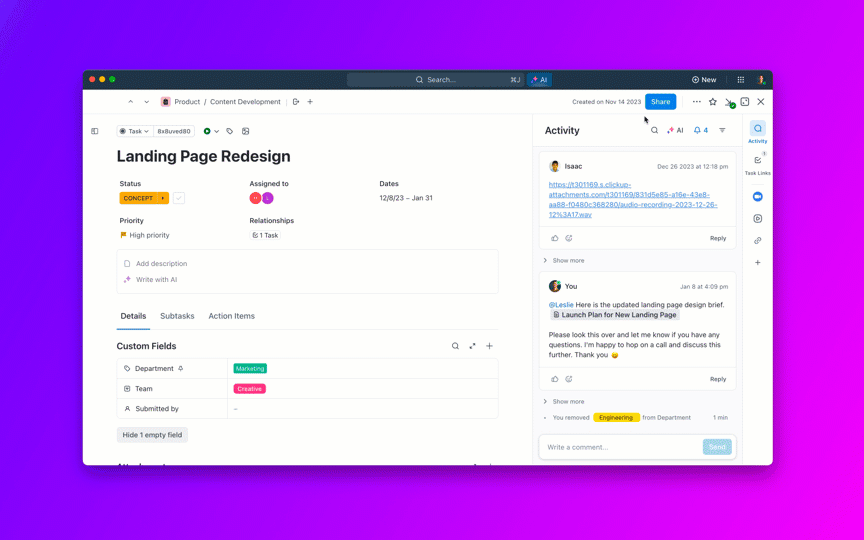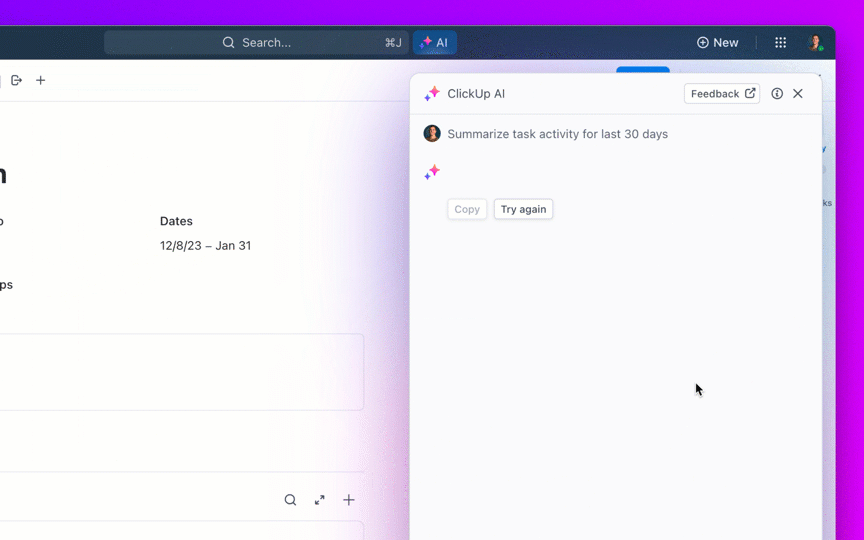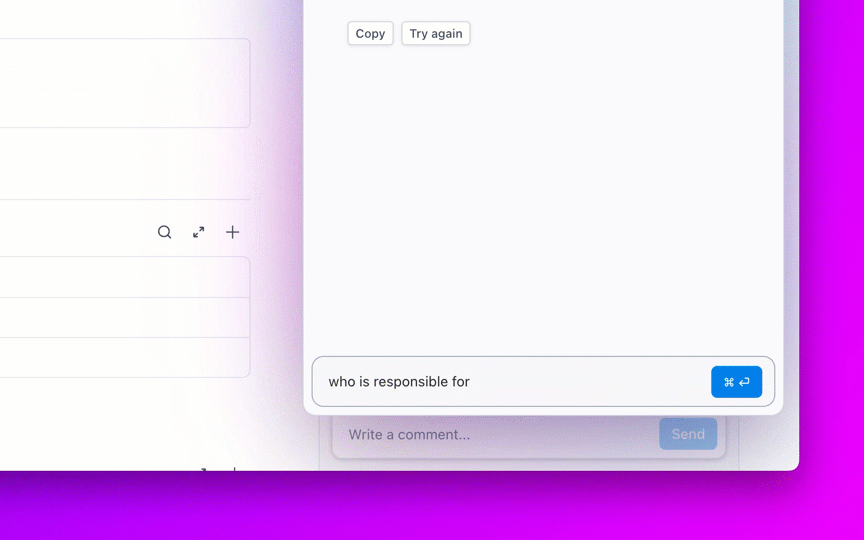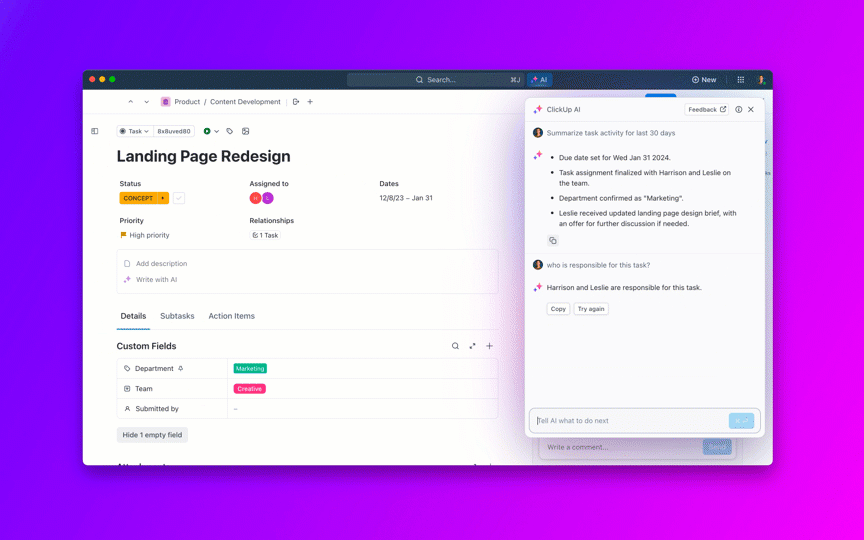

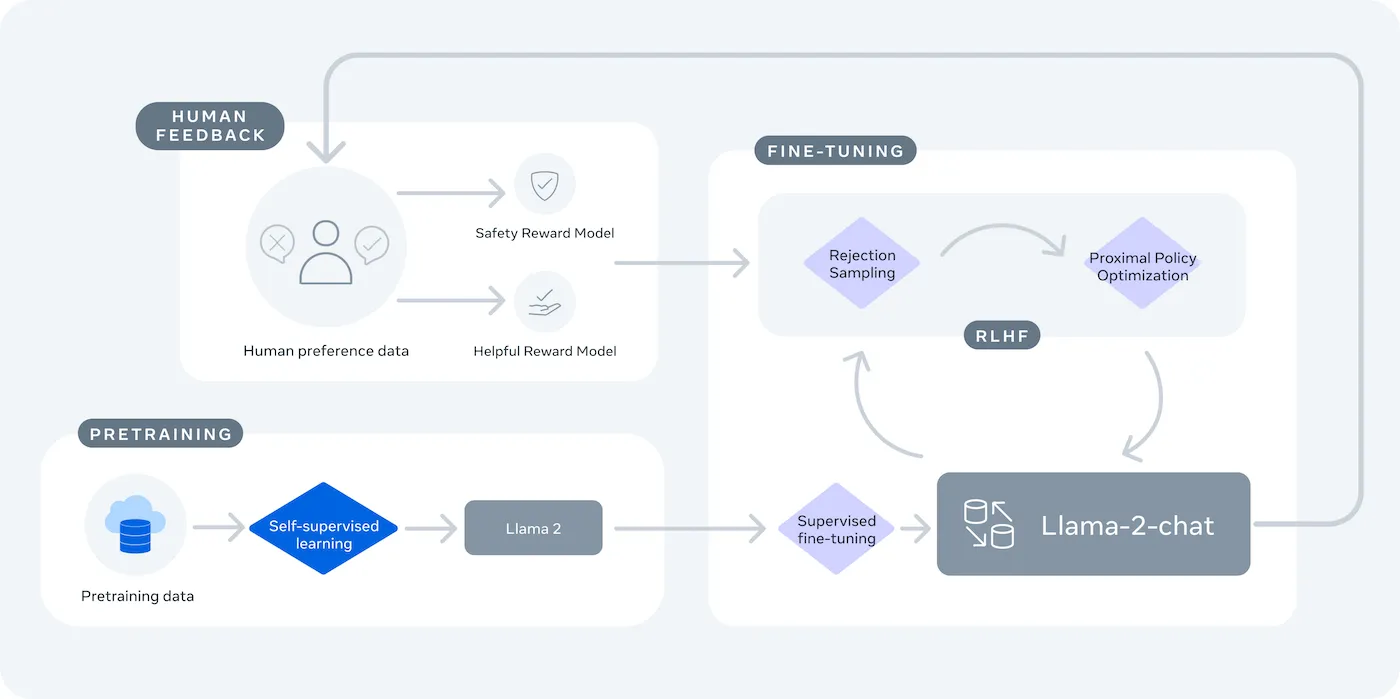
Повечето екипи, които проучват моделите на изкуствен интелект с отворен код, откриват, че LLaMA на Meta предлага рядко срещана комбинация от мощност и гъвкавост, но техническата настройка може да се усеща като сглобяване на мебели без инструкции.
Това ръководство ви води през процеса на създаване на функционален LLaMA чатбот от нулата, като обхваща всичко от хардуерни изисквания и достъп до модели до инженерство на подсказки и стратегии за внедряване.
Да започваме!
Какво е LLaMA и защо да го използвате за чатботове?
Създаването на чатбот с патентовани API често дава усещането, че сте заключени в чужда система, с непредвидими разходи и въпроси, свързани с поверителността на данните. Тази зависимост от доставчика означава, че не можете да персонализирате модела според уникалните нужди на вашия екип, което води до общи отговори и потенциални проблеми с съответствието.
LLaMA (Large Language Model Meta AI) е семейството от езикови модели с отворен код на Meta, което предлага мощна алтернатива. То е проектирано както за научни изследвания, така и за търговска употреба, като ви дава контрол, който моделите със затворен код не предлагат.
Моделите LLaMA се предлагат в различни размери, измервани в параметри (например 7B, 13B, 70B). Представете си параметрите като мярка за сложността и мощността на модела – по-големите модели са по-способни, но изискват повече изчислителни ресурси.
Ето защо може да използвате чатбот LLaMA:
- Поверителност на данните: Когато изпълнявате модел на собствената си инфраструктура, данните от разговорите никога не напускат вашата среда. Това е от решаващо значение за екипите, които работят с чувствителна информация.
- Персонализиране: Можете да настроите модела LLaMA според вътрешните документи или данни на вашата компания. Това му помага да разбере вашия конкретен контекст и да дава много по-релевантни отговори.
- Предвидимост на разходите: След първоначалната настройка на хардуера не е нужно да се притеснявате за таксите за API на токен. Разходите ви стават фиксирани и предвидими.
- Без ограничения на скоростта: Капацитетът на вашия чатбот се ограничава от вашия хардуер, а не от квотите на доставчика. Можете да го мащабирате според нуждите си.
Основният компромис е удобството за контрол. LLaMA изисква по-техническа настройка от API тип „plug-and-play“. За производствени чатботове екипите обикновено използват LLaMA 2 или по-новата LLaMA 3, която предлага подобрено разсъждение и може да обработва повече текст наведнъж.
Какво ви е необходимо, преди да създадете LLaMA чатбот
Да се впуснете в проект за разработка без подходящите инструменти е рецепта за разочарование. Стигате до половината, само за да осъзнаете, че ви липсва ключов хардуер или софтуер, което пречи на напредъка ви и ви коства часове от времето ви.
За да избегнете това, съберете всичко необходимо предварително. Ето списък за проверка, който ще ви гарантира гладък старт. 🛠️
Хардуерни изисквания
| Размер на модела | Минимална VRAM | Алтернативна опция |
|---|---|---|
| 7B параметри | 8 GB | Облачен GPU инстанс |
| 13B параметри | 16 GB | Облачен GPU инстанс |
| 70B параметри | Множество графични процесори | Квантизация или облак |
Ако вашият локален компютър не разполага с достатъчно мощен графичен процесор (GPU), можете да използвате облачни услуги като AWS или GCP. Платформи за изводи като Baseten и Replicate също предлагат достъп до GPU на базата на плащане при ползване.
Системни изисквания
- Python 3. 8+: Това е стандартният език за програмиране за проекти за машинно обучение.
- Мениджър на пакети: Ще ви е необходим pip или Conda, за да инсталирате необходимите библиотеки за вашия проект.
- Виртуална среда: Това е най-добрата практика, която изолира зависимостите на вашия проект от други Python проекти на вашия компютър.
Изисквания за достъп
- Акаунт в Hugging Face: Ще ви е необходим акаунт, за да изтеглите теглата на модела LLaMA.
- Одобрение от Meta: Трябва да приемете лицензионното споразумение на Meta, за да получите достъп до моделите LLaMA, което обикновено се одобрява в рамките на няколко часа.
- API ключове: Те са необходими само ако решите да използвате хоствана крайна точка за извличане на заключения, вместо да изпълнявате модела локално.
За това ръководство ще използваме рамката LangChain. Тя опростява много от сложните части при създаването на чатбот, като управлението на подсказки и историята на разговорите.
{kind=link}
Как да създадете чатбот с LLaMA стъпка по стъпка
Свързването на всички технически елементи на чатбота – моделът, подсказката, паметта – може да изглежда прекалено сложно. Лесно е да се загубите в кода, което води до грешки и чатбот, който не работи както се очаква. Това стъпка по стъпка ръководство разбива процеса на прости, лесни за управление части.
Този подход работи, независимо дали изпълнявате модела на собствения си компютър или използвате хостинг услуга.
Стъпка 1: Инсталирайте необходимите пакети
Първо трябва да инсталирате основните библиотеки на Python. Отворете терминала си и изпълнете тази команда:
pip install langchain transformers accelerate torch
Ако използвате хостинг услуга като Baseten за изводи, ще трябва да инсталирате и специфичния й софтуерен пакет за разработка (SDK):
pip install baseten
Ето какво прави всеки от тези пакети:
- Langchain: Рамка, която помага за създаването на приложения с големи езикови модели, включително управление на вериги от разговори и памет.
- Трансформатори: Библиотеката Hugging Face за зареждане и изпълнение на модела LLaMA.
- Accelerate: Библиотека, която помага за оптимизиране на начина, по който моделът се зарежда на вашия CPU и GPU.
- Torch: Библиотеката PyTorch, която осигурява мощността на бекенда за изчисленията на модела.
Ако изпълнявате модела локално на машина с NVIDIA GPU, уверете се, че CUDA е инсталиран и конфигуриран правилно. Това позволява на модела да използва GPU за много по-бърза работа.
Стъпка 2: Получете достъп до моделите LLaMA
Преди да можете да изтеглите модела, трябва да получите официален достъп от Meta чрез Hugging Face.
- Създайте акаунт на huggingface.co
- Отидете на страницата на модела, например meta-llama/Llama-2-7b-chat-hf
- Кликнете върху „Достъп до хранилището“ и се съгласете с лицензионните условия на Meta.
- В настройките на вашия акаунт в Hugging Face генерирайте нов токен за достъп.
- В терминала си стартирайте huggingface-cli login и поставете токена си, за да удостоверите машината си.
Одобрението обикновено е бързо. Уверете се, че сте избрали модел с „чат“ в името, тъй като те са специално обучени за разговорни задачи.
Стъпка 3: Заредете модела LLaMA
Сега можете да заредите модела в кода си. Имате две основни опции в зависимост от хардуера си.
Ако разполагате с достатъчно мощен графичен процесор, можете да заредите модела локално:
Ако хардуерът ви е ограничен, можете да използвате хоствана услуга за извличане на заключения:
Командата device_map="auto" указва на библиотеката transformers да разпредели автоматично модела между всички налични GPU.
Ако все още нямате достатъчно памет, можете да използвате техника, наречена квантизация, за да намалите размера на модела, въпреки че това може леко да намали неговата производителност.
Стъпка 4: Създайте шаблон за подсказване
Чат моделите LLaMA са обучени да очакват конкретен формат на подсказките. Шаблонът за подсказки гарантира, че въведените данни са структурирани правилно.
Нека разгледаме този формат:
- <
>: Тази секция съдържа системния подсказващ текст, който дава на модела основните инструкции и определя неговата личност. - [INST]: Това бележи началото на въпроса или инструкцията на потребителя.
- [/INST]: Това сигнализира на модела, че е време да генерира отговор.
Имайте предвид, че различните версии на LLaMA могат да използват леко различни шаблони. Винаги проверявайте документацията на модела в Hugging Face за правилния формат.
Стъпка 5: Настройте веригата на чатбота
След това ще свържете модела си и шаблона за подсказване в разговорна верига, използвайки LangChain. Тази верига ще включва и памет, за да следи разговора.
LangChain предлага няколко типа памет:
- ConversationBufferMemory: Това е най-простият вариант. Той съхранява цялата история на разговорите.
- ConversationSummaryMemory: За да спестите място, тази опция периодично обобщава по-старите части от разговора.
- ConversationBufferWindowMemory: Това запазва само последните няколко разговора в паметта, което е полезно за предотвратяване на прекалено дългия контекст.
За тестване ConversationBufferMemory е чудесно място за начало.
Стъпка 6: Стартирайте цикъла на чатбота
Накрая можете да създадете проста верига, за да взаимодействате с чатбота си от терминала.
В реална приложение, бихте заменили тази верига с API крайна точка, използвайки рамка като FastAPI или Flask. Можете също да предавате отговора на модела обратно на потребителя, което прави чатбота много по-бърз.
Можете също да настроите параметри като температура, за да контролирате случайността на отговорите. Ниска температура (например 0,2) прави резултата по-детерминиран и фактически, докато по-висока температура (например 0,8) насърчава по-голяма креативност.
📚 Прочетете също: AI агент срещу чатбот: основни разлики и кой е подходящ за вас?
Как да тествате своя LLaMA чатбот
Създали сте чатбот, който дава отговори, но готов ли е той за реални потребители? Разгръщането на нетестван бот може да доведе до неудобни неуспехи, като предоставяне на невярна информация или генериране на неподходящо съдържание, което може да навреди на репутацията на вашата компания.
Систематичен план за тестване е решението на тази несигурност. Той гарантира, че вашият чатбот е стабилен, надежден и безопасен.
Функционално тестване:
- Крайни случаи: Тествайте как ботът се справя с празни входни данни, много дълги съобщения и специални символи.
- Проверка на паметта: Уверете се, че чатботът запомня контекста на няколко последователни реплики в разговора.
- Следващи инструкции: Проверете дали ботът спазва правилата, които сте задали в системния подсказващ прозорец.
Оценка на качеството:
- Релевантност: Отговорът действително отговаря ли на въпроса на потребителя?
- Точност: Информацията, която предоставя, е ли правилна?
- Съгласуваност: Разговорът протича ли логично?
- Безопасност: Ботът отказва ли да отговаря на неподходящи или вредни запитвания?
Тестване на производителността:
- Латентност: Измерете колко време отнема на бота да започне да отговаря и да завърши отговора си.
- Използване на ресурси: Следете колко GPU памет използва моделът по време на извличане на заключения.
- Едновременност: Тествайте как работи системата, когато няколко потребители взаимодействат с нея едновременно.
Също така, внимавайте за често срещани проблеми с LLM, като халюцинации (уверено изказване на невярна информация), отклоняване от контекста (загуба на нишката на разговора при дълги разговори) и повторения. Записването на всички тестови разговори е чудесен начин да откриете модели и да отстраните проблеми, преди те да достигнат до вашите потребители.
📚 Прочетете също: Разликата между функционално тестване и нефункционално тестване
Примери за използване на LLaMA чатбот за екипи
След като преминете през механиката на фината настройка и внедряването, LLaMA става най-ценен, когато се прилага към ежедневните проблеми на екипа, а не към абстрактни AI демонстрации. Екипите обикновено не се нуждаят от „чатбот“, а от по-бърз достъп до знания, по-малко ръчни прехвърляния и по-малко повтаряща се работа.
Вътрешен асистент за знания
Чрез фина настройка на LLaMA въз основа на вътрешна документация, уикита и често задавани въпроси – или чрез съчетаването му с база от знания, базирана на RAG – екипите могат да задават въпроси на естествен език и да получават точни отговори, съобразени с контекста. Това премахва неудобството от търсенето в разпръснати инструменти, като същевременно чувствителните данни остават изцяло вътрешни, вместо да се изпращат към API на трети страни.
🌟 Enterprise Search в ClickUp и предварително създаденият агент Ambient Answers предоставят подробни контекстуални отговори на вашите въпроси, използвайки знанията в работната среда на ClickUp.
Помощник за преглед на код
Когато е обучен на базата на вашата собствена кодова база и стилови ръководства, LLaMA може да действа като асистент за контекстуална проверка на кода. Вместо общи най-добри практики, разработчиците получават предложения, които са в съответствие с конвенциите на екипа, архитектурните решения и историческите модели.
🌟 Помощникът за преглед на код, базиран на LLaMA, може да открива проблеми, да предлага подобрения или да обяснява непознат код. Codegen на ClickUp прави още една стъпка напред, като действа в рамките на работния процес на разработката – създава pull заявки, прилага рефакторинг или актуализира файлове директно в отговор на тези прозрения. Резултатът е по-малко копиране и поставяне и по-малко прекъсвания между „мисленето” и „действието”.
Сортиране на клиентската поддръжка
LLaMA може да бъде обучен за класифициране на намерения, за да разбира входящите запитвания на клиенти и да ги препраща към подходящия екип или работен процес. Често задаваните въпроси могат да се обработват автоматично, докато по-сложните случаи се препращат към човешки агенти с приложен контекст, което намалява времето за отговор, без да се жертва качеството.
Можете също така да създадете Triage Super Agent, използвайки естествен език в работната си среда ClickUp. Научете повече
Обобщаване и проследяване на срещи
Използвайки транскрипти от срещи като входни данни, LLaMA може да извлича решения, действия и ключови точки от дискусиите. Истинската стойност се проявява, когато тези резултати се вливат директно в инструменти за управление на задачи, превръщайки разговорите в проследявана работа.
🌟 AI Meeting Notetaker на ClickUp не само води бележки от срещи, но и изготвя резюмета, генерира задачи за действие и свързва бележките от срещите с вашите документи и задачи.
Изготвяне и итерация на документи
Екипите могат да използват LLaMA за създаване на първи чернови на доклади, предложения или документация въз основа на съществуващи шаблони и примери от миналото. Това прехвърля усилията от създаването на празна страница към преглед и усъвършенстване, ускорявайки доставката, без да се понижават стандартите.
🌟 ClickUp Brain може бързо да генерира чернови за документация, като запазва цялата информация за работното ви място в контекста. Опитайте го още днес.
Чатботовете, задвижвани от LLaMA, са най-ефективни, когато са вградени в съществуващи работни процеси – документация, управление на проекти и комуникация в екипа – вместо да работят като самостоятелни инструменти.
Тук интегрирането на AI директно в работното ви пространство прави голяма разлика. Вместо да създавате отделен инструмент, можете да внедрите AI за разговори там, където вече работи вашият екип.
Например, можете да създадете персонализиран LLaMA бот, който да действа като асистент за знания. Но ако той се намира извън вашия инструмент за управление на проекти, екипът ви трябва да сменя контекста, за да му зададе въпрос. Това създава напрежение и забавя работата на всички.
Елиминирайте това превключване на контекста, като използвате AI, който вече е част от вашия работен процес.
Задавайте въпроси за вашите проекти, задачи и документи, без да напускате ClickUp, като използвате ClickUp Brain. Просто напишете @brain в коментар към задача или в ClickUp Chat, за да получите незабавен отговор, съобразен с контекста. Това е като да имате член на екипа, който познава перфектно цялото ви работно пространство. 🤩
Това превръща чатбота от новост в основна част от двигателя за продуктивност на вашия екип.
Ограничения при използването на LLaMA за създаване на чатботове
Създаването на LLaMA чатбот може да бъде вдъхновяващо, но екипите често биват изненадани от скрити сложности. „Безплатният“ модел с отворен код може да се окаже по-скъп и труден за управление от очакваното, което води до лошо потребителско преживяване и постоянен цикъл на поддръжка, изчерпващ ресурсите.
Важно е да разберете ограниченията, преди да се ангажирате.
- Техническа сложност: Настройката и поддръжката на LLaMA модел изисква познания за инфраструктурата на машинно обучение.
- Хардуерни изисквания: Използването на по-големи и по-мощни модели изисква скъп GPU хардуер, а разходите за облачни услуги могат бързо да се натрупат.
- Ограничения на контекстуалния прозорец: Моделите LLaMA имат ограничена памет ( 4K токена за LLaMA 2 ). Работата с дълги документи или разговори изисква сложни стратегии за разделяне на части.
- Без вградени предпазни мерки: Вие носите отговорност за прилагането на свои собствени мерки за филтриране на съдържанието и безопасност.
- Текуща поддръжка: С пускането на нови модели ще трябва да актуализирате системите си, а фино настроените модели може да изискват повторно обучение.
Самостоятелно хостваните модели обикновено имат по-висока латентност от високо оптимизираните търговски API. Всички тези оперативни тежести се поемат от управляваните решения.
📮ClickUp Insight: 88% от участниците в нашето проучване използват AI за лични задачи, но над 50% се въздържат да го използват на работа. Трите основни пречки? Липса на безпроблемна интеграция, пропуски в знанията или опасения за сигурността.
Но какво става, ако AI е вграден във вашето работно пространство и вече е сигурен? ClickUp Brain, вграденият AI асистент на ClickUp, прави това реалност. Той разбира подсказките на обикновен език, решавайки и трите проблема, свързани с внедряването на AI, като същевременно свързва вашия чат, задачи, документи и знания в цялото работно пространство. Намерете отговори и идеи с едно кликване!
Алтернативи на LLaMA за създаване на чатботове
LLaMA е само една от многото възможности сред морето от AI модели и може да бъде трудно да разберете коя е подходяща за вас.
Ето как изглеждат алтернативите.
Други модели с отворен код:
- Mistral: Известен с високата си производителност дори при по-малки размери на моделите, което го прави ефективен.
- Falcon: Идва с много либерална лицензия, което е чудесно за търговски приложения.
- MPT: Оптимизиран за работа с дълги документи и разговори
Търговски API:
- OpenAI (GPT-4, GPT-3. 5): Общоприети за най-способните големи езикови модели, които са много лесни за интегриране.
- Anthropic (Claude): Известен със своите силни функции за безопасност и много големи контекстни прозорци.
- Google (Gemini): Предлага мощни мултимодални възможности, позволяващи му да разбира текст, изображения и аудио.
Можете да го създадете сами с отворен код, да платите за търговски API или да използвате конвергентна AI работна среда, която предлага предварително интегрирано решение с различни видове AI агенти.
📚 Прочетете също: Как да използвате чатбот за вашия бизнес
Създайте AI асистенти, които разпознават контекста, с ClickUp
Създаването на чатбот с LLaMA ви дава невероятен контрол над вашите данни, разходи и персонализация. Но този контрол идва с отговорността за инфраструктурата, поддръжката и безопасността – всичко това, с което се занимават управляваните API. Целта не е просто да създадете бот, а да направите вашия екип по-продуктивен, а сложният инженерен проект понякога може да ви отклони от това.
Правилният избор зависи от ресурсите и приоритетите на вашия екип. Ако имате опит в машинно обучение и строги изисквания за поверителност, LLaMA е фантастичен вариант. Ако давате приоритет на скоростта и простотата, интегриран инструмент може да е по-подходящ.
С ClickUp получавате конвергентно AI работно пространство, в което всички ваши задачи, документи и разговори са на едно място, поддържано от интегрирана AI. То намалява разпръскването на контекста и помага на екипите да работят по-бързо и по-ефективно, като им предоставя необходимата информация чрез персонализирани Super Agents и контекстуална AI.
Спрете да губите време за инфраструктура и се възползвайте от предимствата на AI асистент, който разпознава контекста, без да създавате нищо от нулата. Започнете безплатно с ClickUp.
Често задавани въпроси (FAQ)
Разходите зависят изцяло от метода на внедряване, а прогнозирането на проекта може да ви помогне да ги оцените. Ако използвате собствен хардуер, ще имате първоначални разходи за GPU, но няма да имате текущи такси за заявка. Доставчиците на облачни услуги таксуват на час въз основа на GPU и размера на модела.
Да, лицензите за LLaMA 2 и LLaMA 3 позволяват търговска употреба. Въпреки това, трябва да се съгласите с условията за ползване на Meta и да предоставите необходимата атрибуция във вашия продукт.
LLaMA 3 е по-новият и по-мощен модел, който предлага по-добри умения за разсъждение и по-голям контекстен прозорец (8K токена спрямо 4K за LLaMA 2). Това означава, че може да обработва по-дълги разговори и документи, но също така изисква повече изчислителни ресурси за работа.
Макар Python да е най-разпространеният език за машинно обучение благодарение на обширните си библиотеки, той не е строго необходим. Някои платформи започват да предлагат решения без код или с малко код, които ви позволяват да разгърнете LLaMA чатбот с графичен интерфейс. /