

Часът е 3 сутринта.
Пронизителна аларма ви събужда.
Скачате на крака, привлечени от светлината на екрана на компютъра си. Критична система е извън строя. Паниката се настанява. Това не е сцена от научнофантастичен трилър, а кошмарен сценарий за всеки ИТ специалист.
Но това е и реалност. Когато цифровият свят застине, натискът е огромен.
Тук управлението на инциденти се превръща в спасителна въже.
Управлението на инциденти е ключът към бързото справяне и разрешаване на прекъсвания в проектите. Чрез ефективното управление на тези прекъсвания можете да се съсредоточите повече върху постигането на резултати и ефективното завършване на проекта си.
В тази статия ще разгледаме процеса на управление на инциденти и ще споделим най-добрите практики, които ще ви помогнат да внедрите надежден план за действие при извънредни ситуации. Това ще ви гарантира, че ще можете ефективно да се справяте с всички бъдещи инциденти по проектите.
Разбиране на управлението на инциденти
Инцидентите са смущения или потенциални заплахи, които оказват влияние върху качеството на услугата. Например, бизнес приложение, което се срива, или уеб сървър, който работи бавно, което води до проблеми с производителността, се считат за инциденти. Тези събития могат да варират от незначителни проблеми, засягащи няколко потребители, до големи прекъсвания, засягащи глобални услуги.
Управлението на инциденти е процесът на идентифициране, приоритизиране и разрешаване на ИТ проблеми, за да се минимизират прекъсванията в бизнес операциите, като същевременно се прилагат мерки за предотвратяване на бъдещи инциденти. Този процес на проактивно предотвратяване на инциденти е от жизненоважно значение за всяка организация, тъй като прекъсванията в услугата могат да доведат до значителни бизнес загуби. Ефективното управление на инциденти позволява на екипите да приоритизират и разрешават проблемите бързо, като по този начин осигуряват по-добра непрекъснатост на услугата.
При справянето с инциденти екипите се нуждаят от добре дефиниран план, който да им помогне да:
- Реагирайте незабавно , за да сведете до минимум прекъсванията в работата
- Комуникирайте ефективно с клиенти, заинтересовани страни, собственици на услуги и други заинтересовани страни.
- Сътрудничество безпроблемно за ускоряване на решаването на проблеми и премахване на пречките пред разрешаването им
- Постоянно се усъвършенствайте, като се учите от инцидентите и прилагате тези уроци, за да подобрите качеството на обслужването и да усъвършенствате процесите.
В тази рамка е от съществено значение и да знаете как да изготвяте доклад за инцидент. Подробните доклади за инциденти улесняват задълбочения анализ, идентифицират основните причини и разработват превантивни стратегии.
Връзката между управлението на инциденти, ITSM и DevOps
Управлението на инциденти е основен компонент на управлението на ИТ услугите (ITSM), който гарантира, че ИТ услугите остават достъпни и надеждни. Междувременно DevOps интегрира екипите за разработка и операции, за да подобри сътрудничеството и ефективността.
Съгласуването на управлението на инциденти с принципите на управление на проекти DevOps може да помогне на организациите да реагират бързо и ефективно на инциденти. Това съгласуване насърчава непрекъснатото усъвършенстване, по-бързото възстановяване след инциденти и подобреното предоставяне на услуги.
Разбиране на процесите на управление на инциденти
Ефективният процес на управление на инциденти позволява на ИТ екипите да разследват, документират и разрешават ефективно прекъсвания или спирания на услугите.
Различните компании често възприемат различни видове процеси за управление на инциденти, съобразени с техните специфични нужди. Тъй като няма универсален подход, ще откриете разнообразни методологии в различните организации.
Някои екипи се придържат към традиционните процеси за управление на инциденти в ИТ, като например тези, описани в сертификатите на Information Technology Infrastructure Library (ITIL). Други предпочитат по-скоро подход, ориентиран към Site Reliability Engineering (SRE) или DevOps.
Работният процес за управление на инциденти по ITIL се фокусира върху намаляване на прекъсванията и смекчаване на въздействието на инцидентите върху производителността на служителите. Използвайки шаблони за доклади за инциденти, екипите могат да създадат повтарящ се работен процес за регистриране, диагностициране и разрешаване на инциденти, като същевременно поддържат изчерпателни записи за своите дейности.
ITIL рамката се използва предимно от ИТ екипи, които управляват услуги в рамките на бизнеса. Тези екипи често адаптират обширното покритие на ITIL на инциденти и процеси, за да отговарят на техните нужди.
ITIL е особено полезен за създаването на култура на проактивно отстраняване на проблеми. Неговите структурирани процеси помагат на екипите да проследяват последователно инцидентите и действията, подобрявайки отчитането и анализа, което в крайна сметка води до по-стабилни услуги и ефективни екипи.
Изкуствен интелект и машинно обучение в управлението на инциденти
Интегрирането на изкуствен интелект и машинно обучение в управлението на инциденти променя начина, по който екипите се справят с инциденти. Инструментите, задвижвани от изкуствен интелект, могат да анализират огромни количества данни, за да предскажат потенциални инциденти, преди те да се случат, което позволява да се вземат превантивни мерки.
Алгоритмите за машинно обучение могат да идентифицират модели и аномалии, които човешките анализатори могат да пропуснат, предоставяйки по-задълбочени познания за основните причини и потенциалните решения. Тези технологии могат също да автоматизират рутинни задачи, като регистриране на инциденти и първоначална диагностика, освобождавайки човешките ресурси за решаване на по-сложни проблеми.
Висока наличност и прекъсвания в управлението на инциденти
Минимизирането на прекъсванията е от решаващо значение за ефективното управление на инциденти. Високата наличност гарантира, че системите са оперативни и достъпни по всяко време, минимизирайки риска от прекъсвания на услугата. За постигане на висока наличност се използват резервираност, механизми за прехвърляне при отказ и балансиране на натоварването.
Намаляването на прекъсванията е от решаващо значение за поддържането на производителността и удовлетвореността на клиентите. Процесите за управление на инциденти трябва да включват надеждни планове за бърза реакция и възстановяване, за да се сведе до минимум продължителността и въздействието на прекъсванията.
Процесът на управление на ИТ инциденти в подробности
Управлението на инциденти включва ефективно идентифициране, регистриране, категоризиране, приоритизиране и разрешаване на инциденти.
Разбирането на тези стъпки помага да се гарантира систематичен подход към управлението на инциденти, минимизиране на прекъсванията и предотвратяване на бъдещи инциденти.
Стъпки в процеса на управление на ИТ инциденти
1. Идентифицирайте и регистрирайте инцидента
Инцидентите могат да възникнат от различни източници, включително служители, клиенти, доставчици или системи за мониторинг. Първата стъпка включва идентифициране и регистриране на инцидента. Тези регистри, често наричани билети за инциденти, обикновено включват:
- Името на лицето, което съобщава инцидента
- Дата и час на съобщаване на инцидента
- Описание на инцидента с подробна информация за това какво не функционира правилно или не работи
- За целите на проследяването се присвоява уникален идентификационен номер.
2. Категоризирайте инцидента
От решаващо значение е всеки инцидент да бъде класифициран в логична и интуитивна категория (и подкатегория, ако е необходимо). Тази категоризация помага при анализирането на данни за тенденции и модели, което е от съществено значение за ефективното управление на проблеми и предотвратяването на инциденти в бъдеще.
3. Приоритизирайте инцидента
Всеки инцидент трябва да бъде приоритизиран въз основа на неговото въздействие върху бизнеса, броя на засегнатите лица, съответните SLA и потенциалните финансови, свързани със сигурността и съответствието последици.
Отговорните екипи определят относителната му приоритетност, като го сравняват с други отворени инциденти. Предварителното определяне на нивата на сериозност и приоритетност е най-добрата практика, която позволява на мениджърите на инциденти да оценят бързо приоритета.
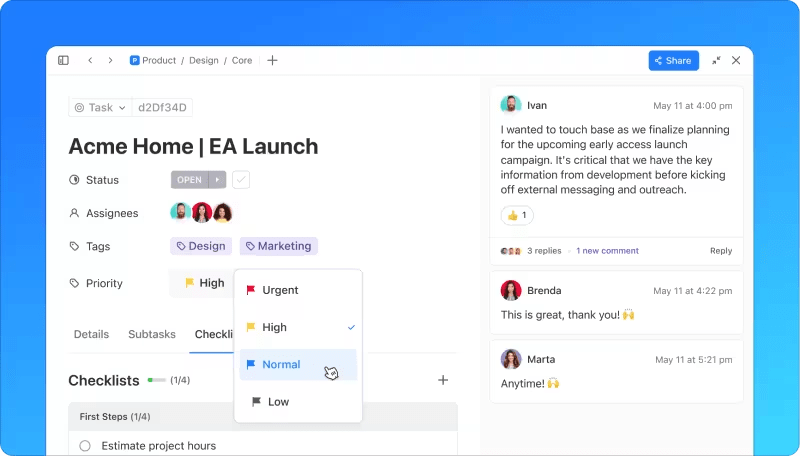
4. Реагирайте на инцидента
Фазата на реагиране включва няколко ключови действия:
- Първоначална диагностика: В идеалния случай екипът за поддръжка на първа линия диагностицира и разрешава инцидента. Ако не може да го направи, той записва цялата необходима информация и я предава на екипа от следващото ниво.
- Ескалация: Следващият екип продължава процеса на диагностика. Ако не успеят да разрешат инцидента, те го ескалират.
- Комуникация: Редовни актуализации се споделят с засегнатите вътрешни и външни заинтересовани страни.
- Разследване и диагностика: Тази фаза продължава, докато не бъде установена същността на инцидента. Екипите могат да привлекат външни ресурси или членове от други отдели, за да помогнат за разрешаването на проблема.
- Решаване и възстановяване: След диагностициране екипът изпълнява необходимите стъпки за решаване на инцидента. Възстановяването включва времето, необходимо за пълното възстановяване на операциите, тъй като някои поправки, като например пачове за бъгове, може да се наложи да бъдат тествани и внедрени дори след решаването на проблема.
- Затваряне: Ако инцидентът е ескалиран, той се връща на сервизния център за затваряне. Само служителите на сервизния център могат да затварят инциденти, като по този начин се гарантира качеството и удовлетвореността на клиентите.
Управление на инциденти за DevOps и SRE екипи
Подходите DevOps и SRE придобиха огромна популярност, особено с възхода на постоянно активните облачни услуги, глобално достъпните уеб приложения, микроуслугите и решенията „софтуер като услуга“ (SaaS).
Съвременният софтуер, който е от критично значение за лична и професионална употреба, рядко се хоства на локален сървър. Вместо това тези приложения обикновено се разгръщат в центрове за данни, обслужващи хиляди или милиони потребители по целия свят. Гъвкавостта и бързината са от решаващо значение за екипите, отговорни за поддържането на тези услуги. Всяко прекъсване на работата може да има далекосъщителни последствия, засягащи едновременно множество организации.
Философията „ти го създаваш, ти го управляваш“ предлага на гъвкавите екипи необходимата гъвкавост. Но тя може също така да замъгли границите на отговорността. Макар че DevOps екипите могат да процъфтяват с по-малко строги процеси на разработка, е от съществено значение да се стандартизират основните практики за управление на инциденти:
Споделени отговорности при дежурства
За разлика от традиционните модели, при които определени членове на екипа са определени за дежурни експерти, DevOps екипите обикновено прилагат ротационен график за дежурства. Този подход гарантира, че всички членове на екипа са отговорни за реагиране на инциденти, включително такива, които могат да възникнат извън редовното работно време.
Запознатостта води до разрешаване на проблемите
В основата на философията на DevOps е убеждението, че инженерите, които са разработили дадена услуга, са в най-добра позиция да разрешават възникналите проблеми. Този принцип подчертава менталността „ти го създаваш, ти го управляваш“, при която хората, които са най-запознати с архитектурата и сложността на услугата, се занимават с прекъсванията и смущенията.
Скорост и отговорност
DevOps екипите трябва да създават и внедряват софтуер бързо. Но тази бързина е съпроводена с допълнителна отговорност. Знаейки, че ще трябва да разрешават инциденти, инженерите са мотивирани да създават висококачествен и надежден код.
Анализът на основните причини (RCA) също е от съществено значение в управлението на инциденти в DevOps. RCA включва идентифициране на основните причини за инцидентите, което позволява на екипите да прилагат практични решения и да предотвратяват повторението им.
Това е проактивен подход, който се занимава с неотложни проблеми и укрепва цялостната система, като намалява вероятността от бъдещи сериозни инциденти и подобрява устойчивостта на услугите.
Чрез поддържане на непрекъснат и съгласуван поток в практиките за управление на инциденти, екипите на DevOps могат да балансират гъвкавостта и структурата. Това гарантира, че те са добре подготвени да се справят с инциденти бързо и ефективно, което води до по-надеждни и стабилни софтуерни услуги.
Роли в управлението на инциденти
Въпреки че организациите могат да адаптират ролите и отговорностите си в зависимост от конкретните си нужди, ето някои от най-разпространените роли в екипите за управление на ИТ инциденти:
- Краен потребител/заявител: Това обикновено е лицето, което е засегнато от прекъсване на услугата и е отговорно за стартиране на процеса на управление на инциденти чрез подаване на билет за инцидент.
- Сервизен център от ниво 1: Сервизният център от ниво 1 е първоначалната точка за контакт за заявителите. Техниците се занимават с основни проблеми и заявки. Техните познания обхващат често срещани проблеми, като например възстановяване на пароли и проблеми с връзката, например проблеми с Wi-Fi.
- Сервизен център от ниво 2: Техниците на това ниво притежават по-напреднали умения и знания от тези на ниво 1. Те се занимават с по-сложни проблеми и обработват ескалации от ниво 1. Тяхната роля включва разрешаване на сложни технически проблеми и осигуряване на ефективно разрешаване на инциденти.
- Сервизен център от ниво 3 и по-високо: Това ниво включва специалисти с дълбоки познания в конкретни области на ИТ инфраструктурата, като поддръжка на хардуер или сървъри.
- Мениджър по инциденти: Мениджърът по инциденти наблюдава процеса на управление на инциденти, оценява неговата ефективност, предлага подобрения и гарантира спазването на установените процедури.
- Отговорен за процеса: Отговорният за процеса контролира и усъвършенства процеса на управление на инциденти. Той анализира, коригира и подобрява процеса, за да гарантира, че той е в съответствие с целите на организацията и подпомага оптимално усилията за управление на инциденти.
Тези роли допринасят колективно за добре структуриран и ефективен процес на идентифициране и управление на инциденти, като осигуряват бързо и ефективно разрешаване на инциденти и непрекъснато подобряване на подхода.
Прочетете също: Как да напишете добър доклад за грешка (с примери и шаблони)
Инструменти и ресурси за ефективно управление на инциденти
Използването на подходящи инструменти и ресурси за управление на инциденти може значително да повиши ефективността и ефикасността на процеса на управление на инциденти.
Уеб браузърите, и по-специално Google Chrome, са от ключово значение за управлението на инциденти. Многофункционалността на Chrome и съвместимостта му с различни уеб-базирани софтуери за управление на инциденти го правят незаменим инструмент за ИТ екипите. Богатата му библиотека от разширения, като инструменти за разработчици, програми за проследяване на грешки и монитори за производителност, позволява диагностика и отстраняване на проблеми в реално време.
Освен това, извличането на артефакти като кеш данни, история, изтеглени файлове и др. чрез браузър криминалистика помага на екипите да идентифицират възможни източници на вирусни атаки и злонамерен код.
Chrome се интегрира безпроблемно с ClickUp, високо оценена софтуерна платформа за управление на продуктивността и инцидентите, използвана от екипи в малки и големи компании.
Ето някои от значителните предимства на използването на ClickUp за управление на инциденти:
1. Централизирано проследяване на инциденти
ClickUp консолидира цялата информация, свързана с инциденти, в една платформа. Този централизиран подход гарантира, че всички доклади за инциденти, актуализации и решения са достъпни на едно място, което намалява риска от загуба на информация и гарантира, че членовете на екипа имат най-актуалните данни на разположение.
2. Сътрудничество в реално време
Функциите за сътрудничество на ClickUp улесняват безпроблемната комуникация между членовете на екипа. Потребителите могат да коментират директно задачите, да споделят файлове и да актуализират статуса на инцидентите в реално време с помощта на ClickUp Chat. Тази функция е от полза за екипи, които работят на различни места или в различни часови зони, като гарантира, че всички са информирани и съгласувани.

3. Автоматизирано управление на работния процес
ClickUp Automations помага за създаването на автоматизирани работни процеси, които задействат конкретни действия въз основа на предварително определени условия. Например, когато бъде докладван инцидент, могат да бъдат изпратени автоматични известия до съответните членове на екипа и да бъдат възложени задачи въз основа на типа инцидент. Това намалява ръчния труд и ускорява разрешаването на инцидентите.
4. Интегрирано отчитане и анализи
Платформата предоставя надеждни инструменти за отчитане и анализ, които помагат за наблюдение на тенденциите при инцидентите и показателите за ефективност. Екипите могат да генерират подробни отчети за приоритизиране на инциденти, време за разрешаване на инциденти, честота на повторение и други ключови показатели за ефективност. Този подход, основан на данни, помага за идентифициране на модели, оценяване на ефективността на стратегиите за реагиране и вземане на информирани решения за подобряване на процесите за управление на инциденти.
5. Персонализирани табла
Платформата ви позволява да създавате персонализирани табла, които показват важни показатели за управление на инциденти и KPI. Таблата на ClickUp предоставят визуален преглед на текущите инциденти, задачите в процес на изпълнение и ефективността на екипа, което позволява на мениджърите бързо да оценят текущото състояние на управлението на инциденти и да се справят с евентуални проблеми.
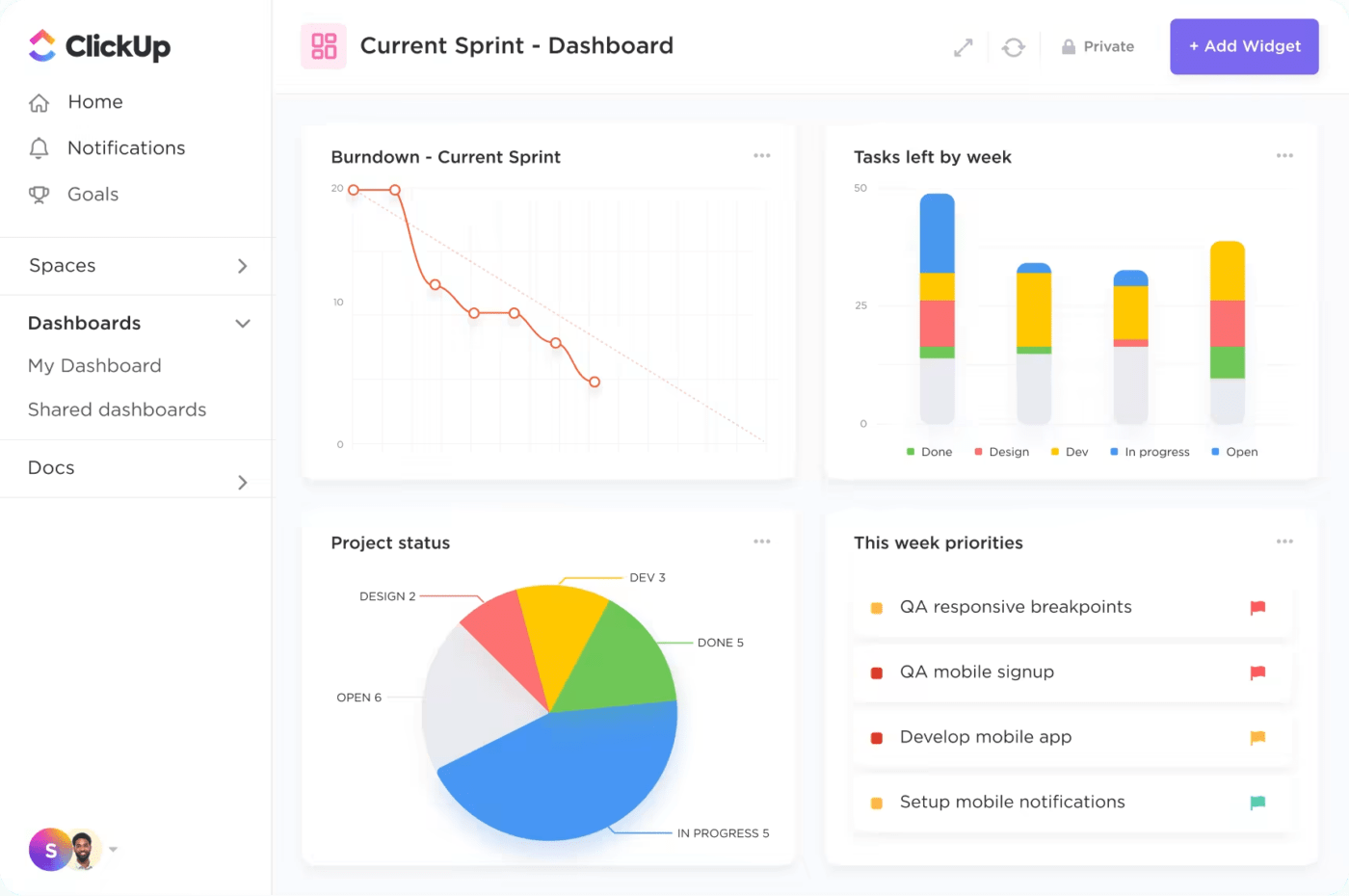
6. Готови шаблони
ClickUp предлага набор от персонализирани IT шаблони, предназначени за управление на инциденти. Тези шаблони помагат на потребителите да документират бъгове.
Например, шаблонът за докладване на ИТ инциденти на ClickUp позволява на ИТ екипите да документират, проследяват и разрешават инциденти бързо и ефективно. Това не само подобрява скоростта на обслужване, но и помага на компаниите да идентифицират дългосрочни тенденции, които могат да адресират, за да подобрят цялостната си ИТ инфраструктура.
Този шаблон улеснява:
- Документирайте и докладвайте инцидентите точно
- Проследявайте разрешаването на проблеми в реално време
- Идентифицирайте модели в докладваните проблеми за проактивно решаване на проблеми
Той включва основни компоненти като подробно описание, списък за проверка, подзадачи и полета, които могат да се персонализират. Тази гъвкавост гарантира, че шаблонът може да бъде адаптиран към вашите организационни процеси и процедури, като създава изчерпателен доклад за ИТ инциденти.
Можете да използвате и шаблона за план за действие при инциденти на ClickUp, който опростява разработването на всеобхватни планове за действие при инциденти (IAP) за бизнеса.
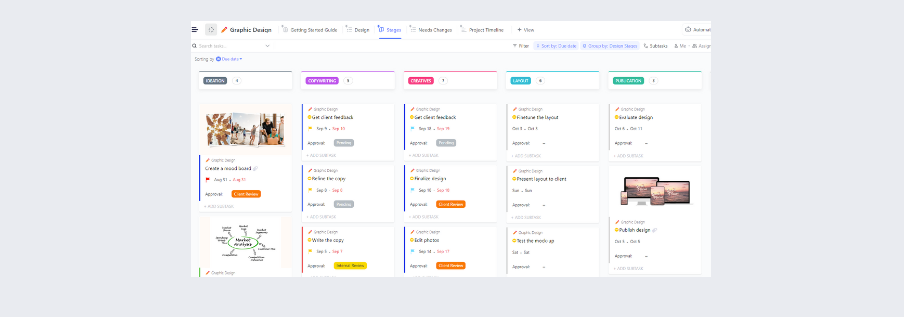
Този шаблон систематично включва цялата важна информация, като ви помага да създадете надеждни записи на дейностите, свързани с инциденти, и да приложите ефективни стратегии за реагиране.
Шаблонът включва секции с цветно кодиране за организирана документация:
- Обобщение на ситуацията: Предоставя кратък преглед на инцидента и общия план за действие.
- План за изпълнение: Подробно описание на целите и стратегиите за управление на инцидента
- Информация за контакт с екипа за инциденти: Списък с начини за контакт с персонала, участващ в реакцията
- Списък за организиране на инциденти: Очертава ролите и отговорностите на екипите по операции, планиране, логистика и финанси.
- Списък с възложени инциденти: възлага конкретни задачи на супервайзори и членове на екипа.
- Карта/обобщение на ситуацията: Включва графични представяния на мястото или региона на инцидента.
- Одобрение на план за инциденти: Записва подробности като името на лицето, което подава плана, датата на подаване и необходимите подписи.
Използвайки този шаблон, компаниите могат ефективно да съберат всички необходими подробности за одобрение от IAP и да организират добре координирана и изчерпателна реакция при инциденти.
Най-добри практики за управление на инциденти
Ефективното управление на инциденти се основава на най-добрите практики, които гарантират бързо и ефективно разрешаване.
Определете ясни очаквания с SLA
Споразуменията за ниво на обслужване (SLA) играят важна роля, като определят ясни очаквания за това колко бързо екипите трябва да реагират на инциденти в зависимост от тяхната тежест.
SLA определят конкретни времена за реакция и разрешаване, което помага за приоритизиране на инцидентите и насочва екипите в ефективното управление на работната им натовареност. Този структуриран подход ви помага да фокусирате ресурсите там, където са най-необходими, за да можете да съгласувате разрешаването на инциденти с бизнес приоритетите и да сведете до минимум прекъсванията в работата.
Прилагайте редовно кръпки, за да предотвратите инциденти
Друга важна практика е редовното инсталиране на кръпки, което помага за предотвратяване на инциденти чрез отстраняване на уязвимостите, преди да могат да бъдат експлоатирани. Това е непрекъснат процес, който отстранява пропуските в сигурността на софтуера и системите, като затруднява атакуващите да експлоатират известните слабости.
Тази практика е фундаментална част от рамката за управление на рисковете за киберсигурността, тъй като защитава ИТ инфраструктурата от възникващи заплахи и намалява риска от нарушения. Без навременни кръпки уязвимостите остават отворени и могат да доведат до значителни проблеми със сигурността.
Дайте приоритет на мониторинга на центровете за данни
Управлението на центъра за данни също играе важна роля в управлението на инциденти. Правилното управление гарантира, че както физическите, така и виртуалните аспекти на центъра за данни са добре поддържани. Това включва надзор на контрола на околната среда, електрозахранването и физическата сигурност.
Системите за мониторинг в реално време са от решаващо значение, тъй като помагат за откриването и разрешаването на проблеми, преди те да ескалират. Ефективното управление на центровете за данни, в комбинация с добре внедрена рамка за управление на рисковете, свързани с киберсигурността, позволява ранното откриване на проблеми, което помага да се избегнат сериозни прекъсвания и да се поддържа стабилността на ИТ операциите.
Предимства и предизвикателства при управлението на инциденти
Инцидентите могат да забавят напредъка на проекта и да изчерпят ценни ресурси, като често причиняват значителни оперативни прекъсвания и потенциална загуба на критични данни. Това подчертава жизненоважното значение на ефективното управление на инциденти.
Основните предимства на управлението на инциденти включват:
1. Подобрено отклоняване на инциденти
Отклоняването на инциденти включва проактивно идентифициране и смекчаване на потенциални проблеми, преди те да ескалират в значителни проблеми. Ефективните системи за управление на инциденти позволяват на организациите да прилагат превантивни мерки и непрекъснато да наблюдават производителността на системата, като по този начин намаляват честотата и тежестта на инцидентите.
2. Оптимизиран процес на промяна
Един добре управляван процес на промяна гарантира, че служителите прилагат актуализациите и модификациите систематично, следвайки установените процедури. Използването на стандартни оперативни процедури (SOP) за управление на промените спомага за стандартизиране на процедурите, гарантира последователност и намалява риска от грешки.
3. Ефективно разрешаване и приключване на инциденти
Ясно дефинираният процес на разрешаване гарантира, че екипите се занимават с инцидентите незабавно и предприемат всички необходими стъпки за разрешаване на проблема. След като бъдат разрешени, инцидентите се затварят официално с пълна документация и последващи действия. Този структуриран подход подобрява оперативната ефективност и предоставя ценна информация за анализ след инцидента и непрекъснато усъвършенстване, като помага за усъвършенстване на стратегиите за управление на инциденти с течение на времето.
Предизвикателства при управлението на инциденти
Въпреки предимствата, често възникват няколко предизвикателства при управлението на инциденти.
1. Трудности при идентифицирането на основните причини
Едно от значителните предизвикателства е идентифицирането на основната причина за инцидента, особено когато се занимавате с комплексни проблеми, които включват множество системни компоненти и взаимозависимости.
Точната диагностика на основната причина изисква задълбочено разследване и често включва междуфункционално сътрудничество. Стандартните оперативни процедури (SOP) могат да помогнат за създаването на стандартизирани процедури за анализ на основните причини, но ефективното прилагане на тези процедури изисква усъвършенствани инструменти и методологии.
Stanley Security се сблъска с подобно предизвикателство при управлението на процесите за реагиране на инциденти. Като световен лидер в областта на решенията за сигурност, Stanley Security се занимава с различни инциденти в различни системи и региони.
Преди това маркетинговите екипи на компанията разчитаха на инструменти като Excel и електронна поща за вътрешна комуникация и управление на задачите. Потребността от по-интегрирани и мащабируеми инструменти за управление на проекти, породена от пандемията COVID-19, подчерта необходимостта от премахване на изолираността и повишаване на производителността.
ClickUp предостави унифицирано работно пространство за глобални екипи, улесняващо комуникацията и организирането на документи, както и SOP, в световна база данни. Това съгласуване позволи на екипите да си сътрудничат по-ефективно и да споделят най-добрите практики. В резултат на това Stanley Security постигна 80% увеличение в подобрената работа в екип, спестявайки над 8 часа седмично за срещи и актуализации. Те също така отбелязаха 50% намаление на времето, прекарано в изготвяне и споделяне на доклади.
2. Повтаряне на инциденти
Друго предизвикателство е предотвратяването на повторение на инцидентите. Това изисква дълбоко разбиране на основните проблеми и прилагането на ефективни превантивни мерки. Идентифицирането на модели и тенденции от минали инциденти е от съществено значение за разработването на стратегии за намаляване на бъдещите рискове.
ClickUp отговаря на това предизвикателство, като предоставя интегрирани инструменти за отчитане и анализ, които предлагат информация за показателите на инцидентите и тенденциите в представянето. Този подход, основан на данни, улеснява идентифицирането на повтарящи се проблеми и помага за разработването на целенасочени стратегии за превенция.

Решението за ИТ и PMO на ClickUp може да ви бъде от полза в това отношение:
- Създайте персонализирани статуси (например „Затворен“, „В очакване“, „В процес на работа“) и полета (например „Заявител“, „Отдел“), за да категоризирате и управлявате инцидентите ефективно.
- Проследявайте и наблюдавайте инциденти в реално време, като осигурявате бързи актуализации и проверки на състоянието.
- Прикачете съответните документи, екранни снимки или логове към инцидентите за анализ. Създайте база от знания за общо решение на инциденти.
- Създавайте отчети за честотата на инцидентите, времето за разрешаване и основните причини, за да идентифицирате тенденции и да подобрите реакцията си.
- Свържете ClickUp с други ИТ инструменти, за да получите цялостен поглед върху инцидентите.
Усвояване на управлението на инциденти за оптимален успех на проекта
Усвояването на управлението на инциденти не се състои само в реагиране на проблеми – то се състои в създаването на устойчива и гъвкава среда, в която прекъсванията се управляват бързо и целите на проекта се постигат с минимално въздействие.
Прилагането на тези стратегии ще помогне на вашия екип да избегне потенциални проблеми и ще гарантира, че вашите проекти протичат гладко и успешно.
С ClickUp получавате предимството на една всеобхватна платформа, която интегрира управлението на инциденти с управлението на проекти и ИТ операции. Проследяването в реално време, автоматизираните работни процеси и инструментите за сътрудничество на ClickUp позволяват на вашия екип да се справя и решава проблемите бързо, като същевременно поддържа проектите ви в правилната посока. Независимо дали управлявате ежедневни операции или се справяте със сложни проектни изисквания, ClickUp осигурява необходимата прозрачност и контрол за постигане на изключителни резултати.
Готови ли сте да подобрите управлението на инциденти и успеха на проектите си? Регистрирайте се в ClickUp още днес и променете управлението на инциденти!