

Jsou 3 hodiny ráno.
Probudí vás pronikavý alarm.
Vyskočíte ze židle a zamíříte k zářící obrazovce počítače. Kritický systém nefunguje. Propukne panika. Nejedná se o scénu ze sci-fi thrilleru, ale o noční můru každého IT profesionála.
Ale je to také realita. Když se digitální svět zastaví, tlak je obrovský.
Právě v takových situacích se správa incidentů stává záchranným lanem.
Řízení incidentů je klíčem k rychlému řešení a odstraňování přerušení projektů. Díky efektivnímu řízení těchto přerušení se můžete více soustředit na dosahování výsledků a efektivní dokončení projektu.
V tomto článku se podíváme na proces správy incidentů a podělíme se o osvědčené postupy, které vám pomohou zavést robustní plán pro mimořádné situace. Díky tomu budete schopni efektivně řešit jakékoli budoucí incidenty v rámci projektů.
Porozumění řízení incidentů
Incidenty jsou poruchy nebo potenciální hrozby, které mají vliv na kvalitu služeb. Například selhání podnikové aplikace nebo pomalý webový server, které způsobují problémy s produktivitou, lze považovat za incidenty. Tyto události mohou mít různý rozsah, od drobných poruch ovlivňujících několik uživatelů až po velké výpadky ovlivňující globální služby.
Řízení incidentů je proces identifikace, prioritizace a řešení IT problémů s cílem minimalizovat narušení obchodních operací a zároveň zavést opatření k prevenci jejich opakovaného výskytu. Tento proces proaktivní prevence incidentů je pro každou organizaci zásadní, protože výpadky služeb mohou vést k významným obchodním ztrátám. Efektivní řízení incidentů umožňuje týmům rychle prioritizovat a řešit problémy, čímž zajišťuje lepší kontinuitu služeb.
Při řešení incidentů potřebují týmy dobře definovaný plán, který jim pomůže:
- Reagujte rychle , abyste minimalizovali prostoje
- Komunikujte efektivně se zákazníky, zainteresovanými stranami, vlastníky služeb a dalšími relevantními stranami.
- Plynule spolupracujte, abyste urychlili řešení problémů a odstranili překážky bránící jejich vyřešení.
- Neustále se zlepšujte tím, že se poučíte z incidentů a tyto poznatky využijete ke zlepšení kvality služeb a zdokonalení procesů.
V tomto rámci je také nezbytné vědět , jak napsat zprávu o incidentu. Podrobné zprávy o incidentech usnadňují důkladnou analýzu, identifikují příčiny a pomáhají vyvinout preventivní strategie.
Vztah mezi řízením incidentů, ITSM a DevOps
Řízení incidentů je základní součástí správy IT služeb (ITSM) a zajišťuje dostupnost a spolehlivost IT služeb. DevOps meanwhile integruje vývojové a provozní týmy s cílem zlepšit spolupráci a efektivitu.
Sladění správy incidentů s principy projektového řízení DevOps může organizacím pomoci reagovat na incidenty rychle a efektivně. Toto sladění podporuje neustálé zlepšování, rychlejší obnovu po incidentech a lepší poskytování služeb.
Porozumění procesům správy incidentů
Efektivní proces správy incidentů umožňuje IT týmům efektivně vyšetřovat, dokumentovat a řešit přerušení nebo výpadky služeb.
Různé společnosti často používají různé typy procesů správy incidentů přizpůsobené jejich konkrétním potřebám. Jelikož neexistuje univerzální přístup, najdete v různých organizacích různé metodiky.
Některé týmy se drží tradičních procesů správy incidentů v IT, jako jsou ty popsané v certifikacích Information Technology Infrastructure Library (ITIL). Jiné dávají přednost přístupu orientovanému spíše na Site Reliability Engineering (SRE) nebo DevOps.
Pracovní postup správy incidentů ITIL se zaměřuje na snížení prostojů a zmírnění dopadu incidentů na produktivitu zaměstnanců. Pomocí šablon hlášení incidentů mohou týmy zavést opakovatelný pracovní postup pro zaznamenávání, diagnostiku a řešení incidentů a zároveň vést komplexní záznamy o svých činnostech.
Rámec ITIL je převážně používán IT týmy, které spravují služby v rámci podniků. Tyto týmy často přizpůsobují rozsáhlé pokrytí incidentů a procesů ITIL tak, aby vyhovovalo jejich potřebám.
ITIL je obzvláště přínosný pro vytváření kultury proaktivního řešení problémů. Jeho strukturované procesy pomáhají týmům důsledně sledovat incidenty a opatření, zlepšují reporting a analýzu, což v konečném důsledku vede k robustnějším službám a efektivnějším týmům.
Umělá inteligence a strojové učení v řízení incidentů
Integrace umělé inteligence a strojového učení do správy incidentů mění způsob, jakým týmy incidenty řeší. Nástroje založené na umělé inteligenci mohou analyzovat obrovské množství dat a předvídat potenciální incidenty ještě předtím, než k nim dojde, což umožňuje přijmout preventivní opatření.
Algoritmy strojového učení dokážou identifikovat vzorce a anomálie, které lidským analytikům mohou uniknout, a poskytují tak hlubší vhled do příčin a možných řešení. Tyto technologie mohou také automatizovat rutinní úkoly, jako je zaznamenávání incidentů a počáteční diagnostika, čímž uvolňují lidské zdroje pro řešení složitějších problémů.
Vysoká dostupnost a prostoje v řízení incidentů
Pro efektivní správu incidentů je zásadní minimalizovat prostoje. Vysoká dostupnost zajišťuje, že systémy jsou neustále funkční a přístupné, čímž se minimalizuje riziko přerušení služeb. K dosažení vysoké dostupnosti se využívá redundance, mechanismy převzetí služeb při selhání a vyvažování zátěže.
Snížení prostojů je zásadní pro udržení produktivity a spokojenosti zákazníků. Procesy správy incidentů musí zahrnovat robustní plány pro rychlou reakci a obnovení, aby se minimalizovala doba trvání a dopad výpadků.
Proces správy IT incidentů v detailu
Řízení incidentů zahrnuje efektivní identifikaci, zaznamenávání, kategorizaci, stanovení priorit a řešení incidentů.
Porozumění těmto krokům pomáhá zajistit systematický přístup k řízení incidentů, minimalizovat prostoje a předcházet budoucím výskytům.
Kroky v procesu správy IT incidentů
1. Identifikujte a zaznamenejte incident
Incidenty mohou pocházet z různých zdrojů, včetně zaměstnanců, zákazníků, dodavatelů nebo monitorovacích systémů. Prvním krokem je identifikace a zaznamenání incidentu. Tyto záznamy, často označované jako incidentové tikety, obvykle obsahují:
- Jméno osoby, která incident nahlásila
- Datum a čas nahlášení incidentu
- Popis incidentu s podrobným uvedením, co nefunguje nebo je mimo provoz.
- Pro účely sledování je přiděleno jedinečné identifikační číslo.
2. Kategorizujte incident
Je velmi důležité přiřadit každé události logickou a intuitivní kategorii (a v případě potřeby i podkategorii). Tato kategorizace pomáhá při analýze dat z hlediska trendů a vzorců, což je nezbytné pro efektivní správu problémů a prevenci budoucích událostí.
3. Stanovte priority incidentu
Každá incident musí být prioritizován na základě jeho dopadu na podnikání, počtu dotčených osob, relevantních SLA a potenciálních finančních, bezpečnostních a compliance dopadů.
Odpovědné týmy určují relativní prioritu incidentu porovnáním s ostatními otevřenými incidenty. Určení úrovně závažnosti a priority předem je osvědčeným postupem, který umožňuje manažerům incidentů rychle posoudit prioritu.
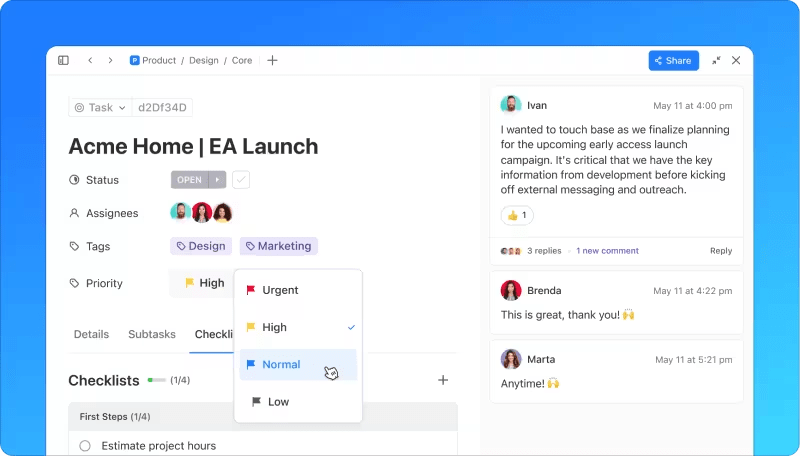
4. Reagujte na incident
Fáze reakce zahrnuje několik klíčových kroků:
- Počáteční diagnostika: V ideálním případě incident diagnostikuje a vyřeší tým první linie podpory. Pokud to není možné, zaznamená všechny relevantní informace a předá je týmu další úrovně.
- Eskalace: Následující tým pokračuje v diagnostickém procesu. Pokud není schopen incident vyřešit, eskaluje jej.
- Komunikace: Pravidelné aktualizace jsou sdíleny s dotčenými interními a externími zainteresovanými stranami.
- Vyšetřování a diagnostika: Tato fáze pokračuje, dokud není identifikována povaha incidentu. Týmy mohou přizvat externí zdroje nebo členy z jiných oddělení, aby pomohli s řešením.
- Řešení a obnovení: Po diagnostice provede tým nezbytné kroky k vyřešení incidentu. Obnovení zahrnuje čas potřebný k úplnému obnovení provozu, protože některé opravy, jako například opravy chyb, mohou vyžadovat testování a nasazení i po vyřešení.
- Uzavření: Pokud byla incident eskalován, je vrácen zpět na servisní středisko k uzavření. Incidenty mohou uzavírat pouze zaměstnanci servisního střediska, což zajišťuje kvalitu a spokojenost zákazníků.
Řízení incidentů pro týmy DevOps a SRE
Přístupy DevOps a SRE si získaly obrovskou popularitu, zejména s rozvojem nepřetržitě dostupných cloudových služeb, globálně přístupných webových aplikací, mikroslužeb a řešení typu software jako služba (SaaS).
Moderní software, který je nezbytný pro osobní i profesionální použití, je málokdy hostován na lokálním serveru. Místo toho jsou tyto aplikace obvykle nasazeny v datových centrech, kde slouží tisícům nebo milionům uživatelů po celém světě. Agilita a rychlost jsou pro týmy odpovědné za údržbu těchto služeb zásadní. Jakékoli výpadky mohou mít dalekosáhlé důsledky a ovlivnit současně řadu organizací.
Filozofie „vy to vytvoříte, vy to provozujete“ nabízí agilním týmům potřebnou flexibilitu. Může však také zamlžit hranice odpovědnosti. Zatímco týmy DevOps mohou prosperovat s méně rigidními vývojovými procesy, je nezbytné standardizovat základní postupy správy incidentů:
Sdílené pohotovostní povinnosti
Na rozdíl od tradičních modelů, kde jsou konkrétní členové týmu určeni jako odborníci v pohotovosti, týmy DevOps obvykle používají rotační pohotovostní rozvrh. Tento přístup zajišťuje, že všichni členové týmu jsou odpovědní za reakci na incidenty, včetně těch, které se mohou vyskytnout mimo běžnou pracovní dobu.
Znalost vede k řešení
Ústředním bodem filozofie DevOps je přesvědčení, že inženýři, kteří službu vyvinuli, jsou nejlépe připraveni řešit problémy, když nastanou. Tento princip zdůrazňuje mentalitu „vy to vytvoříte, vy to provozujete“, kdy se výpadky a narušení řeší ti, kteří nejlépe znají architekturu a složitost služby.
Rychlost a odpovědnost
Týmy DevOps musí rychle vytvářet a nasazovat software. Tato rychlost však s sebou nese i větší odpovědnost. Vědomí, že budou muset řešit incidenty, motivuje inženýry k vytváření vysoce kvalitního a spolehlivého kódu.
Analýza příčin (RCA) je také nezbytná při řízení incidentů v DevOps. RCA zahrnuje identifikaci základních příčin incidentů, což týmům umožňuje implementovat praktická řešení a zabránit jejich opakování.
Jedná se o proaktivní přístup, který řeší okamžité problémy a posiluje celkový systém, čímž snižuje pravděpodobnost budoucích závažných incidentů a zvyšuje odolnost služeb.
Díky udržování plynulého a soudržného toku v postupech správy incidentů mohou týmy DevOps vyvážit flexibilitu a strukturu. Tím je zajištěno, že jsou dobře připraveny na rychlé a efektivní řešení incidentů, což vede k spolehlivějším a robustnějším softwarovým službám.
Role v řízení incidentů
Ačkoli organizace mohou přizpůsobovat role a odpovědnosti podle svých konkrétních potřeb, níže uvádíme některé z nejčastějších rolí v týmech pro správu IT incidentů:
- Koncový uživatel/žadatel: Jedná se obvykle o osobu, která zaznamenala přerušení služby a je odpovědná za zahájení procesu řízení incidentů podáním incidentového ticketu.
- Servisní středisko úrovně 1: Servisní středisko úrovně 1 je prvním kontaktním místem pro žadatele. Technici řeší základní problémy a požadavky. Jejich odborné znalosti pokrývají běžné problémy, jako je resetování hesel a problémy s připojením, například problémy s Wi-Fi.
- Servisní středisko úrovně 2: Technici na této úrovni mají pokročilejší dovednosti a znalosti než technici úrovně 1. Řeší složitější problémy a eskalace z úrovně 1. Jejich úkolem je řešit složité technické problémy a zajistit efektivní řešení incidentů.
- Servisní středisko úrovně 3 a vyšší: Tato úroveň zahrnuje specialisty s hlubokými znalostmi v konkrétních oblastech IT infrastruktury, jako je údržba hardwaru nebo podpora serverů.
- Správce incidentů: Správce incidentů dohlíží na proces správy incidentů, hodnotí jeho účinnost, navrhuje zlepšení a zajišťuje dodržování stanovených postupů.
- Vlastník procesu: Vlastník procesu dohlíží na proces správy incidentů a zdokonaluje jej. Analyzuje, upravuje a vylepšuje proces, aby zajistil jeho soulad s cíli organizace a optimální podporu úsilí v oblasti správy incidentů.
Tyto role společně přispívají k dobře strukturovanému a efektivnímu procesu identifikace a řízení incidentů, zajišťují rychlé a účinné řešení incidentů a zároveň neustále zlepšují přístup.
Přečtěte si také: Jak napsat dobrý report o chybě (s příklady a šablonami)
Nástroje a zdroje pro efektivní správu incidentů
Využití správných nástrojů a zdrojů pro správu incidentů může výrazně zvýšit efektivitu a účinnost procesu správy incidentů.
Webové prohlížeče, zejména Google Chrome, hrají klíčovou roli ve správě incidentů. Díky své univerzálnosti a kompatibilitě s různými webovými softwary pro správu incidentů je Chrome nepostradatelným nástrojem pro IT týmy. Jeho rozsáhlá knihovna rozšíření, jako jsou vývojářské nástroje, nástroje pro sledování chyb a monitory výkonu, umožňuje diagnostiku a řešení problémů v reálném čase.
Kromě toho získávání artefaktů, jako jsou data z mezipaměti, historie, stažené soubory atd., pomocí forenzní analýzy prohlížeče pomáhá týmům identifikovat možné zdroje virových útoků a škodlivého kódu.
Chrome se také hladce integruje s ClickUp, vysoce hodnoceným softwarem pro produktivitu a správu incidentů, který používají týmy v malých i velkých společnostech.
Zde jsou některé z významných výhod používání ClickUp pro správu incidentů:
1. Centralizované sledování incidentů
ClickUp slučuje všechny informace související s incidenty do jedné platformy. Tento centralizovaný přístup zajišťuje, že všechny zprávy o incidentech, aktualizace a řešení jsou přístupné na jednom místě, což snižuje riziko ztráty informací a zajišťuje, že členové týmu mají k dispozici nejaktuálnější data.
2. Spolupráce v reálném čase
Funkce pro spolupráci v ClickUp usnadňují plynulou komunikaci mezi členy týmu. Uživatelé mohou přímo komentovat úkoly, sdílet soubory a aktualizovat stav incidentů v reálném čase pomocí zobrazení ClickUp Chat. Tato funkce je výhodná pro týmy pracující na různých místech nebo v různých časových pásmech, protože zajišťuje, že všichni zůstávají informováni a koordinovaní.

3. Automatizovaná správa pracovních postupů
ClickUp Automations pomáhá vytvářet automatizované pracovní postupy, které spouštějí konkrétní akce na základě předem definovaných podmínek. Například když je nahlášena incident, mohou být automaticky odeslána oznámení příslušným členům týmu a úkoly mohou být přiděleny na základě typu incidentu. To snižuje manuální úsilí a urychluje řešení incidentů.
4. Integrované reportování a analytika
Platforma poskytuje robustní nástroje pro reporting a analytiku, které pomáhají sledovat trendy incidentů a metriky výkonu. Týmy mohou generovat podrobné zprávy o prioritizaci incidentů, době řešení incidentů, míře opakování a dalších klíčových ukazatelích výkonu. Tento datově orientovaný přístup pomáhá identifikovat vzorce, hodnotit účinnost strategií reakce a činit informovaná rozhodnutí s cílem zlepšit procesy správy incidentů.
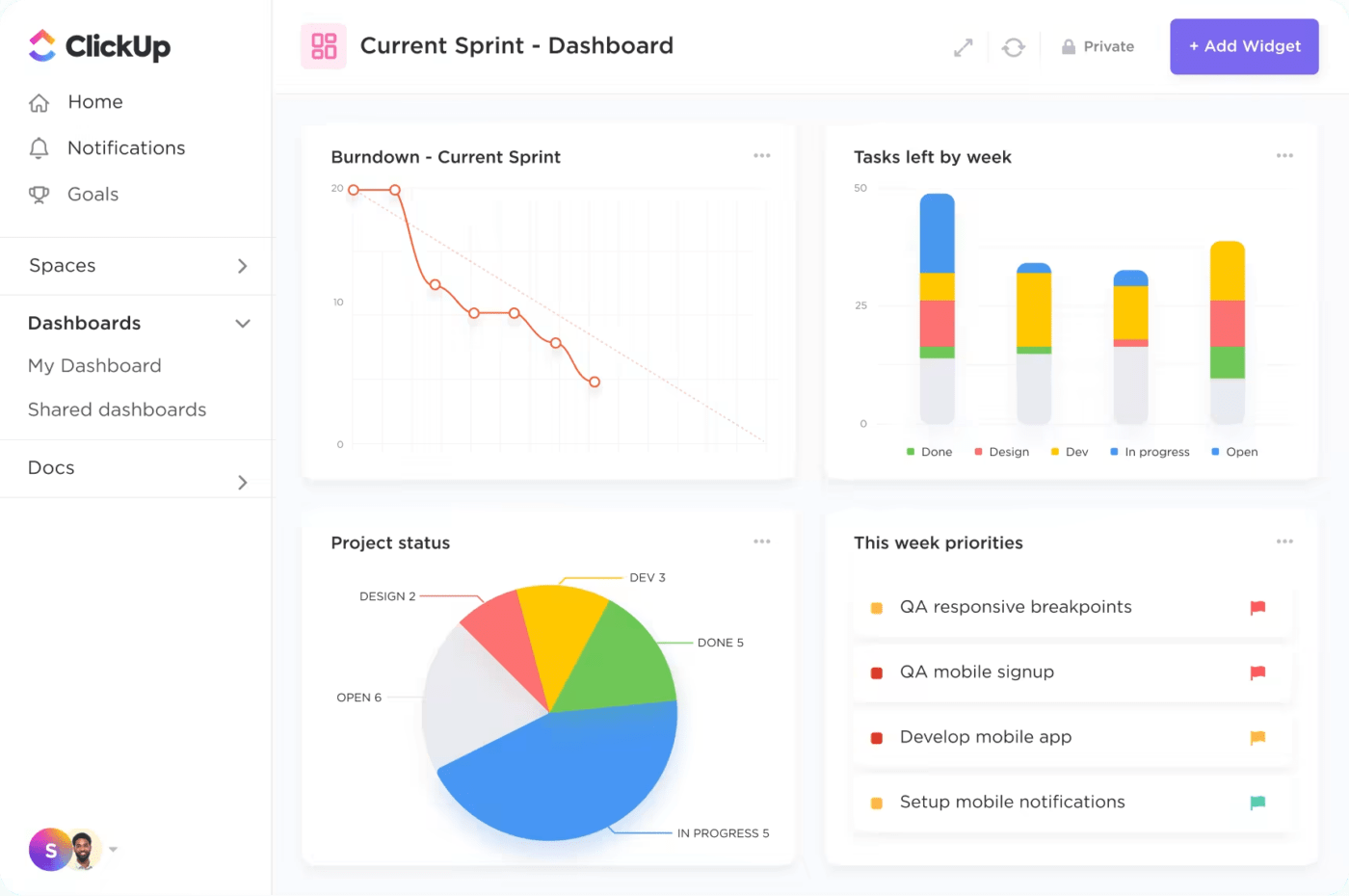
5. Přizpůsobitelné řídicí panely
Platforma vám umožňuje vytvářet přizpůsobené panely, které zobrazují důležité metriky a KPI pro správu incidentů. Panely ClickUp poskytují vizuální přehled o probíhajících incidentech, nevyřízených úkolech a výkonu týmu, což manažerům umožňuje rychle posoudit aktuální stav správy incidentů a řešit případné problémy.
6. Předem připravené šablony
ClickUp nabízí řadu přizpůsobitelných IT šablon určených pro správu incidentů. Tyto šablony také pomáhají uživatelům dokumentovat chyby.
Například šablona zprávy o IT incidentech ClickUp umožňuje IT týmům rychle a efektivně dokumentovat, sledovat a řešit incidenty. To nejen zvyšuje rychlost služeb, ale také pomáhá společnostem identifikovat dlouhodobé trendy, které mohou řešit za účelem zlepšení své celkové IT infrastruktury.
Tato šablona usnadňuje:
- Dokumentujte a nahlašujte incidenty přesně
- Sledujte řešení problémů v reálném čase
- Identifikujte vzorce v nahlášených problémech pro proaktivní řešení problémů.
Obsahuje základní komponenty, jako je podrobný popis, kontrolní seznam, dílčí úkoly a přizpůsobitelná pole. Díky této flexibilitě lze šablonu přizpůsobit procesům a postupům vaší organizace a vytvořit tak komplexní zprávu o IT incidentech.
Můžete také použít šablonu akčního plánu pro incidenty ClickUp, která zjednodušuje vytváření komplexních akčních plánů pro incidenty (IAP) pro firmy.
Tato šablona systematicky zahrnuje všechny důležité informace, které vám pomohou vytvořit spolehlivé záznamy o činnostech souvisejících s incidenty a zavést účinné strategie reakce.
Šablona obsahuje barevně odlišené sekce pro přehlednou dokumentaci:
- Shrnutí situace: Poskytuje stručný přehled incidentu a celkového akčního plánu.
- Plán provedení: Podrobně popisuje cíle a strategie pro řízení incidentu.
- Kontaktní údaje týmu pro řešení incidentů: Seznam kontaktních údajů osob zapojených do řešení incidentů.
- Seznam organizací pro řešení incidentů: Popisuje role a odpovědnosti týmů pro provoz, plánování, logistiku a finance.
- Seznam přiřazených incidentů: Přiřazuje konkrétní úkoly vedoucím a členům týmu.
- Mapa/souhrn situace: Obsahuje grafické znázornění místa nebo oblasti incidentu.
- Schválení plánu pro řešení incidentů: Zachycuje podrobnosti, jako je jméno osoby, která plán předkládá, datum předložení a požadované podpisy.
Díky této šabloně mohou společnosti efektivně shromáždit všechny potřebné údaje pro schválení IAP a zajistit dobře koordinovanou a důkladnou reakci na incidenty.
Osvědčené postupy při řízení incidentů
Účinné řízení incidentů se opírá o osvědčené postupy, které zajišťují rychlé a efektivní řešení.
Stanovte jasná očekávání pomocí SLA
Smlouvy o úrovni služeb (SLA) hrají významnou roli, protože stanovují jasná očekávání ohledně toho, jak rychle by týmy měly řešit incidenty na základě jejich závažnosti.
SLA definují konkrétní doby reakce a řešení, které pomáhají stanovit priority incidentů a vedou týmy k efektivnímu řízení jejich pracovní zátěže. Tento strukturovaný přístup vám pomáhá soustředit zdroje tam, kde jsou nejvíce potřebné, abyste mohli sladit řešení incidentů s obchodními prioritami a minimalizovat prostoje.
Pravidelně instalujte opravy, abyste předešli incidentům.
Další nezbytnou praxí je pravidelné instalování oprav, které pomáhá předcházet incidentům tím, že opravuje zranitelnosti dříve, než mohou být zneužity. Jedná se o nepřetržitý proces, který řeší bezpečnostní chyby v softwaru a systémech, čímž útočníkům ztěžuje zneužívání známých slabých míst.
Tato praxe je základním prvkem rámce pro řízení rizik v oblasti kybernetické bezpečnosti, protože chrání IT infrastrukturu před novými hrozbami a snižuje riziko narušení. Bez včasných oprav zůstávají zranitelnosti otevřené a mohou vést k závažným bezpečnostním problémům.
Upřednostněte monitorování datových center
Správa datového centra také hraje důležitou roli při řízení incidentů. Správná správa zajišťuje, že fyzické i virtuální aspekty datového centra jsou dobře udržovány. To zahrnuje dohled nad kontrolou prostředí, napájením a fyzickou bezpečností.
Zde jsou klíčové systémy monitorování v reálném čase, které pomáhají odhalit a řešit problémy dříve, než se zhorší. Efektivní správa datových center v kombinaci s dobře implementovaným rámcem pro řízení kybernetických rizik umožňuje včasné odhalení problémů, což pomáhá předcházet závažným narušením a udržovat stabilitu IT operací.
Výhody a výzvy správy incidentů
Incidenty mohou zpomalit postup projektu a vyčerpat cenné zdroje, což často způsobuje významné provozní výpadky a potenciální ztrátu důležitých dat. To podtrhuje zásadní význam efektivního řízení incidentů.
Mezi hlavní výhody správy incidentů patří:
1. Vylepšené odklonění incidentů
Odklonění incidentů zahrnuje proaktivní identifikaci a zmírnění potenciálních problémů, než se vyvinou v závažné potíže. Efektivní systémy řízení incidentů umožňují organizacím zavádět preventivní opatření a průběžně sledovat výkon systému, čímž se snižuje četnost a závažnost incidentů.
2. Zefektivněný proces změn
Dobře řízený proces změn zajišťuje, že zaměstnanci provádějí aktualizace a úpravy systematicky podle stanovených postupů. Využití standardních operačních postupů (SOP) pro řízení změn pomáhá standardizovat postupy, zajišťuje konzistentnost a snižuje riziko chyb.
3. Efektivní řešení a uzavření incidentů
Jasně definovaný proces řešení zajišťuje, že týmy řeší incidenty rychle a podnikají všechny nezbytné kroky k vyřešení problému. Po vyřešení jsou incidenty formálně uzavřeny s kompletní dokumentací a následnými opatřeními. Tento strukturovaný přístup zlepšuje provozní efektivitu a poskytuje cenné záznamy pro analýzu po incidentu a neustálé zlepšování, což pomáhá vylepšovat strategie řízení incidentů v průběhu času.
Výzvy správy incidentů
Navzdory výhodám se při řízení incidentů často vyskytuje několik problémů.
1. Obtížnost identifikace základních příčin
Jednou z významných výzev je identifikace příčiny incidentu, zejména při řešení složitých problémů, které zahrnují více systémových komponent a vzájemné závislosti.
Přesná diagnostika základní příčiny vyžaduje důkladné vyšetření a často zahrnuje spolupráci napříč funkcemi. Standardní operační postupy (SOP) mohou pomoci při vytváření standardizovaných postupů pro analýzu základních příčin, ale jejich efektivní implementace vyžaduje pokročilé nástroje a metodiky.
Stanley Security čelila podobné výzvě při řízení procesů reakce na incidenty. Jako globální lídr v oblasti bezpečnostních řešení se Stanley Security potýká s různými incidenty napříč různými systémy a regiony.
Dříve se marketingové týmy společnosti při interní komunikaci a správě úkolů spoléhaly na nástroje jako Excel a e-mail. Pandemie COVID-19 zvýšila poptávku po integrovanějších a škálovatelnějších nástrojích pro správu projektů, což zdůraznilo potřebu odstranit izolovanost jednotlivých oddělení a zvýšit produktivitu.
ClickUp poskytl globálním týmům jednotný pracovní prostor, který usnadňuje komunikaci a organizuje dokumenty i standardní operační postupy do celosvětové databáze. Díky této harmonizaci mohly týmy efektivněji spolupracovat a sdílet osvědčené postupy. Výsledkem bylo, že společnost Stanley Security dosáhla 80% zlepšení týmové práce a ušetřila více než 8 hodin týdně na schůzkách a aktualizacích. Rovněž zaznamenala 50% snížení času stráveného vytvářením a sdílením zpráv.
2. Opakování incidentů
Další výzvou je zabránit opakování incidentů. To vyžaduje hluboké pochopení základních problémů a zavedení účinných preventivních opatření. Identifikace vzorců a trendů z minulých incidentů je nezbytná pro vývoj strategií ke zmírnění budoucích rizik.
ClickUp řeší tento problém poskytováním integrovaných nástrojů pro reporting a analýzu, které nabízejí přehled o metrikách incidentů a trendech výkonu. Tento datově orientovaný přístup usnadňuje identifikaci opakujících se problémů a pomáhá vyvíjet cílené preventivní strategie.

Řešení IT & PMO od ClickUp vám v tomto ohledu může pomoci:
- Vytvořte vlastní stavy (např. „Uzavřeno“, „Pozastaveno“, „Probíhá“) a pole (např. „Žadatel“, „Oddělení“) pro efektivní kategorizaci a správu incidentů.
- Sledujte a monitorujte incidenty v reálném čase a zajistěte tak rychlé aktualizace a kontroly stavu.
- Připojte k incidentům relevantní dokumenty, snímky obrazovky nebo protokoly pro analýzu. Vytvořte znalostní databázi pro řešení běžných incidentů.
- Vytvářejte zprávy o frekvenci incidentů, době řešení a základních příčinách, abyste mohli identifikovat trendy a zlepšit reakci.
- Propojte ClickUp s dalšími IT nástroji a získejte ucelený přehled o incidentech.
Zvládnutí správy incidentů pro optimální úspěch projektu
Zvládnutí správy incidentů není jen o reakci na problémy – jde o vytvoření odolného a agilního prostředí, kde jsou přerušení rychle řešena a cíle projektu jsou dosahovány s minimálním dopadem.
Zavedení těchto strategií pomůže vašemu týmu vyhnout se potenciálním problémům a zajistí hladký a úspěšný průběh vašich projektů.
S ClickUp získáte výhodu all-in-one platformy, která integruje správu incidentů se správou projektů a IT operací. Díky sledování v reálném čase, automatizovaným pracovním postupům a nástrojům pro spolupráci umožňuje ClickUp vašemu týmu rychle řešit a vyřešit problémy a zároveň udržet vaše projekty na správné cestě. Ať už spravujete každodenní operace nebo se potýkáte se složitými požadavky projektů, ClickUp poskytuje přehlednost a kontrolu potřebnou pro dosažení výjimečných výsledků.
Jste připraveni zlepšit správu incidentů a úspěch projektů? Zaregistrujte se ještě dnes na ClickUp a proměňte správu incidentů!