
Проектите за обучение на AI рядко се провалят на ниво модел. Те срещат затруднения, когато експериментите, документацията и актуализациите на заинтересованите страни са разпръснати в прекалено много инструменти.
Това ръководство ви води през обучението на модели с Databricks DBRX – LLM, който е до два пъти по-ефективен от други водещи модели – като същевременно поддържа работата около него организирана в ClickUp.
От настройката и фината настройка до документацията и актуализациите между екипите, ще видите как едно единно, конвергентно работно пространство помага да се елиминира разпръскването на контекста и поддържа екипа ви фокусиран върху изграждането, а не върху търсенето. 🛠
Какво е DBRX?
DBRX е мощен, отворен код, голям езиков модел (LLM), проектиран специално за обучение и извличане на заключения от AI модели в предприятията. Тъй като е отворен код под Databricks Open Model License, вашият екип има пълен достъп до тежестите и архитектурата на модела, което ви позволява да го проверявате, модифицирате и внедрявате по ваши собствени условия.
Той се предлага в два варианта: DBRX Base за задълбочено предварително обучение и DBRX Instruct за готови задачи, следващи инструкции.
Архитектура на DBRX и дизайн на смесица от експерти
DBRX решава задачи, използвайки архитектура Mixture-of-Experts (MoE). За разлика от традиционните големи езикови модели, които използват всичките си милиарди параметри за всяко едно изчисление, DBRX активира само част от общия брой параметри (най-релевантните експерти) за дадена задача.
Представете си го като екип от специализирани експерти; вместо всеки да работи по всеки проблем, системата интелигентно насочва всяка задача към най-подходящите квалифицирани параметри.
Това не само намалява времето за реакция, но и осигурява най-висока производителност и резултати, като същевременно значително намалява разходите за изчисления.
Ето кратък поглед върху основните му спецификации:
- Общ брой параметри: 132B за всички експерти
- Активни параметри: 36B на препратка
- Брой експерти: общо 16 (MoE Top-4 маршрутизация), с 4 активни за всеки даден токен
- Контекстно прозорец: 32K токена
Данни за обучение на DBRX и спецификации на токени
Ефективността на LLM зависи изцяло от данните, с които е обучен. DBRX е предварително обучен на базата на огромен набор от данни от 12 трилиона токена, внимателно подбрани от екипа на Databricks с помощта на техните усъвършенствани инструменти за обработка на данни. Именно затова той се представя отлично в индустриалните бенчмаркове.
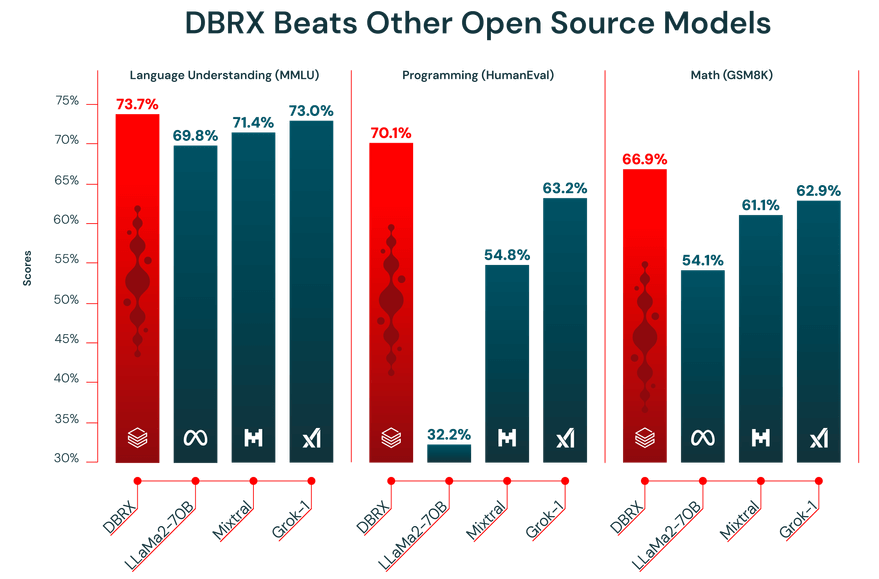
Освен това DBRX разполага с контекстно прозорец от 32 000 токена. Това е количеството текст, което моделът може да обработи едновременно. Големият контекстен прозорец е изключително полезен за сложни задачи като обобщаване на дълги доклади, преглеждане на обемни правни документи или изграждане на усъвършенствани системи за генериране с разширено извличане (RAG), тъй като позволява на модела да запази контекста, без да съкращава или пропуска информация.
🎥 Гледайте това видео, за да видите как оптимизираната координация на проектите може да промени работния ви процес по обучение на AI и да елиминира неудобството от преминаването между несвързани инструменти. 👇🏽
Как да получите достъп и да настроите DBRX
DBRX предлага два основни начина за достъп, като и двата осигуряват пълен достъп до теглата на модела при либерални търговски условия. Можете да използвате Hugging Face за максимална гъвкавост или да получите достъп директно чрез Databricks за по-интегрирано преживяване.
Достъп до DBRX чрез Hugging Face
За екипи, които ценят гъвкавостта и вече са запознати с екосистемата Hugging Face, достъпът до DBRX чрез Hub е идеалният вариант. Той ви позволява да интегрирате модела в съществуващите си работни процеси, базирани на трансформатори.
Ето как да започнете:
- Създайте или влезте в своя акаунт в Hugging Face
- Преминете към картата на модела DBRX в Hub и приемете условията на лиценза.
- Инсталирайте библиотеката transformers заедно с необходимите зависимости като accelerate.
- Използвайте класа AutoModelForCausalLM в Python скрипта си, за да заредите модела DBRX.
- Конфигурирайте своя инференционен пайплайн, като имате предвид, че DBRX изисква значителна GPU памет (VRAM) за ефективна работа.
📖 Прочетете още: Как да конфигурирате температурата на LLM
Достъп до DBRX чрез Databricks
Ако вашият екип вече използва Databricks за инженеринг на данни или машинно обучение, най-лесният начин е да получите достъп до DBRX чрез платформата. Това елиминира трудностите при настройката и ви предоставя всички инструменти, от които се нуждаете за MLOps, точно там, където вече работите.
Следвайте тези стъпки в работното си пространство Databricks, за да започнете:
- Преминете към раздела „Model Garden“ или „Mosaic AI“.
- Изберете DBRX Base или DBRX Instruct, в зависимост от вашите нужди.
- Конфигурирайте крайна точка за достъп до API или настройте среда за бележник за интерактивно използване.
- Започнете да тествате изводите с примерни подсказки, за да се уверите, че всичко работи правилно, преди да разширите обучението или внедряването на AI модела си.
Този подход ви дава безпроблемен достъп до инструменти като MLflow за проследяване на експерименти и Unity Catalog за управление на модели.
📮 ClickUp Insight: Средностатистическият професионалист прекарва над 30 минути на ден в търсене на информация, свързана с работата – това са над 120 часа годишно, загубени в ровене из имейли, Slack низове и разпръснати файлове.
Интелигентен AI асистент, вграден в работното ви пространство, може да промени това. Запознайте се с ClickUp Brain.
Той предоставя незабавни прозрения и отговори, като извежда на преден план подходящите документи, разговори и подробности за задачите за секунди – така че можете да спрете да търсите и да започнете да работите.
Как да настроите DBRX и да обучите персонализирани AI модели
Готов модел, колкото и мощен да е, никога няма да разбере уникалните нюанси на вашия бизнес. Тъй като DBRX е с отворен код, можете да го настроите, за да създадете персонализиран модел, който говори езика на вашата компания или изпълнява конкретна задача, която бихте искали да изпълнява.
Ето три често използвани начина, по които можете да направите това:
1. Настройте DBRX с набори от данни Hugging Face
За екипи, които тепърва започват или работят по общи задачи, публичните набори от данни от Hugging Face Hub са чудесен ресурс. Те са предварително форматирани и лесни за зареждане, което означава, че не е нужно да прекарвате часове в подготовка на данните си.
Процесът е доста прост:
- Намерете набор от данни в Hub, който съответства на вашата задача (например, следване на инструкции, обобщаване).
- Заредете го, използвайки библиотеката с набори от данни.
- Уверете се, че данните са форматирани в двойки инструкция-отговор.
- Конфигурирайте скрипта си за обучение с хиперпараметри като скорост на обучение и размер на партидата.
- Стартирайте задачата за обучение, като се уверите, че периодично запазвате контролни точки.
- Оценете фино настроения модел върху запазен валидационен набор, за да измерите подобрението.
2. Настройте DBRX с локални набори от данни
Обикновено най-добри резултати се постигат чрез фина настройка с вашите собствени данни. Това ви позволява да научите модела на специфичната терминология, стил и знания в областта на вашата компания. Имайте предвид, че това дава резултати само ако данните ви са чисти, добре подготвени и в достатъчен обем.
Следвайте тези стъпки, за да подготвите вътрешните си данни:
- Събиране на данни: Съберете висококачествени примери от вашите вътрешни уикита, документи и бази данни.
- Конвертиране на формат: Структурирайте данните си в последователен формат на инструкции-отговори, често като JSON редове.
- Филтриране по качество: Премахнете всички примери с ниско качество, дубликати или нерелевантни примери.
- Разделяне за валидиране: Заделете малка част от данните си (обикновено 10-15%), за да оцените ефективността на модела.
- Преглед на поверителността: Премахнете или маскирайте всякаква лична информация (PII) или чувствителни данни.
3. Настройте DBRX с StreamingDataset
Ако вашият набор от данни се окаже прекалено голям, за да се побере в паметта на вашата машина, не се притеснявайте, можете да използвате библиотеката Streaming Dataset на Databricks. Тя ви позволява да стриймвате данни директно от облачното хранилище, докато моделът се обучава, вместо да ги зареждате всички наведнъж в паметта.
Ето как можете да го направите:
- Подготовка на данни: Почистете и структурирайте данните си за обучение, след което ги съхранете в подходящ за стрийминг формат като JSONL или CSV в облачно хранилище.
- Конвертиране на формат за стрийминг: Конвертирайте вашия набор от данни в формат, подходящ за стрийминг, като Mosaic Data Shard (MDS), за да може да се чете ефективно по време на обучението.
- Настройка на зарядното устройство за обучение: Конфигурирайте зарядното устройство за обучение, така че да сочи към отдалечения набор от данни, и дефинирайте локален кеш за временно съхранение на данни.
- Инициализиране на модела: Започнете процеса на фина настройка на DBRX, използвайки рамка за обучение, която поддържа StreamingDataset, като LLM Foundry.
- Обучение на базата на стрийминг: Изпълнете задачата за обучение, докато данните се стриймват на партиди по време на обучението, вместо да се зареждат изцяло в паметта.
- Проверка и възстановяване: Възобновяване на обучението безпроблемно, ако изпълнението бъде прекъснато, без дублиране или пропускане на данни.
- Оценка и внедряване: Проверете ефективността на фино настроения модел и го внедрете, използвайки предпочитаната от вас настройка за обслужване или извод.
💡Съвет от професионалист: Вместо да създавате план за обучение с DBRX от нулата, започнете с шаблона за пътна карта за проекти за изкуствен интелект и машинно обучение на ClickUp и го адаптирайте според нуждите на вашия екип. Той предоставя ясна структура за планиране на набори от данни, фази на обучение, оценка и внедряване, така че можете да се съсредоточите върху организирането на работата си, а не върху структурирането на работния процес.
Примери за употреба на DBRX за обучение на AI модели
Едно е да имате мощен модел, но друго е да знаете точно къде той блести.
Когато нямате ясна представа за силните страни на даден модел, лесно е да похарчите време и ресурси, опитвайки се да го приложите там, където той просто не е подходящ. Това води до незадоволителни резултати и разочарование.
Уникалната архитектура и данни за обучение на DBRX го правят изключително подходящ за няколко ключови случая на употреба в предприятията. Познаването на тези предимства ви помага да съгласувате модела с вашите бизнес цели и да максимизирате възвръщаемостта на инвестициите си.
Генериране на текст и създаване на съдържание
DBRX Instruct е фино настроен за следване на инструкции и генериране на висококачествен текст. Това го прави мощен инструмент за автоматизиране на широк спектър от задачи, свързани със съдържанието. Големият му контекстен прозорец е значително предимство, което му позволява да обработва дълги документи, без да губи нишката.
Можете да го използвате за:
- Техническа документация: Създавайте и усъвършенствайте ръководства за продукти, API референции и ръководства за потребители.
- Маркетингово съдържание: Чернови на блог публикации, имейл бюлетини и актуализации в социалните медии
- Създаване на отчети: Обобщавайте сложни данни и създавайте кратки изпълнителни резюмета.
- Превод и локализация: Адаптирайте съществуващото съдържание за нови пазари и аудитории
Задачи за генериране на код и отстраняване на грешки
Значителна част от данните за обучение на DBRX включваха код, което го прави подходяща LLM поддръжка за разработчици. Той може да помогне за ускоряване на циклите на разработка чрез автоматизиране на повтарящи се задачи по кодиране и подпомагане при решаването на сложни проблеми.
Ето няколко начина, по които вашият инженерен екип може да го използва:
- Завършване на код: Автоматично генериране на функционални тела от коментари или docstrings
- Откриване на грешки: Анализирайте фрагменти от код, за да идентифицирате потенциални грешки или логически недостатъци.
- Обяснение на кода: Превеждайте сложни алгоритми или стар код на прост английски език.
- Генериране на тестове: Създавайте единични тестове въз основа на сигнатурата на функцията и очакваното поведение.
RAG и приложения с дълъг контекст
Retrieval-Augmented Generation (RAG) е мощна техника, която основава отговорите на модела на частните данни на вашата компания. Въпреки това, RAG системите често се борят с модели, които имат малки контекстни прозорци, което налага агресивно разделяне на данните, което може да доведе до загуба на важен контекст. 32K контекстният прозорец на DBRX го прави отлична основа за стабилни RAG приложения.
Това ви позволява да създавате мощни вътрешни инструменти, като например:
- Търсене в предприятието: Създайте чатбот, който отговаря на въпросите на служителите, използвайки вашата вътрешна база от знания.
- Поддръжка на клиенти: Създайте агент, който генерира отговори за поддръжка, основани на документацията на вашия продукт.
- Изследователска помощ: Разработване на инструмент, който може да синтезира информация от стотици страници изследователски документи.
- Проверка за съответствие: Автоматично проверявайте маркетинговите текстове спрямо вътрешните насоки за марката или нормативните документи.
Как да интегрирате обучението с DBRX в работния процес на вашия екип
Успешният проект за обучение на AI модели е нещо повече от просто код и изчисления. Това е съвместно усилие, в което участват ML инженери, научни работници в областта на данните, продуктови мениджъри и заинтересовани страни.
Когато това сътрудничество е разпръснато в Jupyter бележници, Slack канали и отделни инструменти за управление на проекти, вие създавате разпръскване на контекста – ситуация, в която критична информация за проекта е разпръсната в прекалено много инструменти.
ClickUp решава този проблем. Вместо да се налага да използвате няколко инструмента, получавате едно конвергентно AI работно пространство, в което проектният мениджмънт, документацията и комуникацията са обединени – така вашите експерименти остават свързани от планирането до изпълнението и оценката.
Никога не губете представа за експериментите и напредъка
Когато се провеждат множество експерименти, най-трудното не е обучението на модела, а проследяването на промените, настъпили по време на процеса. Коя версия на набора от данни е била използвана, коя скорост на обучение е дала най-добри резултати или коя версия е била пусната в производство?
ClickUp прави този процес изключително лесен за вас. Можете да проследявате всяко обучение отделно в ClickUp Tasks, а в рамките на задачите можете да използвате Custom Fields, за да регистрирате:
- Версия на набора от данни
- Хиперпараметри
- Вариант на модела (DBRX Base срещу DBRX Instruct)
- Статус на обучението (в опашка, в процес, в оценка, внедрено)
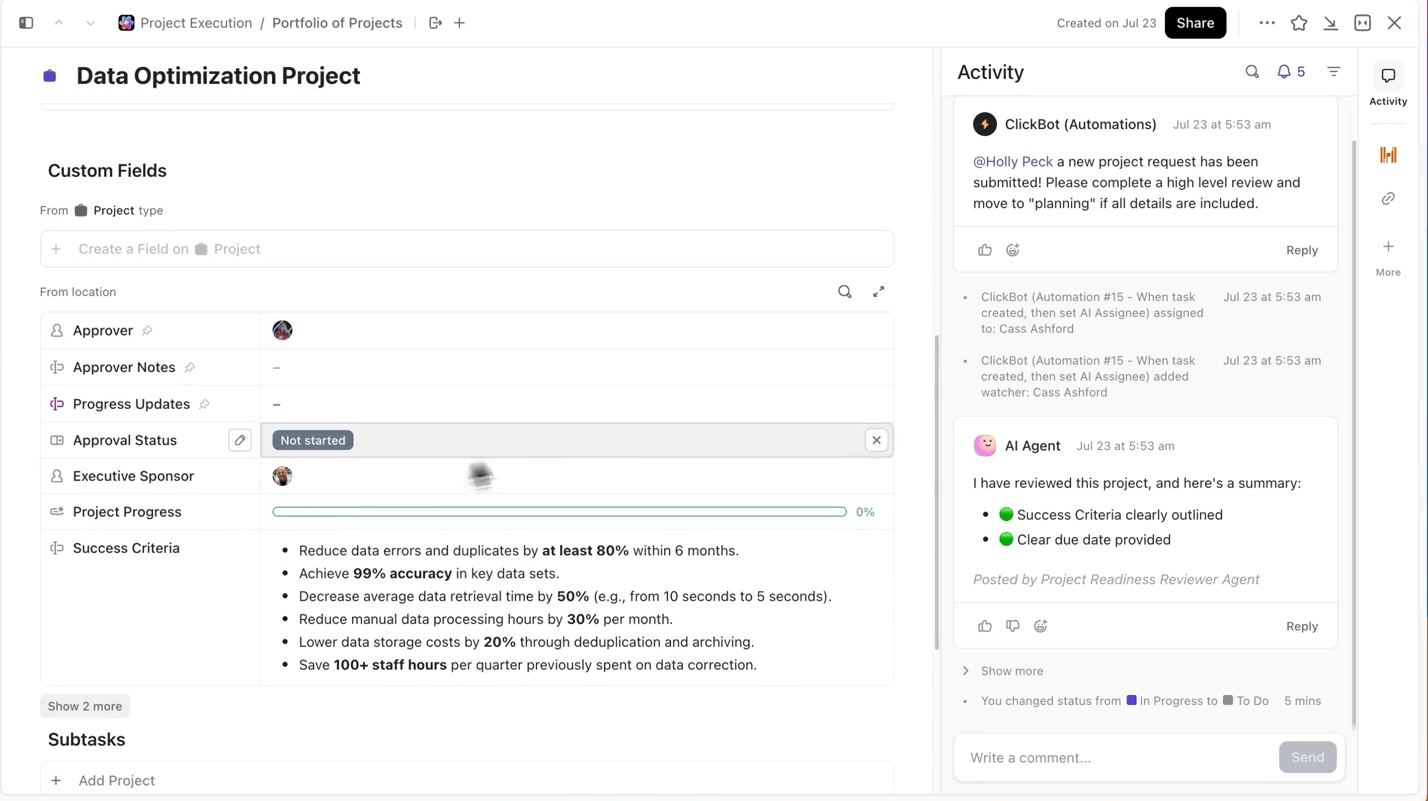
По този начин всеки документиран експеримент може да бъде търсен, лесно сравняван с други и възпроизвеждан.
Поддържайте документацията на моделите свързана с работата
Не е необходимо да преминавате между Jupyter notebooks, README файлове или Slack нишки, за да разберете контекста на задачата на експеримента.
С ClickUp Docs можете да поддържате архитектурата на модела, скриптовете за подготовка на данни или метриките за оценка организирани и достъпни , като ги документирате в документ с възможност за търсене , който се свързва директно с експерименталните задачи, от които произхождат.

💡Съвет от професионалист: Поддържайте актуален проектен брифинг в ClickUp Docs, в който се описват подробно всички решения, от архитектурата до внедряването, така че новите членове на екипа винаги да могат да се запознаят с подробностите по проекта, без да се налага да претърсват стари теми.
Предоставете на заинтересованите страни видимост в реално време
Таблото на ClickUp показва напредъка на експеримента и натоварването на екипа в реално време. I
Вместо ръчно да събирате актуализации или да изпращате имейли, таблото се актуализира автоматично въз основа на данните във вашите задачи. Така заинтересованите страни могат да проверяват по всяко време как стоят нещата и никога не се налага да ви прекъсват с въпроси от типа „Какъв е статуса?“.
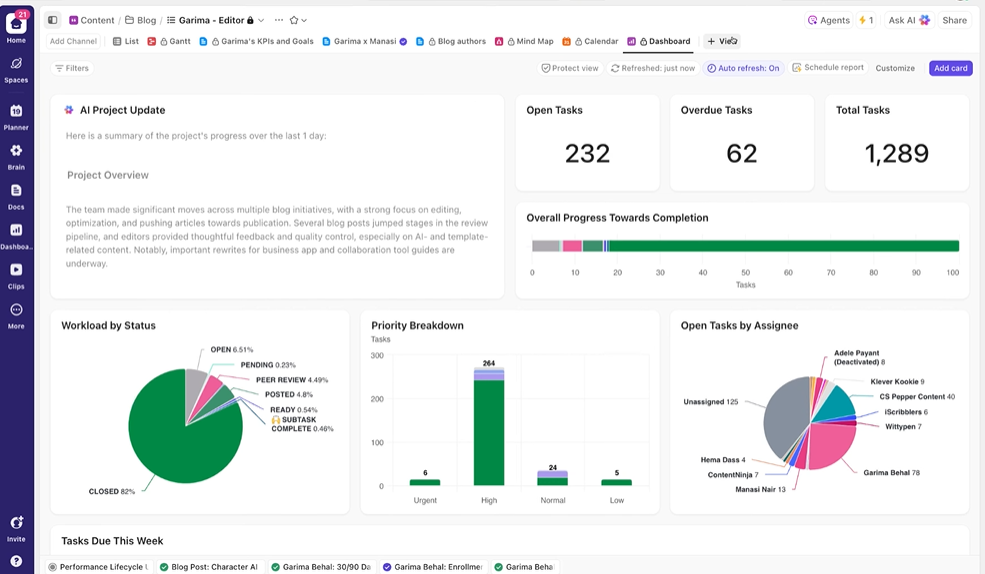
По този начин можете да се съсредоточите върху провеждането на експерименти, вместо постоянно да се налага да ги отчитате ръчно.
Превърнете AI в своя интелигентен помощник по проектите
Не е необходимо да преглеждате ръчно седмици наред данни от обучението, за да получите обобщение на експериментите до момента. Просто споменете @Brain в коментар към някоя задача и ClickUp Brain ще ви предостави необходимата помощ с пълен контекст за вашите минали и текущи проекти.
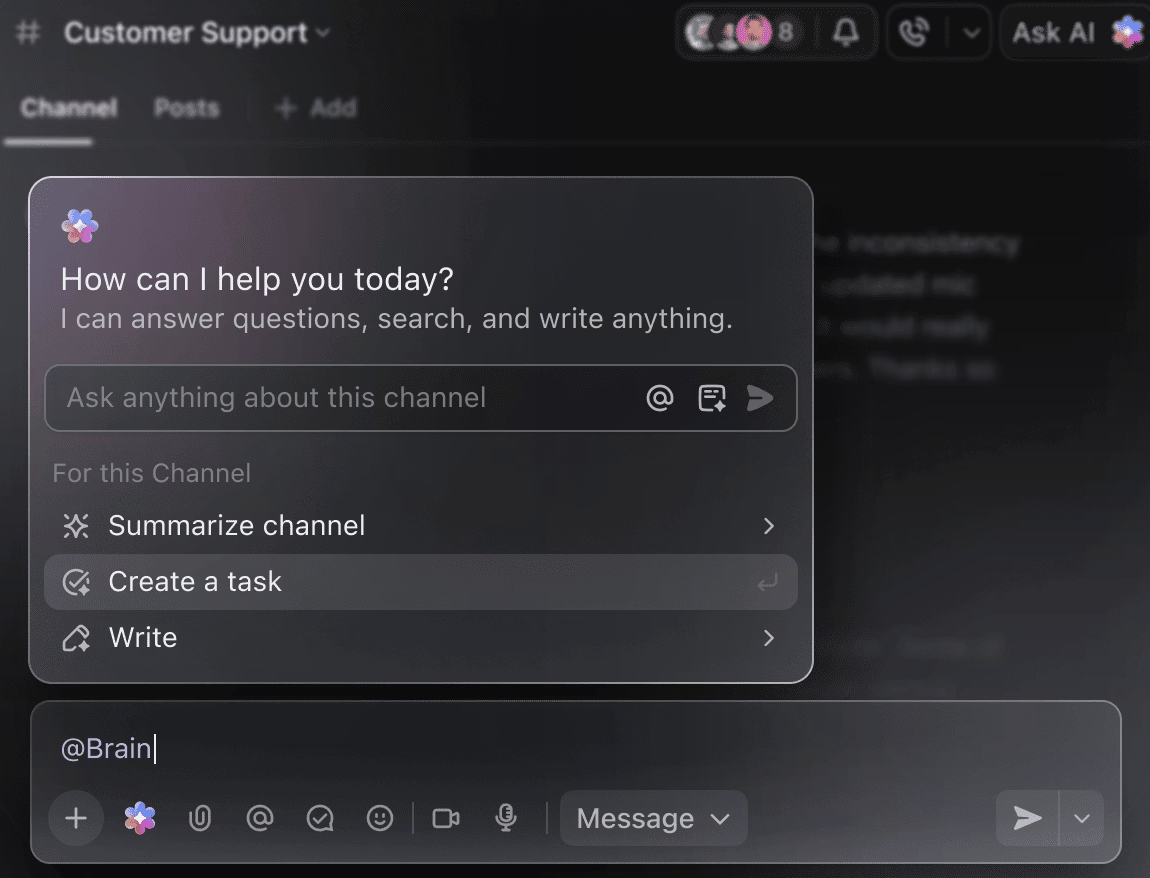
Можете да помолите Brain да „Обобщи експериментите от миналата седмица в 5 точки“ или „Напише документ с най-новите резултати от хиперпараметрите“ и веднага да получите добре изготвен резултат.
🧠 Предимството на ClickUp: Супер агентите на ClickUp отиват още по-далеч – те могат да автоматизират цели работни процеси въз основа на тригери, които вие дефинирате, а не само да отговарят на вашите въпроси. С супер агентите можете автоматично да създавате нова задача за обучение на DBRX при качване на набор от данни, да уведомявате екипа си и да свързвате съответните документи, когато обучението приключи или достигне контролна точка, както и да генерирате седмично обобщение на напредъка и да го изпращате на заинтересованите страни, без да се налага да правите нищо.
Често срещани грешки, които трябва да се избягват
Започването на проект за обучение с DBRX е вълнуващо, но няколко често срещани капана могат да попречат на напредъка ви. Избягването на тези грешки ще ви спести време, пари и много разочарования.
- Подценяване на хардуерните изисквания: DBRX е мощен, но и голям. Опитът да го стартирате на неподходящ хардуер ще доведе до грешки в паметта и неуспешни задачи за обучение. Имайте предвид, че DBRX (132B) изисква поне 264 GB VRAM за 16-битова инференция или приблизително 70-80 GB при използване на 4-битова квантизация.
- Пропускане на проверки за качеството на данните: Ако вкарате боклук, ще получите боклук. Фината настройка на разбъркан набор от данни с ниско качество ще научи модела да произвежда разбъркани резултати с ниско качество.
- Пренебрегване на ограниченията за дължина на контекста: Въпреки че 32K контекстният прозорец на DBRX е щедър, той не е безкраен. Въвеждането на данни в модела, които надвишават този лимит, ще доведе до безшумно отрязване и лоша производителност.
- Използване на Base, когато Instruct е подходящ: DBRX Base е суров, предварително обучен модел, предназначен за по-нататъшно обучение в голям мащаб. За повечето задачи, които следват инструкции, трябва да започнете с DBRX Instruct, който вече е фино настроен за тази цел.
- Разделяне на работата по обучението от координацията на проекта: Когато проследяването на експериментите се извършва в един инструмент, а планът на проекта – в друг, се създават информационни силози. Използвайте интегрирана платформа като ClickUp, за да синхронизирате техническата работа и координацията на проекта.
- Пренебрегване на оценката преди внедряване: Модел, който работи добре с вашите тренировъчни данни, може да се провали зрелищно в реалния свят. Винаги валидирайте вашия фино настроен модел на отделен тестов набор, преди да го внедрите в производството.
- Пренебрегване на сложността на фината настройка: Тъй като DBRX е модел от типа „смесица от експерти“, стандартните скриптове за фина настройка може да изискват специализирани библиотеки като Megatron-LM или PyTorch FSDP, за да се справят с разпределянето на параметрите между няколко GPU.
DBRX срещу други платформи за обучение на AI
Изборът на платформа за обучение на AI включва фундаментален компромис: контрол срещу удобство. Патентованите модели, които използват само API, са лесни за използване, но ви обвързват с екосистемата на доставчика.
Отворените модели като DBRX предлагат пълен контрол, но изискват повече технически познания и инфраструктура. Този избор може да ви накара да се почувствате затруднени, несигурни коя пътека всъщност подкрепя вашите дългосрочни цели – предизвикателство, пред което се изправят много екипи при внедряването на AI.
Тази таблица разбива основните разлики, за да ви помогне да вземете информирано решение.
| Тежести | Отворете (Персонализирано) | Собственост | Отворете (Персонализирано) | Собственост |
| Фина настройка | Пълен контрол | Базиран на API | Пълен контрол | Базиран на API |
| Самостоятелно хостинг | Да | Не | Да | Не |
| Лиценз | DB Open Model | Условия на OpenAI | Llama Community | Антропни термини |
| Контекст | 32K | 128K – 1M | 128K | 200 000 – 1 000 000 |
DBRX е правилният избор, когато се нуждаете от пълен контрол над модела, трябва да го хоствате сами за сигурност или съответствие или искате гъвкавостта на разрешителна търговска лицензия. Ако нямате специална GPU инфраструктура или цените скоростта на пускане на пазара повече от дълбоката персонализация, алтернативите, базирани на API, може да са по-подходящи.
Започнете да обучавате по-умно с ClickUp
DBRX ви предоставя готова за използване в предприятието основа за създаване на персонализирани AI приложения, с прозрачност и контрол, които не получавате от собственически модели. Ефективната му MoE архитектура поддържа ниски разходи за изводи, а отвореният му дизайн улеснява фината настройка. Но силната технология е само половината от уравнението.
Истинският успех идва от съгласуването на техническата ви работа с работния процес на екипа ви. Обучението на AI модели е екипен спорт и е от решаващо значение да се поддържа синхрон между експериментите, документацията и комуникацията със заинтересованите страни. Когато съберете всичко в едно конвергентно работно пространство и намалите разширяването на контекста, можете да създавате по-добри модели по-бързо.
Започнете безплатно с ClickUp, за да координирате вашите AI обучителни проекти в едно работно пространство. ✨
Често задавани въпроси
Можете да наблюдавате обучението, използвайки стандартни ML инструменти като TensorBoard, Weights & Biases или MLflow. Ако провеждате обучение в екосистемата на Databricks, MLflow е интегриран по подразбиране за безпроблемно проследяване на експериментите.
Да, DBRX може да бъде интегриран в стандартни MLOps пипалини. Чрез контейнеризиране на модела можете да го внедрите, използвайки платформи за оркестриране като Kubeflow или персонализирани CI/CD работни потоци.
DBRX Base е основният предварително обучен модел, предназначен за екипи, които искат да извършват продължително предварително обучение в конкретна област или дълбока архитектурна настройка. DBRX Instruct е оптимизирана версия, подходяща за следване на инструкции, което я прави по-добра отправна точка за повечето разработки на приложения.
Основната разлика е в контрола. DBRX ви дава пълен достъп до теглата на модела за дълбока персонализация и самохостинг, докато GPT-4 е услуга, достъпна само чрез API.
Тежестите на модела DBRX са достъпни безплатно съгласно лиценза Databricks Open Model License. Вие обаче носите отговорност за разходите за изчислителната инфраструктура, необходима за изпълнението или фината настройка на модела.