
Повечето разработчици, които създават скрипт за обобщаване Hugging Face, се сблъскват с една и съща пречка: обобщението работи перфектно в терминала им. Но рядко се свързва с реалната работа, която трябва да поддържа.
Това ръководство ви води през процеса на създаване на обобщител на текст с библиотеката Transformers на Hugging Face, след което ви показва защо дори и безупречната имплементация може да създаде повече проблеми, отколкото решава, когато вашият екип се нуждае от обобщения, които действително са свързани с задачи, проекти и решения.
Какво е обобщаване на текст?
Екипите се давят в информация. Срещате се с дълги документи, безкрайни стенограми от срещи, плътни изследователски доклади и тримесечни отчети, които отнемат часове, за да бъдат прегледани ръчно. Това постоянно претоварване с информация забавя вземането на решения и убива продуктивността.
Обобщаването на текст е процесът на използване на Natural Language Processing (NLP) за съкращаване на съдържанието в кратка, последователна версия, която запазва най-важната информация. Мислете за него като за мигновено резюме за всеки документ. Тази NLP технология за обобщаване обикновено използва един от два подхода:
Екстрактивно обобщаване: Този метод работи чрез идентифициране и извличане на най-важните изречения директно от изходния текст. Това е като да имате маркер, който автоматично извлича ключовите моменти за вас. Крайното обобщение е колекция от оригинални изречения.
Абстрактно обобщаване: Този по-усъвършенстван метод генерира изцяло нови изречения, за да улови основното значение на изходния текст. Той перифразира информацията, което води до по-плавно и човешко обобщение, подобно на начина, по който човек би обяснил дълга история с свои думи.
Резултатите от това се виждат навсякъде. Използва се за съкращаване на бележките от срещи до действия, обобщаване на обратната връзка от клиенти в тенденции и създаване на бързи прегледи на проектната документация. Целта е винаги една и съща: да се получи съществената информация, без да се чете всяка една дума.
📮 ClickUp Insight: Средностатистическият професионалист прекарва над 30 минути на ден в търсене на информация, свързана с работата. Това са над 120 часа годишно, загубени в ровене из имейли, Slack низове и разпръснати файлове. Интелигентен AI асистент, вграден в работното ви пространство, може да промени това. ClickUp Brain предоставя незабавни прозрения и отговори, като извежда на повърхността подходящите документи, разговори и подробности за задачите за секунди, така че да можете да спрете да търсите и да започнете да работите.
💫 Реални резултати: Екипи като QubicaAMF спестиха над 5 часа седмично с помощта на ClickUp, над 250 часа годишно на човек, като премахнаха остарелите процеси за управление на знанията.
Защо да използвате Hugging Face за обобщаване на текст?
Създаването на персонализиран модел за обобщаване на текст от нулата е огромно начинание. То изисква огромни масиви от данни за обучение, мощни и скъпи изчислителни ресурси и екип от експерти по машинно обучение. Тази висока бариера за влизане възпрепятства повечето инженерни и продуктови екипи да започнат работа по проекта.
Hugging Face е платформата, която решава този проблем. Това е платформа с отворен код за общност и наука за данни, която ви дава достъп до хиляди предварително обучени модели, ефективно демократизирайки LLM обобщенията за разработчиците. Вместо да създавате от нулата, можете да започнете с мощен модел, който вече е готов на 99%.
Ето защо толкова много разработчици се обръщат към Hugging Face: 🛠️
Достъп до предварително обучени модели: Hugging Face Hub е огромно хранилище с над 2 милиона публични модели, обучени от компании като Google, Meta и OpenAI. Можете да изтеглите и използвате тези най-съвременни контролни точки за вашите собствени проекти.
Опростен API на тръбопровода: Функцията на тръбопровода е API на високо ниво, която обработва всички сложни стъпки, като предварителна обработка на текст, извличане на модели и форматиране на изхода, само с няколко реда код.
Разнообразие на моделите: Не сте ограничени до един вариант. Можете да избирате от широка гама архитектури като BART, T5 и Pegasus, всяка от които с различни предимства, размери и характеристики на производителността.
Гъвкавост на рамката: Библиотеката Transformers работи безпроблемно с двете най-популярни рамки за дълбоко обучение, PyTorch и TensorFlow. Можете да използвате тази, с която вашият екип вече се чувства комфортно.
Подкрепа от общността: С обширна документация, официални курсове и активна общност от разработчици, лесно можете да намерите уроци и да получите помощ, когато се сблъскате с проблеми.
Макар Hugging Face да е изключително мощен инструмент за разработчиците, важно е да се помни, че това е решение, базирано на код. Необходими са технически познания за неговото внедряване и поддръжка. Това не винаги е подходящо за нетехнически екипи, които просто се нуждаят от обобщение на работата си.
🧐 Знаете ли? Библиотеката Transformers на Hugging Face направи популярно използването на най-модерни NLP модели с няколко реда код, което е причината прототипите за обобщаване често да започват оттам.
Какво представляват Hugging Face Transformers?
Решили сте да използвате Hugging Face, но каква е технологията, която стои зад него? Основната технология е архитектура, наречена Transformer. Когато беше представена в статия от 2017 г., озаглавена „Attention Is All You Need“ (Вниманието е всичко, от което се нуждаете), тя напълно промени областта на NLP.
Преди Transformers моделите се мъчеха да разберат контекста на дългите изречения. Ключовата иновация на Transformer е механизмът за внимание, който позволява на модела да преценява важността на различните думи в текста при обработката на конкретна дума. Това му помага да улавя дългосрочните зависимости и да разбере контекста, което е от решаващо значение за създаването на кохерентни обобщения.
Библиотеката Hugging Face Transformers е пакет за Python, който улеснява изключително използването на тези сложни модели. Не е необходимо да имате докторска степен по машинно обучение. Библиотеката ви спестява тежкия труд.
Трите основни компонента, които трябва да знаете
- Токенизатори: Моделите не разбират думи, а числа. Токенизаторът взема въведения от вас текст и го преобразува в поредица от числови токени – процес, наречен токенизация – които моделът може да обработи.
- Модели: Това са самите предварително обучени невронни мрежи. За обобщаване обикновено се използват модели от типа „последователност към последователност“ със структура енкодер-декодер. Енкодерът чете въведения текст, за да създаде числово представяне, а декодерът използва това представяне, за да генерира обобщението.
- Pipelines: Това е най-лесният начин да използвате модел. Pipeline обединява предварително обучен модел със съответния tokenizer и се занимава с всички стъпки по предварителната обработка на входните данни и последващата обработка на изходните данни вместо вас.
Два от най-популярните модели за обобщаване са BART и T5. BART (Bidirectional and Auto-Regressive Transformer) е особено добър в абстрактното обобщаване, като създава обобщения, които се четат много естествено. T5 (Text-to-Text Transfer Transformer) е универсален модел, който формулира всяка задача за NLP като проблем от типа „текст към текст“, което го прави мощен и многофункционален.
🎥 Гледайте това видео, за да видите сравнение между най-добрите AI PDF обобщители и да научите кои инструменти предоставят най-бързите и най-точни обобщения, без да губят контекста.
Как да създадете обобщител на текст с Hugging Face
Готови ли сте да създадете свой собствен пример за обобщител? Всичко, от което се нуждаете, е малко основни познания по Python, редактор на код като VS Code и интернет връзка. Целият процес отнема само четири стъпки. За минути ще имате работещ обобщител.
Стъпка 1: Инсталирайте необходимите библиотеки
Първо, трябва да инсталирате необходимите библиотеки. Основната е transformers. Ще ви е необходима и платформа за дълбоко обучение като PyTorch или TensorFlow. В този пример ще използваме PyTorch.
Отворете терминала или командния ред и изпълнете следната команда:

Някои модели, като T5, също изискват библиотеката sentencepiece за своя токенизатор. Добре е да я инсталирате също.

💡 Съвет от професионалист: Създайте виртуална среда Python, преди да инсталирате тези пакети. Това ще изолира зависимостите на вашия проект и ще предотврати конфликти с други проекти на вашия компютър.
Стъпка 2: Заредете модела и токенизатора
Най-лесният начин да започнете е да използвате функцията pipeline. Тя автоматично се занимава с зареждането на правилния модел и токенизатор за задачата по обобщаване.
В Python скрипта си импортирайте тръбопровода и го инициализирайте по следния начин:

Тук уточняваме две неща:
Задачата: Казваме на тръбопровода, че искаме да извършим „обобщение”.
Моделът: Избираме конкретен предварително обучен модел от Hugging Face Hub. facebook/bart-large-cnn е популярен избор, обучен на новинарски статии и работи добре за обобщения с общо предназначение. За по-бързо тестване можете да използвате по-малък модел като t5-small.
Когато изпълните този код за първи път, той ще изтегли теглата на модела от Hub, което може да отнеме няколко минути. След това моделът ще бъде кеширан на вашия локален компютър за незабавно зареждане.
Стъпка 3: Създайте функцията за обобщаване
За да направите кода си чист и повторно използваем, най-добре е да обвържете логиката на обобщаването във функция. Това също улеснява експериментирането с различни параметри.
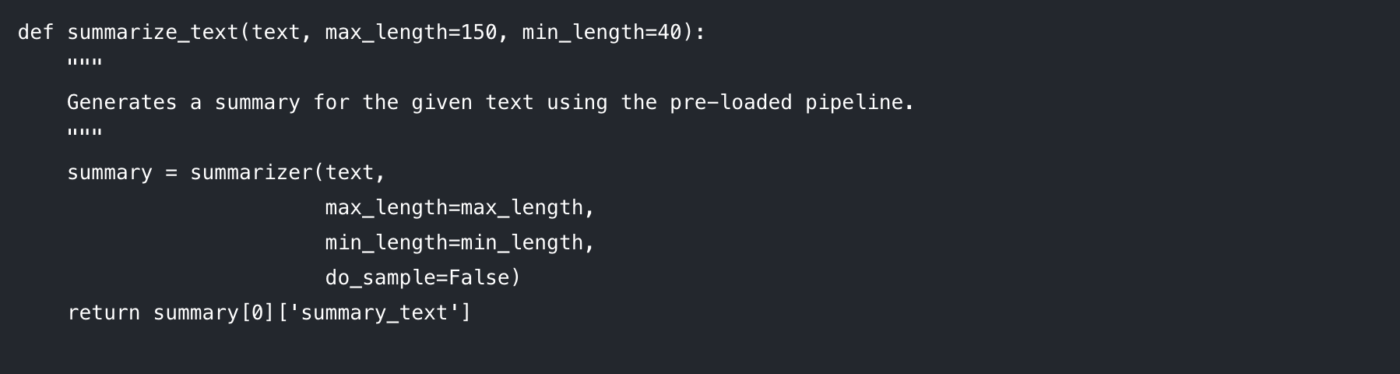
Нека разгледаме параметрите, които можете да контролирате:
max_length: Това определя максималния брой символи (приблизително думи) за изходния обобщаващ текст.
min_length: Това задава минималния брой символи, за да се предотврати генерирането на прекалено къси или празни обобщения от модела.
do_sample: Когато е настроено на False, моделът използва детерминистичен метод (като beam search) за генериране на най-вероятното обобщение. Настройката на True въвежда случайност, която може да доведе до по-креативни, но по-малко предсказуеми резултати.
Настройването на тези параметри е ключово за получаване на желаното качество на резултата.
Стъпка 4: Генерирайте обобщението си
А сега идва забавната част. Предайте текста си на функцията и отпечатайте резултата. 🤩

Трябва да видите съкратена версия на статията, отпечатана на вашата конзола. Ако срещнете проблеми, ето няколко бързи решения:
Въведеният текст е прекалено дълъг: Моделът може да отчете грешка, ако въведеният текст надвиши максималната дължина (често 512 или 1024 символа). Добавете truncation=True в summarizer(), за да отрежете автоматично дългите въведени текстове.
Резюмето е твърде общо: Опитайте да увеличите параметъра num_beams (например num_beams=4). Това кара модела да търси по-обстойно по-добро резюме, но може да бъде малко по-бавно.
Този подход, базиран на код, е фантастичен за разработчиците, които създават персонализирани приложения. Но какво се случва, когато трябва да го интегрирате в ежедневната работа на екипа? Тогава започват да се проявяват ограниченията.
Ограничения на Hugging Face за обобщаване на текст
Hugging Face е чудесен вариант, когато искате гъвкавост и контрол. Но щом опитате да го използвате за реални работни процеси в екип (а не само за демонстрационен бележник), бързо се появяват няколко предвидими предизвикателства.
Ограничения на токените и главоболия с дълги документи
Повечето модели за обобщаване имат фиксирана максимална дължина на входните данни. Например, facebook/bart-large-cnn е конфигуриран с max_position_embeddings = 1024. Това означава, че по-дългите документи често изискват съкращаване или разделяне на части.
Ако имате нужда само от бърза базова линия, можете да активирате съкращаването в процеса и да продължите напред. Но ако имате нужда от точни обобщения на дълги документи, обикновено се налага да създадете логика за разделяне на части и след това да направите втори преглед, „обобщение на обобщенията“, за да съедините резултатите. Това е допълнителна инженерна работа и лесно може да се получи несъвместим резултат.
Риск от халюцинации (и такса за проверка)
Абстрактните модели понякога могат да халюцинират, генерирайки текст, който звучи правдоподобно, но всъщност е неточен. За критични за бизнеса приложения това създава проблем: всяко обобщение се нуждае от ръчна проверка. В този момент вие всъщност не спестявате време, а просто прехвърляте работата към друга част от процеса.
Липса на контекстуална осведоменост
Моделът Hugging Face знае само за текста, който му предоставяте. Той не разбира целите на вашия проект, хората, които участват в него, или как един документ се отнася към друг, като му липсва контекстуалната интелигентност на съвременните системи. Той не може да ви каже дали обобщението от разговор с клиент противоречи на документа с изискванията на проекта, защото съществува изолирано.
Допълнителни разходи за интеграция (проблемът с „последната миля“)
Създаването на обобщение обикновено е лесната част. Истинското затруднение е това, което следва след това.
Къде отива обобщението? Кой го вижда? Как се превръща в задача, която може да се изпълни? Как го свързвате с работата, която го е предизвикала?
Решаването на този „последния етап“ означава създаване на персонализирани интеграции и свързващ код. Това добавя работа за разработчиците в началото и често създава тромав работен процес за всички останали.
Технически бариери и текуща поддръжка
Подходът, базиран на Python, е достъпен предимно за хора, които могат да програмират. Това създава практическа бариера за екипите по маркетинг, продажби и операции, което означава, че приложението остава ограничено.
Той включва и текуща поддръжка: управление на зависимости, актуализиране на библиотеки и поддържане на всичко в работно състояние, докато API и моделите се развиват. Това, което започва като бърза печалба, може тихо да се превърне в още една система, за която трябва да се грижите.
📮 ClickUp Insight: 42% от прекъсванията в работата се дължат на жонглиране с платформи, управление на имейли и преминаване от една среща към друга. Ами ако можехте да елиминирате тези скъпоструващи прекъсвания? ClickUp обединява вашите работни потоци (и чат) в една единствена, оптимизирана платформа. Стартирайте и управлявайте задачите си от чат, документи, бели дъски и др., докато функциите, задвижвани от изкуствен интелект, поддържат контекста свързан, достъпен за търсене и управляем.
По-големият проблем: разширяване на контекста
Дори ако скриптът ви за обобщаване работи перфектно, екипът ви все пак може да губи време, защото резултатът е отделен от мястото, където действително се извършва работата.
Това е разширяване на контекста, когато екипите губят часове в търсене на информация, превключване между приложения и търсене на файлове в несвързани платформи.
Тук е мястото, където конвергентното работно пространство променя играта. Вместо да генерирате обобщения на едно място и да се опитвате да ги „преместите в работата“ по-късно, конвергентната система съхранява проекти, документи и разговори заедно, с ClickUp Brain, вграден като интелигентен слой. Вашите обобщения остават свързани със задачите и документите, така че следващата стъпка е очевидна, а предаването е незабавно.
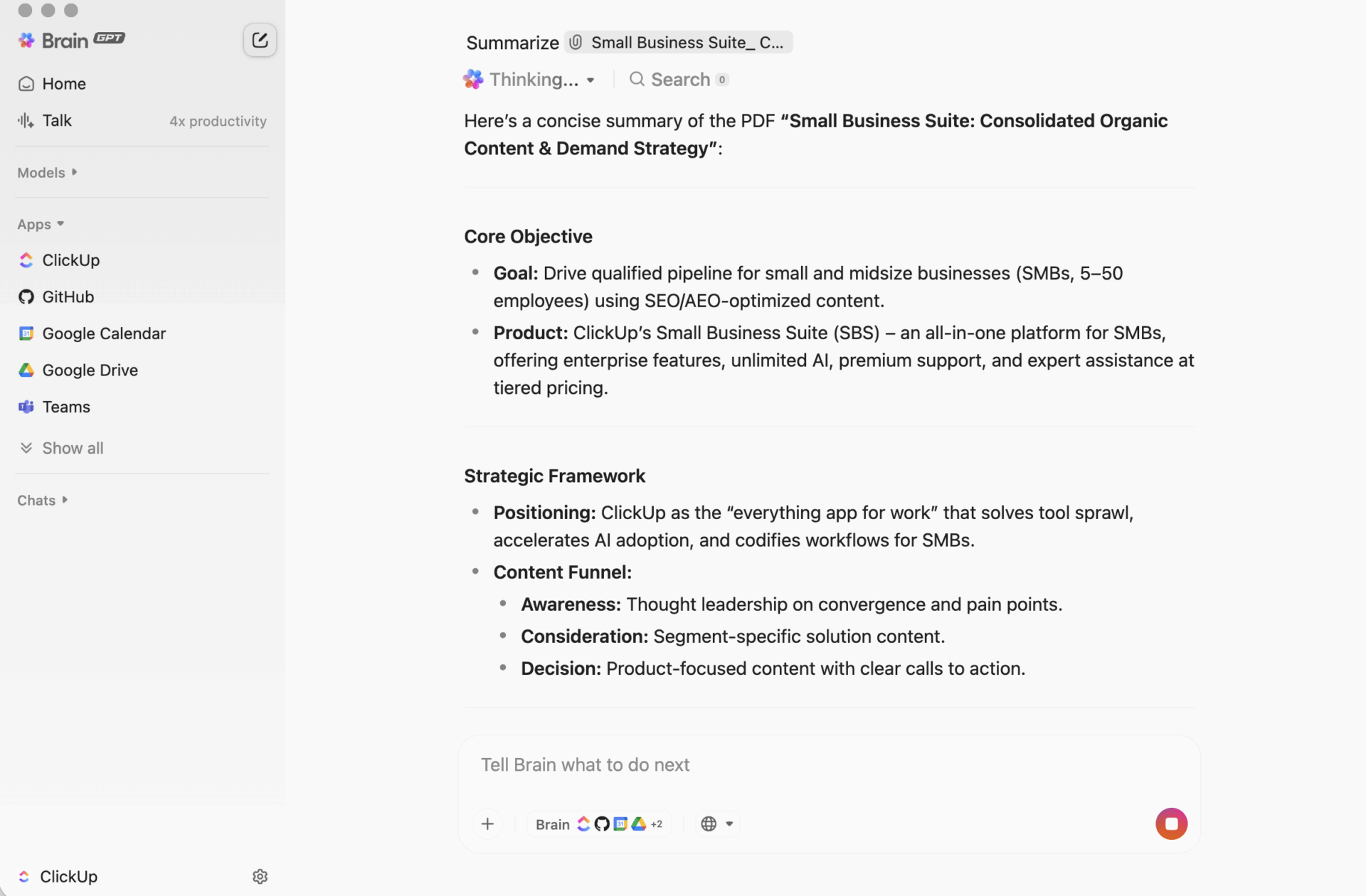
Обобщение, което се превръща в действие с ClickUp
Скриптът за обобщаване може да работи перфектно, но все пак да подведе екипа ви по един досаден начин: обобщението в крайна сметка се оказва отделено от работата.
Тази празнина създава разпръскване на контекста, при което информацията е разпръсната в документи, чат низове, задачи и „бързи бележки“ в инструменти, които не са свързани помежду си. Хората прекарват повече време в търсене на обобщението, отколкото в използването му. Истинската полза не е само в създаването на обобщение. Тя е в запазването на това обобщение свързано с решения, отговорни лица и следващи стъпки там, където действително се извършва работата.
Това е разликата в работата на ClickUp Brain. Той обобщава задачи, документи и разговори в същото работно пространство, където се намират вашите проекти, така че вашият екип може да разбере нещо и да действа, без да преминава към други инструменти.

ClickUp BrainGPT: взаимодействайте с обобщенията, използвайки естествен език
На настолен компютър BrainGPT е интерфейсът за разговор за ClickUp Brain. Вместо да отваряте скриптове, бележници или външни AI инструменти, вашият екип може да поиска това, от което се нуждае, на прост език, директно в ClickUp.
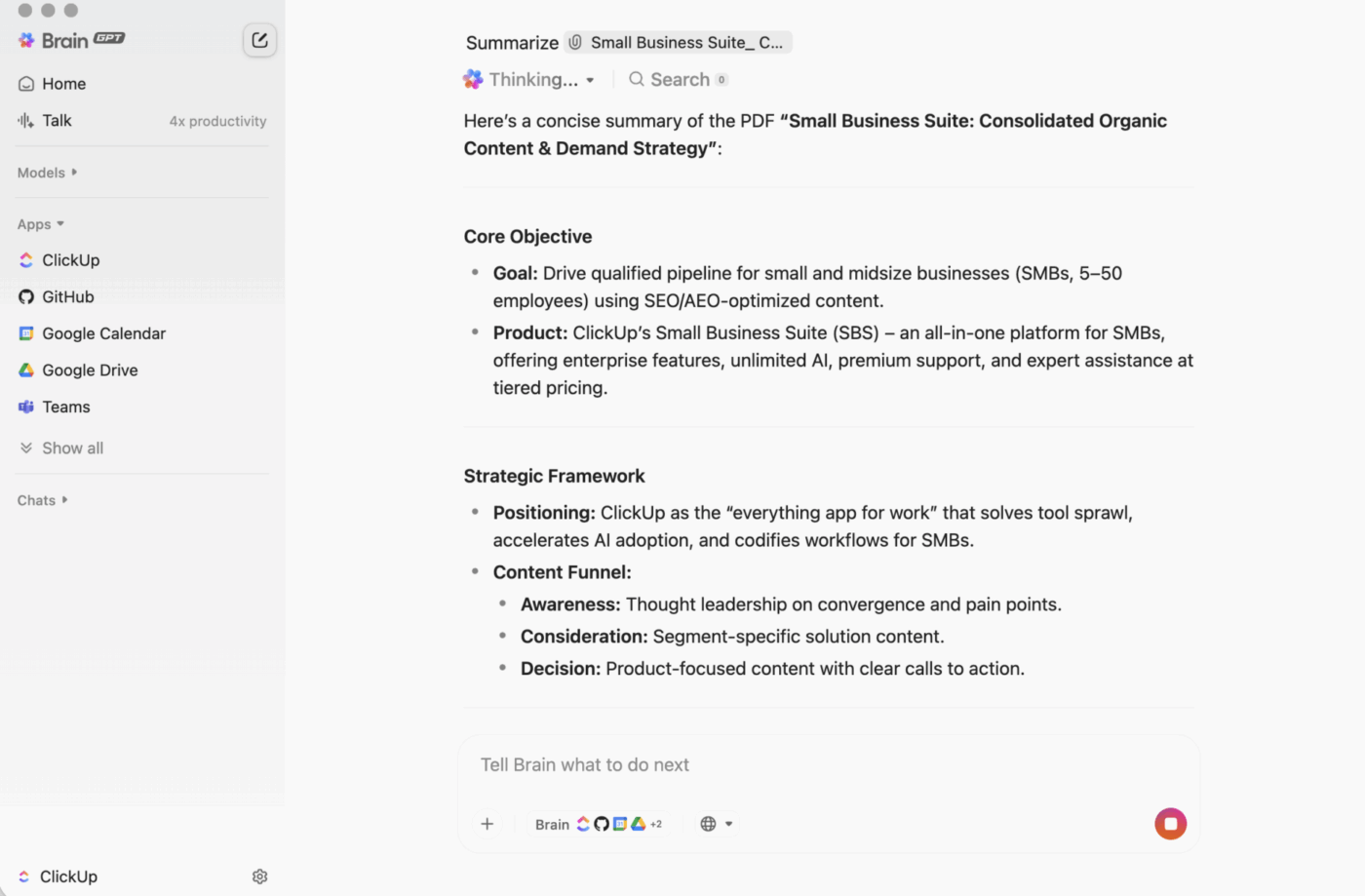
Можете да пишете (или да използвате функцията „говори, за да пишеш“) за да:
- Обобщете дълго описание на задача, коментарна нишка или документ.
- Продължете с въпроси като „Какви са следващите стъпки?“ или „Кой отговаря за това?“
- Превърнете обобщението в действие, като създадете задачи от него, с отговорници и крайни срокове.
Тъй като ClickUp Brain работи във вашето работно пространство, резултатът се основава на контекста в реално време: описания на задачи, коментари, подзадачи, свързани документи и структура на проекта. Не е необходимо да поставяте текст в отделен инструмент и да се надявате, че нищо важно няма да бъде пропуснато.
Защо това е по-добро от работния процес на обобщаване на базата на код за повечето екипи
Работният процес, създаден от разработчици, може да генерира силни обобщения. Сблъсъкът се проявява след това, когато някой трябва да копира резултата на мястото, където се извършва работата, след това да го превърне в задачи и да проследи изпълнението им.
ClickUp Brain затваря този цикъл:
Не се изисква кодиранеВсеки член на екипа може да обобщи документ, нишка със задачи или хаотичен набор от коментари, без да инсталира нищо или да пише код.
Резюмета, съобразени с контекстаClickUp Brain може да включва частите, които хората обикновено забравят: решения, скрити в коментари, пречки, споменати в отговори, подзадачи, които променят значението на „завършено“.
Резюметата са там, където се извършва работатаМожете да се запознаете с задачата, да добавите резюме в горната част на ClickUp Docs или бързо да обобщите дискусията, без да създавате друг „документ с резюме“, който никой не проверява.
По-малко разпръснати инструментиНе се нуждаете от отделни скриптове, Jupyter бележници, API ключове или работни процеси, които само един човек разбира. Вашите документи, задачи и обобщения остават в една и съща система.
Това е практическото предимство на конвергентното работно пространство: обобщаването, действието и сътрудничеството се случват едновременно, вместо да се съединяват след факта.
Това е практическото предимство на конвергентното работно пространство: обобщаването, действието и сътрудничеството се случват едновременно, вместо да се съединяват след факта.
Как работи в реалния живот
Ето няколко често използвани модели от екипите:
- Обобщете коментарите: отворете задача с дълга дискусия, кликнете върху опцията AI и получите бърз преглед на промените и важните моменти.
- Обобщете документ: отворете ClickUp Doc и използвайте „Ask AI“, за да генерирате обобщение на страницата, така че всеки да може бързо да се ориентира.
- Извлечете действия: вземете обобщението и незабавно превърнете следващите стъпки в задачи с отговорни лица и крайни срокове, за да не се загуби инерцията при предаването.
| Възможности | Hugging Face (базиран на код) | ClickUp Brain |
|---|---|---|
| Необходима настройка | Python среда, библиотеки, кодиране | Няма, вграден |
| Осъзнаване на контекста | Само текст (това, което въвеждате) | Пълен контекст на работното пространство (задачи, документи, коментари, подзадачи) |
| Интеграция на работния процес | Ръчно експортиране/импортиране | Нативни: обобщенията могат да се превърнат в задачи и актуализации |
| Необходими технически умения | Ниво разработчик | Всеки член на екипа |
| Поддръжка | Непрекъснато поддържане на модела и кода | Автоматични актуализации |
От обобщенията до изпълнението с Super Agents
Резюметата са полезни. Трудното е да се гарантира, че те последователно се превръщат в последващи действия, особено когато обемът се увеличава.
Тук на помощ идват ClickUp Super Agents . Те могат да използват обобщената информация и да продължат работата въз основа на тригери и условия в същото работно пространство.
С Super Agents екипите могат:
- Обобщавайте промените по график (седмично обобщение на проекта, ежедневни отчети за състоянието)
- Извличайте действия и възлагайте отговорници автоматично
- Отбележете забавената работа (задачи, заседнали в процес на преглед, неотговорени теми, просрочени следващи стъпки)
- Поддържайте висока видимост на лидерството без ръчно отчитане
Вместо обобщението да остава статичен текст, агентите помагат да се гарантира, че обобщението се превръща в план, а планът – в напредък.
Обобщаване, което живее там, където се извършва работата
Hugging Face Transformers са чудесни, когато се нуждаете от персонализирано приложение, специално създаден процес или пълен контрол над поведението на модела.
Но за повечето екипи по-големият проблем не е „Можем ли да обобщим това?“, а „Можем ли да обобщим това и веднага да го превърнем в работа, с отговорници, срокове и видимост?“.
Ако целта ви е продуктивност на екипа и бързо изпълнение, ClickUp Brain ви предоставя обобщения в контекст, точно там, където се извършва работата, с ясен път от „ето същността“ до „ето какво правим след това“.
Готови ли сте да пропуснете настройките и да започнете да обобщавате там, където се извършва вашата работа? Започнете безплатно с ClickUp и оставете Brain да се погрижи за тежките задачи.