí pouze v případě, že jsou vaše data čistá, dobře připravená a mají dostatečný objem.
Postupujte podle těchto kroků a připravte si interní data:
- Sběr dat: Shromažďujte vysoce kvalitní příklady z vašich interních wiki, dokumentů a databází.
- Převod formátu: Strukturovejte svá data do konzistentního formátu instrukce-odpověď, často jako řádky JSON.
- Filtrování kvality: Odstraňte všechny příklady nízké kvality, duplicitní nebo irelevantní příklady.
- Rozdělení validace: Vyhraďte malou část svých dat (obvykle 10–15 %) k vyhodnocení výkonu modelu.
- Kontrola ochrany osobních údajů: Odstraňte nebo zamaskujte veškeré osobní identifikační údaje (PII) nebo citlivá data.
3. Vyladění DBRX pomocí StreamingDataset
Pokud je váš datový soubor příliš velký, aby se vešel do paměti vašeho počítače, nemusíte se obávat, můžete použít knihovnu Streaming Dataset od Databricks. Ta vám umožní streamovat data přímo z cloudového úložiště během trénování modelu, místo aby se všechna data najednou načítala do paměti.
Zde je návod, jak na to:
- Příprava dat: Vyčistěte a strukturovejte svá trénovací data a poté je uložte v streamovatelném formátu, jako je JSONL nebo CSV, do cloudového úložiště.
- Převod formátu streamování: Převedete svůj datový soubor do formátu vhodného pro streamování, jako je Mosaic Data Shard (MDS), aby jej bylo možné během trénování efektivně číst.
- Nastavení trénovacího loaderu: Nakonfigurujte svůj trénovací loader tak, aby odkazoval na vzdálený datový soubor, a definujte lokální cache pro dočasné ukládání dat.
- Inicializace modelu: Spusťte proces jemného doladění DBRX pomocí tréninkového frameworku, který podporuje StreamingDataset, jako je LLM Foundry.
- Školení založené na streamování: Spusťte školicí úlohu, zatímco jsou data během školení streamována v dávkách, namísto jejich úplného načtení do paměti.
- Kontrola a obnovení: Pokračujte v tréninku plynule, pokud dojde k přerušení běhu, bez duplikování nebo přeskočení dat.
- Hodnocení a nasazení: Ověřte výkon vyladěného modelu a nasadit jej pomocí svého preferovaného nastavení servisu nebo inference.
💡Tip pro profesionály: Místo toho, abyste vytvářeli plán tréninku DBRX od nuly, začněte s šablonou plánu projektů umělé inteligence a strojového učení od ClickUp a přizpůsobte ji potřebám svého týmu. Poskytuje jasnou strukturu pro plánování datových sad, fází tréninku, hodnocení a nasazení, takže se můžete soustředit na organizaci své práce, místo na strukturování pracovního postupu.
Příklady použití DBRX pro trénování modelů AI
Mít výkonný model je jedna věc, ale vědět přesně, kde vyniká, je věc druhá.
Pokud nemáte jasnou představu o silných stránkách modelu, snadno můžete ztrácet čas a zdroje snahou o jeho použití tam, kde prostě není vhodný. To vede k podprůměrným výsledkům a frustraci.
Díky své jedinečné architektuře a trénovacím datům je DBRX mimořádně vhodný pro několik klíčových podnikových použití. Znalost těchto silných stránek vám pomůže přizpůsobit model vašim obchodním cílům a maximalizovat návratnost investic.
Generování textu a tvorba obsahu
DBRX Instruct je přesně vyladěn pro následování pokynů a generování vysoce kvalitního textu. Díky tomu je výkonným nástrojem pro automatizaci široké škály úkolů souvisejících s obsahem. Jeho velké kontextové okno je významnou výhodou, která mu umožňuje zpracovávat dlouhé dokumenty bez ztráty souvislosti.
Můžete jej použít pro:
- Technická dokumentace: Vytvářejte a vylepšujte produktové manuály, reference API a uživatelské příručky.
- Marketingový obsah: Návrhy blogových příspěvků, e-mailových zpravodajů a aktualizací na sociálních médiích
- Generování zpráv: Shrňte komplexní zjištění z dat a vytvořte stručné souhrny pro vedení.
- Překlad a lokalizace: Přizpůsobte stávající obsah novým trhům a publiku.
Úkoly generování kódu a ladění
Významná část trénovacích dat DBRX obsahovala kód, což z něj činí schopnou podporu LLM pro vývojáře. Může pomoci urychlit vývojové cykly automatizací opakujících se úkolů kódování a asistencí při řešení složitých problémů.
Zde je několik způsobů, jak to může váš technický tým využít:
- Doplňování kódu: Automaticky generujte těla funkcí z komentářů nebo docstringů.
- Detekce chyb: Analyzujte úryvky kódu a identifikujte potenciální chyby nebo logické nedostatky.
- Vysvětlení kódu: Přeložte složité algoritmy nebo starší kód do srozumitelné angličtiny.
- Generování testů: Vytvářejte jednotkové testy na základě podpisu funkce a očekávaného chování.
RAG a aplikace s dlouhým kontextem
Retrieval-Augmented Generation (RAG) je výkonná technika, která zakládá odpovědi modelu na soukromých datech vaší společnosti. Systémy RAG však často bojují s modely, které mají malá kontextová okna, což nutí k agresivnímu rozdělování dat, při kterém může dojít ke ztrátě důležitého kontextu. Kontextové okno DBRX o velikosti 32K z něj činí vynikající základ pro robustní aplikace RAG.
To vám umožní vytvářet výkonné interní nástroje, jako například:
- Podnikové vyhledávání: Vytvořte chatbota, který odpovídá na dotazy zaměstnanců pomocí vaší interní znalostní báze.
- Zákaznická podpora: Vytvořte agenta, který generuje odpovědi podpory založené na dokumentaci k vašemu produktu.
- Výzkumná pomoc: Vyvinout nástroj, který dokáže syntetizovat informace ze stovek stránek výzkumných prací.
- Kontrola souladu: Automaticky ověřujte marketingové texty podle interních pokynů značky nebo regulačních dokumentů.
Jak integrovat trénink DBRX do pracovního postupu vašeho týmu
Úspěšný projekt trénování modelů AI není jen o kódu a výpočtech. Jedná se o společné úsilí, do kterého jsou zapojeni inženýři ML, datoví vědci, produktoví manažeři a zainteresované strany.
Když je tato spolupráce rozptýlena mezi notebooky Jupyter, kanály Slack a samostatnými nástroji pro správu projektů, vytváříte kontextovou roztříštěnost, situaci, kdy jsou důležité informace o projektu rozptýleny mezi příliš mnoha nástroji.
ClickUp to řeší. Místo toho, abyste museli používat několik nástrojů, získáte jeden konvergovaný pracovní prostor AI, kde se spojuje projektové řízení, dokumentace a komunikace – takže vaše experimenty zůstávají propojené od plánování přes provedení až po vyhodnocení.
Nikdy neztraťte přehled o experimentech a pokroku.
Při provádění více experimentů není nejtěžší částí trénování modelu, ale sledování toho, co se během procesu změnilo. Která verze datového souboru byla použita, jaká rychlost učení fungovala nejlépe nebo který běh byl odeslán?
ClickUp vám tento proces velmi usnadní. V ClickUp Tasks můžete sledovat každý tréninkový běh samostatně a v rámci úkolů můžete pomocí vlastních polí zaznamenávat:
- Verze datového souboru
- Hyperparametry
- Varianta modelu (DBRX Base vs DBRX Instruct)
- Stav tréninku (ve frontě, probíhá, vyhodnocuje se, nasazeno)
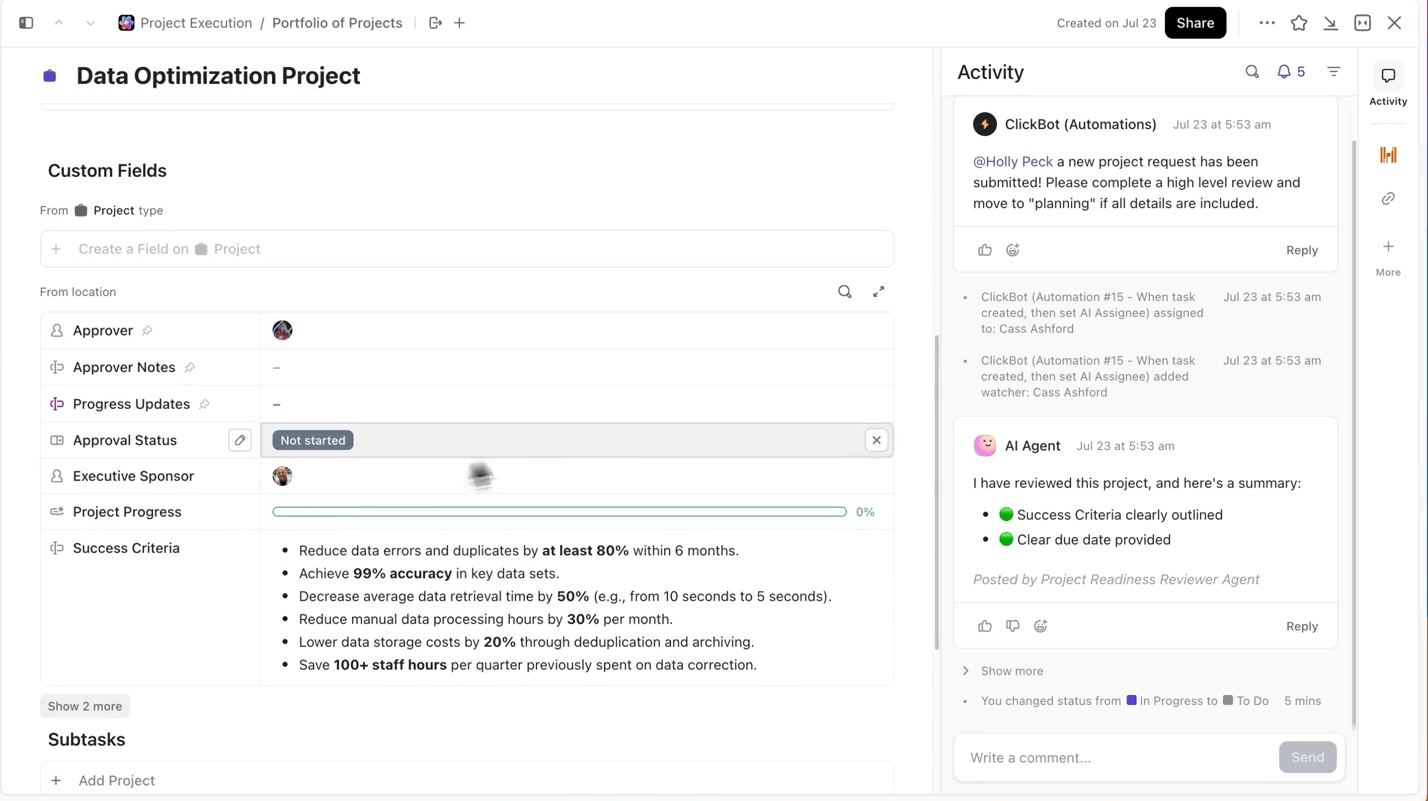
Díky tomu je každý zdokumentovaný experiment vyhledatelný, snadno porovnatelný s ostatními a reprodukovatelný.
Udržujte dokumentaci modelů spojenou s prací
Nemusíte přeskakovat mezi notebooky Jupyter, soubory README nebo vlákny Slack, abyste pochopili kontext úkolu experimentu.
S ClickUp Docs můžete udržovat architekturu modelu, skripty pro přípravu dat nebo metriky hodnocení organizované a přístupné tím, že je zdokumentujete v prohledávatelném dokumentu, který odkazuje přímo na experimentální úkoly, ze kterých pocházejí.

💡Tip pro profesionály: V ClickUp Docs udržujte aktuální projektový brief, který podrobně popisuje každé rozhodnutí, od architektury po nasazení, aby se noví členové týmu mohli vždy rychle seznámit s podrobnostmi projektu, aniž by museli prohledávat staré vlákna.
Poskytněte zainteresovaným stranám přehled v reálném čase
Dashboardy ClickUp zobrazují průběh experimentů a pracovní vytížení týmu v reálném čase. I
Místo ručního sestavování aktualizací nebo zasílání e-mailů se dashboardy aktualizují automaticky na základě dat ve vašich úkolech. Zainteresované strany tak mohou kdykoli zkontrolovat, jak se věci mají, a nemusí vás rušit otázkami typu „jaký je stav?“.
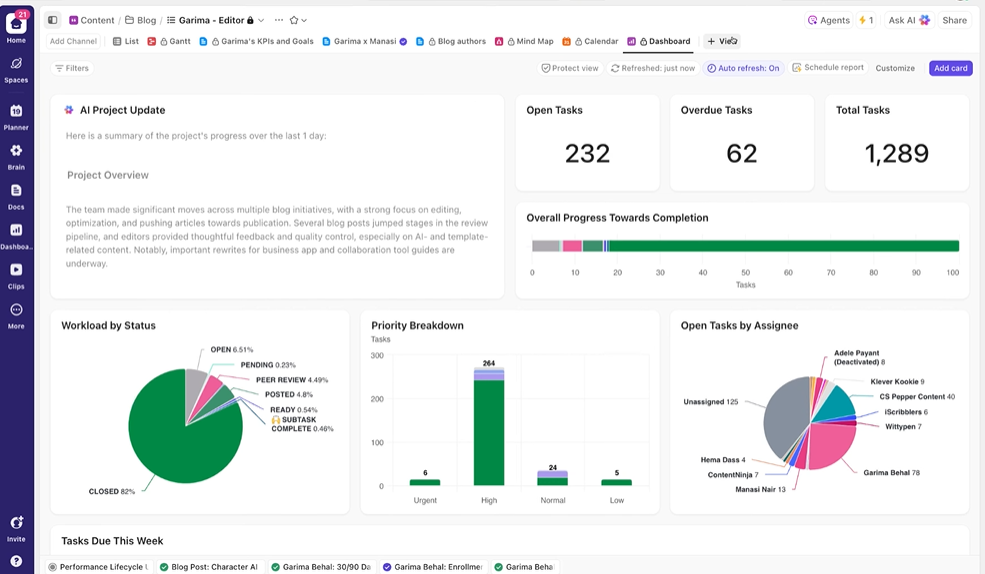
Tímto způsobem se můžete soustředit na provádění experimentů, místo abyste je museli neustále ručně vykazovat.
Proměňte AI ve svého chytrého pomocníka při projektech
Nemusíte ručně prohledávat týdny trénovacích dat, abyste získali souhrn dosavadních experimentů. Stačí zmínit @Brain v jakémkoli komentáři k úkolu a ClickUp Brain vám poskytne potřebnou pomoc s úplným kontextem vašich minulých a probíhajících projektů.
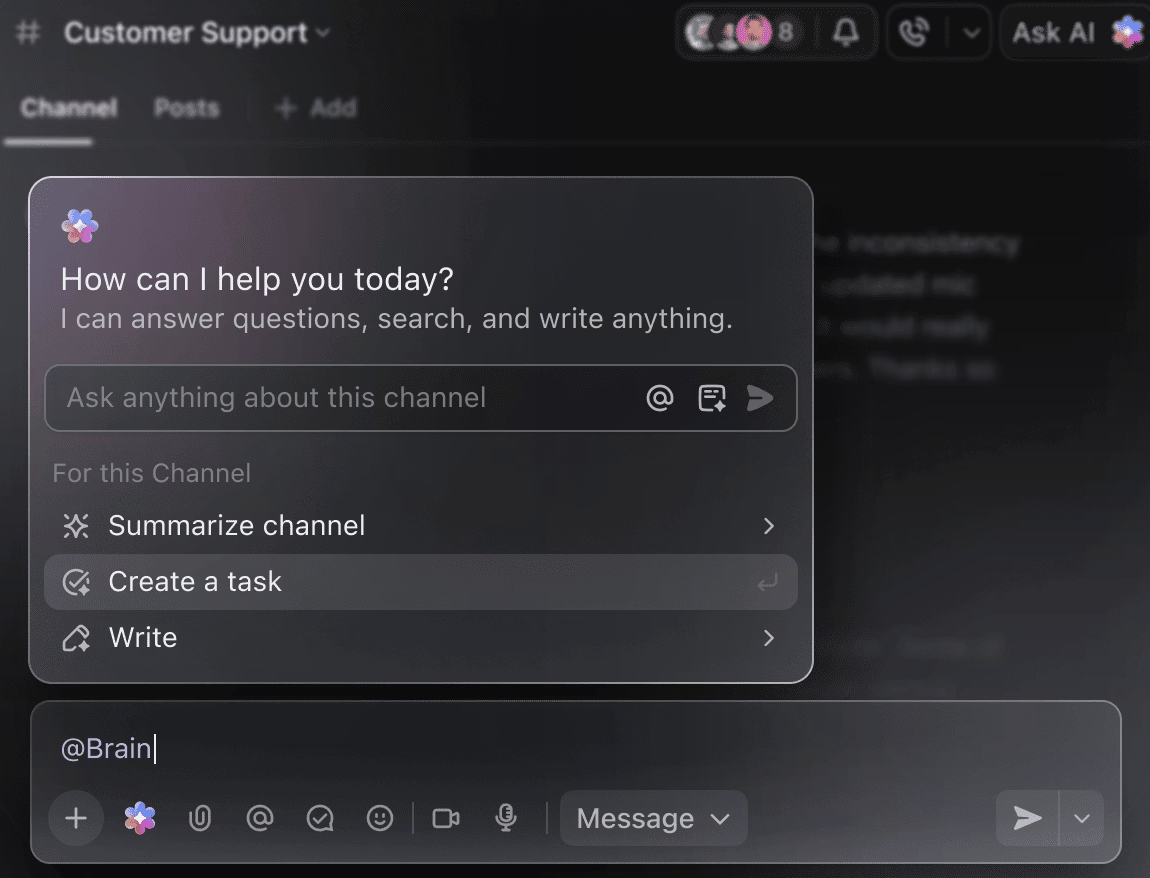
Můžete požádat Brain, aby „shrnul experimenty z minulého týdne do 5 bodů“ nebo „vytvořil dokument s nejnovějšími výsledky hyperparametrů“, a okamžitě získáte propracovaný výstup.
🧠 Výhoda ClickUp: Super agenti ClickUp jdou ještě dál – mohou automatizovat celé pracovní postupy na základě vámi definovaných spouštěčů, nejen odpovídat na vaše otázky. S pomocí super agentů můžete automaticky vytvořit nový úkol trénování DBRX pokaždé, když je nahrán datový soubor, informovat svůj tým a propojit relevantní dokumenty, když trénink skončí nebo dosáhne kontrolního bodu, a generovat týdenní souhrn pokroku a zaslat jej zainteresovaným stranám, aniž byste museli hnout prstem.
Časté chyby, kterým je třeba se vyhnout
Zahájení tréninkového projektu DBRX je vzrušující, ale několik běžných úskalí může narušit váš pokrok. Vyhnete-li se těmto chybám, ušetříte čas, peníze a spoustu frustrace.
- Podcenění hardwarových požadavků: DBRX je výkonný, ale také velký. Pokus o jeho spuštění na nedostatečném hardwaru povede k chybám nedostatku paměti a selhání trénovacích úloh. Mějte na paměti, že DBRX (132B) vyžaduje alespoň 264 GB VRAM pro 16bitovou inferenci, nebo přibližně 70 GB–80 GB při použití 4bitové kvantizace.
- Vynechání kontroly kvality dat: Co je špatné na vstupu, je špatné i na výstupu. Dolaďování na neuspořádaném datovém souboru nízké kvality naučí model pouze produkovat neuspořádané výstupy nízké kvality.
- Ignorování omezení délky kontextu: Ačkoli je kontextové okno DBRX o velikosti 32 kB velkorysé, není nekonečné. Zadání vstupů do modelu, které překračují tento limit, bude mít za následek tiché zkrácení a špatný výkon.
- Použití Base, když je vhodné použít Instruct: DBRX Base je surový, předem trénovaný model určený pro další trénink ve velkém měřítku. Pro většinu úkolů, které vyžadují dodržování pokynů, byste měli začít s DBRX Instruct, který již byl pro tento účel doladěn.
- Oddělení tréninkové práce od koordinace projektu: Když sledujete experimenty v jednom nástroji a projektový plán v jiném, vytváříte informační silosy. Použijte integrovanou platformu, jako je ClickUp, abyste synchronizovali technickou práci a koordinaci projektu.
- Zanedbání evaluace před nasazením: Model, který funguje dobře na vašich trénovacích datech, může v reálném světě selhat. Vždy ověřte svůj vyladěný model na testovací sadě před jeho nasazením do produkce.
- Přehlížení složitosti jemného doladění: Protože DBRX je model typu Mixture-of-Experts, standardní skripty pro jemné doladění mohou vyžadovat specializované knihovny, jako jsou Megatron-LM nebo PyTorch FSDP, aby zvládly rozdělení parametrů mezi více GPU.
DBRX vs. jiné platformy pro trénování AI
Rozhodování o platformě pro trénování AI zahrnuje zásadní kompromis: kontrola vs. pohodlí. Proprietární modely pouze s API jsou snadno použitelné, ale uzamknou vás do ekosystému dodavatele.
Otevřené modely váhových koeficientů, jako je DBRX, nabízejí úplnou kontrolu, ale vyžadují více technických znalostí a infrastruktury. Tato volba vás může uvést do slepé uličky, kdy si nebudete jisti, která cesta skutečně podporuje vaše dlouhodobé cíle – což je výzva, které čelí mnoho týmů při zavádění AI.
Tato tabulka rozebírá klíčové rozdíly, aby vám pomohla učinit informované rozhodnutí.
| Váhy | Otevřít (vlastní) | Vlastní | Otevřít (vlastní) | Vlastní |
| Dolaďování | Plná kontrola | Na bázi API | Plná kontrola | Na bázi API |
| Vlastní hosting | Ano | Ne | Ano | Ne |
| Licence | DB Open Model | Podmínky OpenAI | Komunita Llama | Antropické termíny |
| Kontext | 32K | 128K – 1M | 128K | 200 000 – 1 milion |
DBRX je správnou volbou, pokud potřebujete plnou kontrolu nad modelem, musíte z důvodu bezpečnosti nebo dodržování předpisů používat vlastní hosting nebo chcete flexibilitu liberální komerční licence. Pokud nemáte vyhrazenou infrastrukturu GPU nebo upřednostňujete rychlost uvedení na trh před hlubokou přizpůsobitelností, mohou být vhodnější alternativy založené na API.
Začněte trénovat chytřeji s ClickUp
DBRX vám poskytuje podnikovou základnu pro vytváření vlastních AI aplikací s transparentností a kontrolou, kterou vám proprietární modely neposkytují. Jeho efektivní architektura MoE udržuje nízké náklady na inferenci a jeho otevřený design usnadňuje jemné doladění. Silná technologie je však pouze polovinou rovnice.
Skutečný úspěch pramení ze sladění vaší technické práce s kolaborativním pracovním postupem vašeho týmu. Trénování modelů AI je týmová práce a synchronizace experimentů, dokumentace a komunikace se zainteresovanými stranami je zásadní. Když vše sjednotíte do jednoho konvergovaného pracovního prostoru a omezíte rozptýlení kontextu, můžete dodávat lepší modely rychleji.
Začněte zdarma s ClickUp a koordinujte své projekty trénování AI v jednom pracovním prostoru. ✨
Často kladené otázky
Trénink můžete sledovat pomocí standardních nástrojů ML, jako jsou TensorBoard, Weights & Biases nebo MLflow. Pokud trénujete v ekosystému Databricks, MLflow je nativně integrován pro plynulé sledování experimentů.
Ano, DBRX lze integrovat do standardních MLOps pipeline. Kontejnerizací modelu jej můžete nasadit pomocí orchestračních platforem, jako je Kubeflow, nebo vlastních CI/CD workflow.
DBRX Base je základní předem trénovaný model určený pro týmy, které chtějí provádět doménově specifické pokračující předběžné trénování nebo hluboké architektonické doladění. DBRX Instruct je doladěná verze optimalizovaná pro následování pokynů, což z něj činí lepší výchozí bod pro většinu vývoje aplikací.
Hlavním rozdílem je kontrola. DBRX vám poskytuje plný přístup k váhám modelu pro hluboké přizpůsobení a vlastní hostování, zatímco GPT-4 je služba pouze s rozhraním API.
Váhy modelu DBRX jsou k dispozici zdarma v rámci licence Databricks Open Model License. Jste však odpovědní za náklady na výpočetní infrastrukturu potřebnou k provozu nebo doladění modelu.