

คุณเป็นหัวหน้าแผนกที่กำลังมองหาบุคคลที่เหมาะสมที่สุดเพื่อรับผิดชอบงานเฉพาะด้าน ด้วยข้อมูลของบริษัทที่มีอยู่อย่างมากมาย การค้นหาคนที่เหมาะสมที่สุดแทบจะเป็นไปไม่ได้ โดยเฉพาะอย่างยิ่งหากงานของคุณมีความเร่งด่วน
นอกจากนี้ ใครจะมีเวลาไปถามทุกคนว่าพวกเขามีความรู้เพียงพอเกี่ยวกับเรื่องเฉพาะทางหรือไม่?
แต่ถ้าคุณสามารถถามระบบได้โดยตรงว่า 'ใครได้รับมอบหมาย [งาน] มากที่สุด?' แล้วได้รับคำตอบที่ถูกต้องและทันทีจากข้อมูลจริง นั่นคือสิ่งที่ระบบสืบค้นข้อมูลทำ
ระบบเหล่านี้คัดกรองข้อมูลจำนวนมหาศาลเพื่อค้นหาสิ่งที่คุณต้องการอย่างแม่นยำ
ตอนนี้ ขยายความคิดนั้นไปสู่ฐานข้อมูลระดับโลก—ระบบสืบค้นข้อมูล (IR) จัดระเบียบข้อมูลจำนวนมหาศาล ช่วยให้คุณค้นหาคำตอบที่เกี่ยวข้องมากที่สุดได้ในไม่กี่วินาที คู่มือนี้จะสำรวจโมเดลการสืบค้นข้อมูลที่แตกต่างกัน วิธีการทำงาน และบทบาทของเทคโนโลยีปัญญาประดิษฐ์ในระบบ IR
⏰ สรุป 60 วินาที
📌 ระบบการค้นหาข้อมูล (IR) ช่วยค้นหาข้อมูลที่เกี่ยวข้องจากชุดข้อมูลขนาดใหญ่ ทำงานเหมือนผู้ช่วยเสมือนที่คัดกรองข้อมูลเพื่อค้นหาสิ่งที่คุณต้องการ
📌 ระบบ IR มีองค์ประกอบหลัก ได้แก่ ฐานข้อมูล, ตัวจัดทำดัชนี, อินเทอร์เฟซการค้นหา, ตัวประมวลผลคำสั่งค้นหา, แบบจำลองการค้นหา, และกลไกการจัดอันดับ/การให้คะแนน
📌 ใช้โมเดล IR หลักสี่แบบ: แบบบูลีน (ใช้ตัวดำเนินการ AND/OR/NOT), แบบเวกเตอร์สเปซ (แทนเอกสารเป็นเวกเตอร์), แบบความน่าจะเป็น (ใช้วิธีทางสถิติ), และแบบความสัมพันธ์ระหว่างคำ (วิเคราะห์ความสัมพันธ์ระหว่างคำ)
📌 การเรียนรู้ของเครื่อง (Machine Learning) และการประมวลผลภาษาธรรมชาติ (Natural Language Processing) ช่วยเพิ่มประสิทธิภาพระบบ IR โดยปรับปรุงการจดจำรูปแบบ การจัดอันดับผลลัพธ์ และการเข้าใจบริบท
📌 ความท้าทายหลัก ได้แก่ ความเป็นส่วนตัวของข้อมูล, ความสามารถในการขยายระบบ, และการรักษาคุณภาพของข้อมูลในระหว่างการประมวลผลชุดข้อมูลขนาดใหญ่
การค้นคืนสารสนเทศ (IR) คืออะไร?
การค้นคืนข้อมูล (IR) หมายถึง การค้นหาข้อมูลที่ถูกต้องจากแหล่งข้อมูลขนาดใหญ่ เช่น ห้องสมุดดิจิทัล ฐานข้อมูล หรือคลังข้อมูลอินเทอร์เน็ต
มันเหมือนมีผู้ช่วยเสมือนจริงที่ คัดกรองข้อมูลจำนวนมหาศาลเพื่อนำเสนอสิ่งที่คุณต้องการโดยเฉพาะ
บนผิวเผิน ผู้ใช้จะป้อนคำค้นหา ซึ่งมักใช้คำค้นหาหรือวลี เพื่อค้นหาข้อมูลเฉพาะ. เบื้องหลัง ผู้ใช้จะป้อนคำค้นหา ซึ่งมักใช้คำค้นหาหรือวลี เพื่อค้นหาข้อมูลเฉพาะ. เบื้องหลัง ผู้ใช้จะป้อนคำค้นหา ซึ่งมักใช้คำค้นหาหรือวลี เพื่อค้นหาข้อมูลเฉพาะ. เบื้องหลัง ผู้ใช้จะป้อนคำค้นหา ซึ่งมักใช้คำค้นหาหรือวลี เพื่อค้นหาข้อมูลเฉพาะ. เบื้องหลัง ผู้ใช้จะป
แทนที่จะระบุคำตอบเพียงคำตอบเดียว ระบบการค้นหาข้อมูล (IR) จะให้ผลลัพธ์หลายรายการ—แต่ละรายการมีความเกี่ยวข้องกับคำถามของคุณในระดับที่แตกต่างกัน นอกจากนี้ ระบบเหล่านี้ยังถูกใช้ในทุกที่และมีหลากหลายการใช้งาน (รายละเอียดเพิ่มเติมเร็ว ๆ นี้ 🔔)
💡เคล็ดลับจากมืออาชีพ: ต้องการหาคนที่มีทักษะมากที่สุดสำหรับงานนี้ใช่ไหม? เพียงใส่คำเฉพาะ เช่น 'การวิเคราะห์รายงานการขาย Q1 และ Q2 งานที่ได้รับมอบหมาย' ลงในระบบค้นหาข้อมูล เท่านี้ ระบบก็จะกรองข้อมูลที่ไม่เกี่ยวข้องออกอย่างรวดเร็ว และแสดงผลลัพธ์ของคนที่เคยรับผิดชอบงานนี้มากที่สุดให้คุณทันที
การประยุกต์ใช้ IR ในสาขาต่าง ๆ
ตั้งแต่การดูแลสุขภาพไปจนถึงอีคอมเมิร์ซ ระบบ IR ถูกใช้ในหลากหลายสาขาเพื่อจัดการและจัดหมวดหมู่ข้อมูล ต่อไปนี้คือตัวอย่างบางส่วน 👇
การดูแลสุขภาพ
ในระบบสุขภาพ ระบบ IR จะสแกนฐานข้อมูลของบันทึกทางการแพทย์และเอกสารวิจัยเพื่อช่วยแพทย์และนักวิจัยค้นหาข้อมูลที่เกี่ยวข้องมากที่สุด ผลที่ได้คือช่วยเร่งการวินิจฉัยโรค ระบุทางเลือกในการรักษา และค้นหาการศึกษาที่เกี่ยวข้องมากที่สุดโดยใช้ข้อมูลย้อนกลับที่เกี่ยวข้อง
บริการลูกค้า
เทคนิคการค้นหาข้อมูลช่วยให้การสนับสนุนลูกค้าเร็วขึ้นและแม่นยำมากขึ้น ตัวอย่างเช่น ตัวแทนสามารถพิมพ์ คำถามของผู้ใช้ เช่น 'นโยบายการคืนเงิน' ลงในระบบของบริษัทเพื่อดึงคำตอบได้ทันที
แชทบอท AI และศูนย์ช่วยเหลือที่ขับเคลื่อนด้วยการค้นคืนข้อมูลก้าวไปอีกขั้น ด้วยการนำเสนอวิธีแก้ปัญหาแบบเรียลไทม์โดยไม่ต้องใช้มนุษย์ นั่นคือเหตุผลที่คำถามของคุณมักจะได้รับคำตอบภายในไม่กี่วินาที!
แพลตฟอร์มอีคอมเมิร์ซ
ระบบปัญญาประดิษฐ์ทำให้การช้อปปิ้งออนไลน์เป็นเรื่องง่าย. ระบบวิเคราะห์ฐานข้อมูลและจับคู่พฤติกรรมของลูกค้าเพื่อแนะนำสินค้าที่คุณจะชอบ.
ตัวอย่างเช่น Amazon ใช้ IR เพื่อแนะนำสินค้าตามประวัติการค้นหาและการซื้อครั้งก่อนของคุณ ช่วยให้คุณค้นหาสิ่งที่คุณต้องการได้อย่างแม่นยำ
องค์ประกอบของระบบสืบค้นข้อมูล
ตอนนี้เราทราบแล้วว่าการค้นหาข้อมูลคืออะไรและทำงานอย่างไร มาแยกย่อยองค์ประกอบหลักของระบบค้นหาข้อมูลกัน →
1. ฐานข้อมูล
ทุกสิ่งเริ่มต้นจากฐานข้อมูล ฐานข้อมูลคือการรวบรวมข้อมูลที่เกี่ยวข้องกัน เช่น เอกสารข้อความ อีเมล หน้าเว็บ รูปภาพ และวิดีโอ เมื่อคุณป้อน คำค้นหา ระบบการค้นหาข้อมูล (IR) จะค้นหาผ่าน การจับคู่ฐานข้อมูล เหล่านี้เพื่อดึงข้อมูลที่เกี่ยวข้องมากที่สุดสำหรับความต้องการของคุณ
2. ดัชนี
ก่อนที่ระบบจะสามารถดึงข้อมูลใด ๆ ได้ ตัวจัดดัชนีจะจัดระเบียบข้อมูลก่อน เปรียบเสมือนการเตรียมแคตตาล็อกห้องสมุดเพื่อให้การค้นหาเป็นไปอย่างรวดเร็ว ตัวจัดดัชนีจะประมวลผลเอกสารโดย:
- โทเค็น: การแบ่งเนื้อหาออกเป็นส่วนย่อย ๆ เช่น การแยกประโยคเป็นคำหรือวลี (เรียกว่าโทเค็น)
- การตัดคำ: การย่อคำให้เหลือรูปแบบพื้นฐาน (เช่น 'running' กลายเป็น 'run')
- การลบคำที่ไม่จำเป็น: ข้ามคำเติมเช่น 'และ,' 'หรือ,' และ 'the' เพื่อเน้นที่คำถามหลัก
- การสกัดคำสำคัญ: การระบุคำหลักในข้อความ
- การสกัดข้อมูลเมตา: การดึงรายละเอียดเพิ่มเติม เช่น ผู้แต่ง วันที่เผยแพร่ หรือชื่อเรื่อง
3. อินเทอร์เฟซการค้นหา
อินเตอร์เฟซการค้นหาทำหน้าที่เป็นประตูสู่ระบบ IR ของคุณ ที่นี่คุณสามารถพิมพ์คำค้นหาของคุณโดยใช้คำค้นหาที่ง่ายหรือตัวกรองที่ละเอียดมากขึ้น ออกแบบมาเพื่อให้ใช้งานง่าย ทำให้คุณสามารถ สื่อสารความต้องการในการเข้าถึงข้อมูลของคุณได้อย่างง่ายดาย และได้รับผลลัพธ์ที่เกี่ยวข้องตามที่คุณค้นหา
4. ตัวประมวลผลคำสั่งค้นหา
เมื่อคุณกด 'ค้นหา' ตัวประมวลผลคำค้นหาจะเริ่มทำงาน มันจะปรับปรุงข้อมูลที่คุณป้อนโดยใช้เทคนิคที่ระบุในส่วนตัวจัดทำดัชนี นอกจากนี้ยังจัดการ ตัวดำเนินการบูลีน เช่น 'AND', 'OR' และ 'NOT' เพื่อให้คำค้นหาของคุณฉลาดขึ้น
5. แบบจำลองการเรียกคืน
นี่คือที่ที่เวทมนตร์เกิดขึ้น ระบบจะเปรียบเทียบคำค้นหาของคุณกับเอกสารที่ถูกจัดทำดัชนีไว้ โดยใช้แบบจำลองการค้นหา วิธีเหล่านี้จะตัดสินใจว่าจะจับคู่คำค้นหาของคุณกับข้อมูลที่จัดเก็บไว้อย่างไร ชื่อที่พบบ่อยบางชื่อได้แก่:
- แบบจำลองเชิงบูลีน
- แบบจำลองปริภูมิเวกเตอร์
- แบบจำลองเชิงความน่าจะเป็น
- และ, มากกว่านั้น... (จะกล่าวถึงในภายหลัง)
6. การจัดอันดับและการให้คะแนน
เมื่อพบคู่ที่อาจตรงกัน ระบบจะจัดอันดับพวกเขาตามความเกี่ยวข้อง เอกสารแต่ละฉบับจะได้รับคะแนน โดยใช้วิธีการเช่น TF-IDF (Term Frequency-Inverse Document Frequency) หรืออัลกอริธึมอื่นๆ เพื่อให้แน่ใจว่าผลลัพธ์ที่เกี่ยวข้องมากที่สุดจะปรากฏที่ด้านบน
7. การนำเสนอหรือการจัดแสดง
ในที่สุด ผลลัพธ์ก็ถูกนำเสนอให้คุณแล้ว โดยทั่วไป ระบบจะ แสดงรายการเอกสารข้อความที่มีการจัดอันดับ พร้อมคุณสมบัติเพิ่มเติม เช่น สแนปช็อต ตัวกรอง หรือตัวเลือกการจัดเรียง ซึ่งช่วยให้คุณสามารถเลือกเอกสารที่เกี่ยวข้องมากที่สุดได้ง่ายขึ้น อย่างไรก็ตาม จำนวนผลลัพธ์ที่แสดงอาจแตกต่างกันไปตามการตั้งค่าของคุณ คำค้นหา หรือระบบ
🔍คุณรู้หรือไม่?: ระบบการค้นหาข้อมูลแบบดั้งเดิมพึ่งพาฐานข้อมูลที่มีโครงสร้างและการจับคู่คำหลักพื้นฐานเป็นอย่างมาก ผลลัพธ์ที่ได้คือ? ปัญหาด้านความเกี่ยวข้องและการปรับแต่งส่วนบุคคลที่สำคัญ
นั่นคือเมื่อเทคโนโลยีปัญญาประดิษฐ์สมัยใหม่ได้เปลี่ยนแปลง การค้นคืนข้อความ ผ่าน:
- การเรียนรู้ของเครื่อง (ML): ช่วยให้ระบบ IR เรียนรู้จากรูปแบบพฤติกรรมของผู้ใช้และปรับปรุงผลการค้นหาให้ดีขึ้นเมื่อเวลาผ่านไป
- เครือข่ายประสาทเทียมเชิงลึก: อัลกอริทึมที่สามารถประมวลผลข้อมูลที่ไม่มีโครงสร้าง (เช่น ภาพหรือวิดีโอ) และค้นพบความสัมพันธ์ที่ซับซ้อน
- การประมวลผลภาษาธรรมชาติ (NLP): ช่วยให้ระบบเข้าใจความหมายและบริบทของคำถามเพื่อสนับสนุนการจดจำภาพและการวิเคราะห์ความรู้สึก ทำให้การเข้าถึงข้อมูลมีความหลากหลายมากขึ้น
แบบจำลองการค้นคืนสารสนเทศ
มีระบบ IR หลากหลายรูปแบบที่ช่วยให้กระบวนการค้นหาเอกสารที่เกี่ยวข้องเป็นไปอย่างมีประสิทธิภาพมากขึ้น มาดูระบบที่ใช้กันอย่างแพร่หลายที่สุดกัน:
1. ทฤษฎีเซตและแบบจำลองบูลีน
แบบจำลองบูลีนเป็นหนึ่งใน เทคนิคการค้นคืนข้อมูลที่ง่ายที่สุด นี่คือวิธีการทำงาน:
- AND: ค้นหาเอกสารที่มี ทุก คำในคำค้นหา ตัวอย่างเช่น การค้นหาคำว่า 'cat AND dog' จะแสดงเอกสารที่กล่าวถึงทั้งสองคำในเครื่องมือค้นหา
- หรือ: ค้นหาเอกสารที่มี คำใดคำหนึ่ง จากคำค้นหาทั้งหมด สำหรับ 'cat OR dog' จะแสดงเอกสารที่กล่าวถึงแมว สุนัข หรือทั้งสองคำ
- หมายเหตุ: ไม่รวมเอกสารที่มีคำเฉพาะเจาะจง ตัวอย่างเช่น 'cat AND NOT dog' จะแสดงเอกสารที่กล่าวถึง cat แต่ไม่กล่าวถึง dog
โมเดลนี้ใช้แนวคิด 'ถุงของคำ' ซึ่งสร้าง เมทริกซ์ 2 มิติ ในเมทริกซ์นี้:
- คอลัมน์แทนเอกสาร
- แถวแทนคำจากคำค้นหา
แต่ละเซลล์จะถูกกำหนดค่าเป็น 1 (หากมีคำศัพท์นั้นอยู่) หรือ 0 (หากไม่มี)

✅ ข้อดี
- เข้าใจง่ายและนำไปใช้ได้สะดวก
- ดึงเอกสารที่ตรงกับคำค้นหาอย่างสมบูรณ์
❌ ข้อเสีย
- โมเดลแบบบูลีนไม่จัดอันดับเอกสารตามความเกี่ยวข้อง ดังนั้นผลลัพธ์ทั้งหมดจึงถูกพิจารณาว่ามีความสำคัญเท่าเทียมกัน
- เน้นการจับคู่คำที่ตรงกันทุกคำ ดังนั้นผลลัพธ์อาจแตกต่างกันไปภายในความหมายหรือบริบทของคำค้นหา
2. แบบจำลองเวกเตอร์สเปซ
แบบจำลองเวกเตอร์สเปซคือ แบบจำลองเชิงพีชคณิต ที่ใช้แทนทั้งเอกสารและคำค้นหาเป็นเวกเตอร์ในพื้นที่หลายมิติ นี่คือวิธีการทำงาน:
1. เมทริกซ์เอกสารตามคำศัพท์ ถูกสร้างขึ้น โดยแถวเป็นคำศัพท์และคอลัมน์เป็นเอกสาร
2. เวกเตอร์คำค้นหา ถูกสร้างขึ้นโดยอิงจากคำค้นหาของผู้ใช้
3. ระบบคำนวณ คะแนนตัวเลข โดยใช้มาตรวัดที่เรียกว่า cosine similarity ซึ่งกำหนดว่าเวกเตอร์ของคำค้นหามีความใกล้เคียงกับเวกเตอร์ของเอกสารมากเพียงใด

ในฐานะระบบค้นหาข้อมูล เอกสารจะถูกจัดอันดับตามคะแนนเหล่านี้ โดยเอกสารที่ได้คะแนนสูงสุดจะมีความเกี่ยวข้องมากที่สุด
✅ ข้อดี
- ดึงข้อมูลแม้ว่าจะมีเพียงบางคำที่ตรงกัน
- ความแตกต่างในการใช้คำศัพท์และความยาวของเอกสาร รองรับประเภทเอกสารที่หลากหลาย
❌ ข้อเสีย
- คลังคำศัพท์และเอกสารที่ใหญ่ขึ้นทำให้การคำนวณความคล้ายคลึงกันใช้ทรัพยากรมากขึ้น
3. แบบจำลองเชิงความน่าจะเป็น
โมเดลนี้ใช้วิธีการทางสถิติ โดยใช้ความน่าจะเป็นในการประมาณว่าเอกสารมีความเกี่ยวข้องกับคำค้นหาเพียงใด โดยพิจารณาจาก:
- ความถี่ของคำในเอกสาร
- ความถี่ที่คำหรือวลีปรากฏร่วมกัน (การเกิดร่วมกัน)
- ความยาวของเอกสารและจำนวนคำค้นหาทั้งหมด
ระบบจัดการกระบวนการดึงข้อมูลเป็นเหตุการณ์เชิงความน่าจะเป็น โดยจัดอันดับเอกสารที่จัดเก็บตามความน่าจะเป็นที่จะมีความเกี่ยวข้อง วิธีการนี้เพิ่มความลึกโดยการประเมินวัตถุข้อมูลที่มากกว่าการมีอยู่ของคำพื้นฐาน
✅ ข้อดี
- ปรับใช้ได้ดีกับการประยุกต์ใช้งานที่หลากหลาย รวมถึงการวิเคราะห์ความน่าเชื่อถือและการประเมินโหลดโฟลว์
❌ ข้อเสีย
- อาศัยสมมติฐานเกี่ยวกับความสัมพันธ์ของข้อมูล ซึ่งอาจนำไปสู่ผลลัพธ์ที่คลาดเคลื่อน
4. แบบจำลองการพึ่งพาอาศัยกันในระยะ
ต่างจากแบบจำลองที่ง่ายกว่า แบบจำลองการพึ่งพาอาศัยกันของคำ ให้ความสำคัญกับความสัมพันธ์ระหว่างคำมากกว่าความถี่ของคำเพียงอย่างเดียว แบบจำลองเหล่านี้วิเคราะห์ว่าคำและวลีมีความสัมพันธ์กันอย่างไรเพื่อปรับปรุงความถูกต้องของผลลัพธ์
พวกเขาใช้วิธีใดวิธีหนึ่งจากสองวิธีต่อไปนี้:
- โหมดภายใน: สำรวจความสัมพันธ์ภายในเนื้อหาเอง
- โหมดเหนือธรรมชาติ: พิจารณาข้อมูลหรือบริบทภายนอกเพื่อสรุปความสัมพันธ์
วิธีนี้มีประโยชน์อย่างยิ่ง สำหรับการจับความหมายที่ละเอียดอ่อน เช่น คำที่มีความหมายเหมือนกันหรือวลีเฉพาะตามบริบท
✅ ข้อดี
- จับความหมายที่ละเอียดอ่อนในภาษาโดยการพิจารณาความสัมพันธ์ของคำศัพท์
- เพิ่มประสิทธิภาพการค้นหาโดยการเข้าใจความสัมพันธ์ของคำและบริบท
❌ ข้อเสีย
- ต้องการข้อมูลจำนวนมากเพื่อสร้างแบบจำลองความสัมพันธ์ระหว่างคำได้อย่างแม่นยำ ซึ่งอาจไม่สามารถหาได้เสมอไป
นั่นแหละ! นี่คือระบบค้นหาข้อมูลที่ใช้กันทั่วไปบางส่วน พร้อมข้อดีข้อเสียของแต่ละระบบ
➡️ อ่านเพิ่มเติม:4 ทางเลือกและคู่แข่งของ Spotlight Search
การค้นคืนข้อมูลกับการสืบค้นข้อมูล
แม้ว่าทั้งสองคำนี้จะดูคล้ายกันมาก แต่การทำงานของมันแตกต่างกัน ดังนั้น มาเปรียบเทียบ IR และ Data Querying ควบคู่กันเพื่อดูว่ามันมีความแตกต่างกันอย่างไรในแง่ของวัตถุประสงค์ กรณีการใช้งาน และตัวอย่าง:
| ลักษณะ | การค้นคืนข้อมูล (IR) | การสืบค้นข้อมูล |
| คำนิยาม | ทำงานเหมือนเครื่องมือค้นหาที่ค้นหาผ่านข้อมูลจำนวนมากเพื่อนำเสนอผลลัพธ์ที่เกี่ยวข้องมากที่สุดแก่คุณ | คิดเสียว่าเป็นการถามคำถามเฉพาะกับฐานข้อมูลในภาษาที่มันเข้าใจ (เช่น SQL) |
| เป้าหมาย/วัตถุประสงค์ | ช่วยให้คุณค้นหาข้อมูลหรือแหล่งข้อมูลที่ถูกต้องและเกี่ยวข้องบนเครื่องมือค้นหาได้อย่างรวดเร็วและง่ายดาย | ดึงข้อมูลที่ถูกต้องเพื่อให้คุณสามารถวิเคราะห์, อัปเดต, หรือคำนวณตัวเลขได้ |
| กรณีการใช้งาน | ใช้สำหรับการค้นหาเว็บ, คำแนะนำอีคอมเมิร์ซ, ห้องสมุดดิจิทัล, ข้อมูลเชิงลึกด้านการดูแลสุขภาพ, และอื่น ๆ | เหมาะอย่างยิ่งสำหรับงานต่างๆ เช่น การจัดการสต็อกสินค้าในอีคอมเมิร์ซ การวิเคราะห์การเงิน และการเพิ่มประสิทธิภาพห่วงโซ่อุปทาน |
| ตัวอย่าง | ค้นหา 'แล็ปท็อปที่ดีที่สุดในช่วงราคา 800 ถึง 1000 ดอลลาร์' บนGoogleเพื่อรับผลลัพธ์ที่มีการจัดอันดับ | การค้นหาในระบบสินค้าคงคลังของคุณด้วยคำสั่ง 'SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000' เพื่อดูว่ามีสินค้าอะไรบ้าง |
บทบาทของแมชชีนเลิร์นนิงและ NLP ในการสืบค้นข้อมูล
ระบบ IR เปรียบเสมือนนักล่าสมบัติสำหรับข้อมูล—พวกเขาคัดกรองข้อมูลจำนวนมหาศาลเพื่อค้นหาสิ่งที่คุณต้องการอย่างแม่นยำ แต่เมื่อ ML และ NLP มาร่วมมือกัน ระบบเหล่านี้จะฉลาดขึ้น เร็วขึ้น และแม่นยำยิ่งขึ้นอย่างมาก
คิดถึง ML ว่าเป็นสมองที่อยู่เบื้องหลังระบบ IR. 🧠
มันช่วยให้ระบบเรียนรู้ ปรับตัว และปรับปรุงผลลัพธ์ทุกครั้งที่คุณค้นหาข้อมูล นี่คือวิธีการทำงาน:
- การสังเกตรูปแบบ: การเรียนรู้ของเครื่อง (ML) ศึกษาว่าผู้ใช้คลิกที่อะไร, พวกเขาละเลยอะไร, และพวกเขาใช้เวลาอ่านอะไรมากที่สุด จากนั้นมันจะใช้ความรู้นี้เพื่อแสดงผลลัพธ์ที่เกี่ยวข้องมากที่สุดให้คุณในครั้งต่อไป
- ผลการจัดอันดับ: ML ค้นหาข้อมูลและจัดอันดับข้อมูลนั้นด้วย ซึ่งหมายความว่าผลลัพธ์ที่ดีที่สุดและมีประโยชน์ที่สุดจะปรากฏขึ้นด้านบนสุดของการค้นหาของคุณ
- การปรับตัวตามกาลเวลา: ทุกครั้งที่มีคำถาม ML จะพัฒนาขึ้น มันจับแนวโน้ม ปรับปรุงความเข้าใจ และจัดการกับคำถามที่ยากที่สุดได้อย่างง่ายดาย
ตัวอย่างเช่น หากคุณค้นหา 'แล็ปท็อปราคาประหยัดที่ดีที่สุด' วันนี้และมีปฏิสัมพันธ์กับผลลัพธ์เฉพาะ ระบบ ML จะรู้ว่าจะให้ความสำคัญกับตัวเลือกที่คล้ายกันเมื่อคุณค้นหา 'โน้ตบุ๊กราคาไม่แพง' ในภายหลัง ด้วยการรวม AI กับ ML เครื่องมือค้นหาเว็บสามารถทำนายสิ่งที่คุณอาจต้องการต่อไปได้อีกด้วย
ตอนนี้เรามาพูดถึง NLP กันบ้าง มันช่วยให้ระบบ IR เข้าใจความหมายของคุณ ไม่ใช่แค่คำที่คุณพิมพ์ออกมาเท่านั้น พูดง่ายๆ คือ:
- มันเข้าใจบริบท: NLP รู้ว่าเมื่อคุณพูดว่า 'จากัวร์' คุณอาจหมายถึงสัตว์หรือรถยนต์ และมันสามารถแยกแยะความหมายได้จากการค้นหาของคุณที่เหลือ
- มันจัดการกับภาษาที่ซับซ้อน: ไม่ว่าคำถามของคุณจะง่าย ('เที่ยวบินราคาถูก') หรือละเอียด ('เที่ยวบินตรงไปโตเกียวต่ำกว่า $500') NLP ทำให้ระบบเข้าใจและส่งมอบผลลัพธ์ที่ถูกต้อง
NLP และ IR ร่วมกันทำให้การค้นหาเป็นเรื่องที่รู้สึกเป็นธรรมชาติ เหมือนการพูดคุยกับใครบางคนที่เข้าใจคุณอย่างแท้จริง ซึ่งหมายถึงการเลื่อนหน้าเว็บน้อยลง ความหงุดหงิดน้อยลง และช่วงเวลาที่รู้สึกประทับใจว่า "ว้าว นี่แหละที่ฉันต้องการ!" มากขึ้น
บทบาทของ ClickUp ในการสืบค้นข้อมูล
ClickUp, 'แอปทุกอย่างสำหรับการทำงาน,' เพิ่มประสิทธิภาพการจัดการข้อมูลด้วยโมเดล IR.
ระบบปัญญาประดิษฐ์ที่ติดตั้งมาในตัวสามารถระบุและจับคู่ผลลัพธ์กับคำค้นหาของผู้ใช้ได้อย่างเป็นเอกลักษณ์ ยกระดับเทคโนโลยีอัจฉริยะไปอีกขั้น
และเพื่อเพิ่มความคุ้มค่าClickUp's Connected Searchทำให้การเข้าถึงทุกสิ่งที่คุณต้องการเป็นเรื่องง่ายและรวดเร็วทันใจในทันที นั่นหมายความว่า:
- ค้นหาอะไรก็ได้: ใครชอบเสียเวลาค้นหาอีเมลและระบบจัดการความรู้เพื่อหาไฟล์สำคัญ? ค้นหาไฟล์ใดก็ได้ภายในไม่กี่วินาทีด้วยตัวเลือกการค้นหาแบบเชื่อมต่อ ยิ่งไปกว่านั้น ค้นหาไฟล์จากแอปที่เชื่อมต่อทั้งหมดและเข้าถึงทุกอย่างได้ในที่เดียว
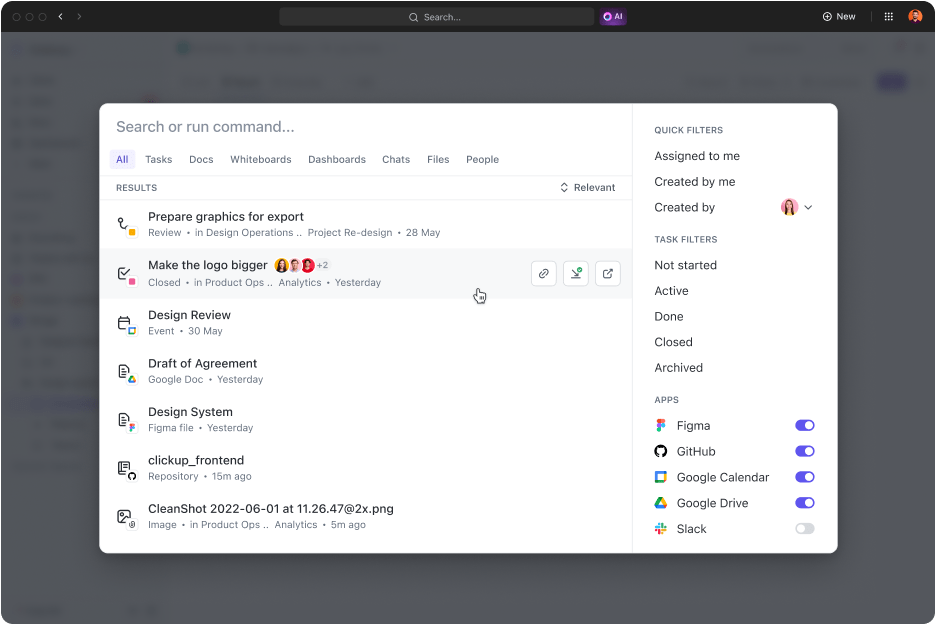
- เชื่อมต่อแอปโปรดของคุณ:ClickUp มีการผสานรวมที่ดีที่สุดบางอย่างที่ขยายความสามารถในการค้นหาไปยังแอปของบุคคลที่สาม เช่น Google Drive, Slack, Dropbox, Figma และอื่นๆ

- ปรับปรุงผลลัพธ์: ยิ่งคุณใช้มากเท่าไหร่ ระบบก็จะยิ่งเข้าใจสิ่งที่คุณกำลังมองหาได้ดีขึ้นเท่านั้น พร้อมนำเสนอผลลัพธ์ที่ตรงกับความต้องการของคุณโดยเฉพาะ
- ค้นหาในแบบของคุณ: เข้าถึง Connected Search และค้นหาไฟล์ PDF ได้อย่างรวดเร็วจากทุกที่ในพื้นที่ทำงานของคุณ ตัวอย่างเช่น คุณสามารถเริ่มการค้นหาได้จาก Command Center, Global Action Bar หรือเดสก์ท็อปของคุณ
- สร้างคำสั่งค้นหาแบบกำหนดเอง: เพิ่มคำสั่งค้นหาแบบกำหนดเอง เช่น ทางลัดไปยังลิงก์ การบันทึกข้อความไว้ใช้ภายหลัง และอื่นๆ เพื่อเพิ่มประสิทธิภาพการทำงานของคุณ
เพื่อเพิ่มความน่าสนใจขึ้นไปอีก หากมีวิธีที่จะทำให้งานที่น่าเบื่อกลายเป็นอัตโนมัติทำงานได้เร็วขึ้น และทำสิ่งต่าง ๆ ได้มากขึ้นในเวลาอันสั้น?
ClickUp Brain ผู้ช่วย AI ในตัว ทำให้สิ่งนี้เป็นจริงสำหรับคุณ เป็นผู้ช่วยที่ดีที่สุดสำหรับการจัดการข้อมูล—ฉลาด รวดเร็ว และพร้อมช่วยเหลือเสมอ
สรุปสั้น ๆ 👇
- ศูนย์รวมความรู้ครบวงจร: ไม่ต้องพึ่งอีเมลหรือข้อความเพื่ออัปเดตอีกต่อไป ถามได้ทุกเรื่องเกี่ยวกับงาน เอกสาร หรือบุคคลของคุณ แล้วนั่งสบายๆ ขณะที่ ClickUp Brain จัดทำคำตอบโดยอิงจากบริบทภายในและแอปที่เชื่อมต่อ

- ค้นหาสิ่งที่คุณต้องการได้เร็วขึ้น: ClickUp Brain จัดอันดับผลลัพธ์อย่างชาญฉลาดเหมือนระบบ IR ขั้นสูง โดยให้ความสำคัญกับไฟล์ที่เกี่ยวข้อง แนะนำงานที่เกี่ยวข้อง และช่วยคุณค้นพบปริมาณงานที่ซ่อนอยู่ในข้อมูลของคุณ
- อัตโนมัติงาน: Brain ช่วยอัตโนมัติการสร้างรายงานหรือติดตามกำหนดเวลาผ่านเครื่องมือ AI ของมัน. มันคือผู้ช่วยส่วนตัวที่ช่วยคุณประหยัดเวลาเพื่อตัดสินใจใหญ่ ๆ ในขณะที่ทุกอย่างอยู่ในเส้นทางที่ถูกต้อง
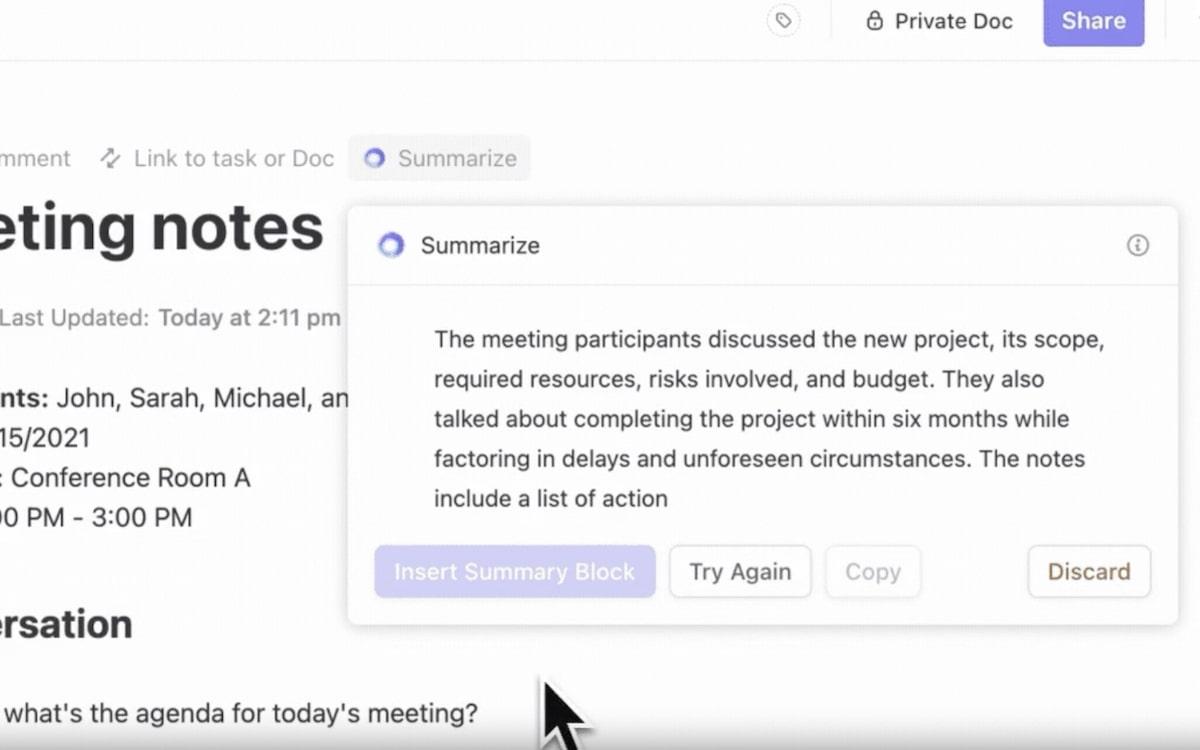
- การค้นหาที่เข้าใจบริบท: ด้วย NLP ระบบสามารถเข้าใจคำถามของคุณได้—แม้จะเป็นคำถามที่ซับซ้อนหรือคลุมเครือก็ตาม ตัวอย่างเช่น การค้นหา 'รายงานยอดขายไตรมาส 1' จะให้รายงานที่ ตรงกับ งานของคุณอย่างแม่นยำ
➡️ อ่านเพิ่มเติม:ระบบการจัดการงานคืออะไรและวิธีการนำไปใช้?
ความท้าทายและทิศทางในอนาคตของการค้นคืนสารสนเทศ
โลกของการสืบค้นข้อมูลนั้นเกี่ยวข้องกับการทำความเข้าใจกับข้อมูลจำนวนมหาศาล แต่ถึงแม้ระบบสืบค้นข้อมูลที่ล้ำหน้าที่สุดก็ยังต้องเผชิญกับอุปสรรคบางประการระหว่างทาง
มาสำรวจความท้าทายทั่วไปและแนวโน้มที่น่าตื่นเต้นที่กำลังกำหนดอนาคตของศาสตร์สำคัญนี้กัน:
- ความเป็นส่วนตัวและความปลอดภัยของข้อมูล: เพื่อให้โมเดล IR สามารถให้ผลลัพธ์ที่เป็นข้อเท็จจริงได้ มักจะต้องมีการเข้าถึงข้อมูลที่ละเอียดอ่อน อย่างไรก็ตาม การปกป้องข้อมูลของผู้ใช้ไม่ใช่เรื่องง่ายสำหรับทรัพยากรการสืบค้นข้อมูล
- ความสามารถในการปรับขนาดและประสิทธิภาพ: เมื่อผู้ใช้ค้นหาผ่านชุดข้อมูลขนาดใหญ่ การจัดการกับการรวบรวมเนื้อหาที่เพิ่มขึ้นอาจทำให้แม้แต่โมเดลการค้นหาที่แข็งแกร่งที่สุดก็ไม่สามารถรับมือได้ ความท้าทายคือการรับประกันการค้นหาที่มีประสิทธิภาพโดยไม่ลดทอนความเกี่ยวข้องของผลลัพธ์การค้นหา
- คุณภาพของข้อมูลและความเข้าใจในบริบท: การค้นหาที่ไม่ชัดเจนหรือข้อมูลเมตาดาตาที่จัดระเบียบไม่ดีอาจนำไปสู่ความไม่ตรงกัน ทำให้ระบบยากที่จะระบุเจตนาของผู้ใช้ได้อย่างเฉพาะเจาะจง
แนวโน้มใหม่และการก้าวหน้าในเทคโนโลยี IR
แม้จะมีอุปสรรคมากมาย ความก้าวหน้าทางเทคโนโลยีล่าสุดได้ทำให้เราสามารถสร้างระบบที่ชาญฉลาดและมีประสิทธิภาพมากขึ้นได้
ระบบสืบค้นข้อมูลสมัยใหม่ในปัจจุบันใช้เทคนิคขั้นสูง เช่น การวิเคราะห์แบบกราฟเพื่อ ตีความตัวเลขและข้อความ รวมถึงบริบท เมตาดาต้า และความสัมพันธ์ระหว่างจุดข้อมูลต่างๆ
สิ่งนี้หมายความว่าอย่างไรสำหรับผู้ใช้? มันช่วยให้การค้นหาข้อความมีความแม่นยำมากขึ้นและการวิเคราะห์ที่ละเอียดมากขึ้น โดยเฉพาะอย่างยิ่งในสาขาเช่นการวิจัยและอุตสาหกรรมที่มีข้อมูลจำนวนมาก
เมื่อผสานรวมกับเทคโนโลยีเว็บเชิงความหมาย ระบบจะมุ่งเน้นไปที่ สตริงการค้นหาและเจตนาของผู้ใช้ ระบบเหล่านี้สามารถก้าวข้ามการจับคู่ตามตัวอักษรและดึงเอกสารที่มีความเกี่ยวข้องสูง แม้แต่สำหรับคำค้นหาที่ซับซ้อนในกระบวนการค้นคืนข้อมูล
ตัวอย่างเช่น การค้นหา 'ประโยชน์ของการทำงานทางไกล' สามารถให้ผลลัพธ์ที่เกี่ยวข้องกับประสิทธิภาพการทำงาน, สุขภาพจิต, และการบาลานซ์ชีวิตการทำงาน—ทั้งหมดนี้เพราะระบบเข้าใจถึงความเชื่อมโยง
ดึงเอกสารได้อย่างรวดเร็วด้วยการจัดการข้อมูลของ ClickUp
การค้นหาเอกสารสำคัญเพียงฉบับเดียวจากไฟล์ แอปพลิเคชัน และเครื่องมือที่ไม่มีที่สิ้นสุดนั้นช่างเหนื่อยล้า ลองนึกภาพว่าคุณต้องวิเคราะห์เอกสารที่ดึงมาได้ในฐานะนักวิจัย นักศึกษา ผู้เชี่ยวชาญด้านไอที หรือนักวิทยาศาสตร์ข้อมูล—และมันก็กลายเป็นความยุ่งเหยิงของข้อมูลที่ล้นหลาม
แต่ด้วย ClickUp คุณจะไม่ต้องเสียเวลาค้นหาข้อมูลอีกต่อไป
นี่คือโซลูชันครบวงจรที่รวบรวมทุกงานของคุณไว้ในที่เดียว ด้วยฟีเจอร์อย่าง Connected Search และ ClickUp Brain ไม่ว่าคุณจะเก็บข้อมูลไว้ที่ไหน ก็ค้นหา จัดการ และดำเนินการได้อย่างง่ายดายด้วย ClickUp
ทำไมต้องพอใจกับ 'แค่พอใช้' ในเมื่อคุณสามารถมี 'ยอดเยี่ยม' ได้?ลองใช้ ClickUp ฟรีและดูว่ามันเปลี่ยนการทำงานของคุณให้กลายเป็นสิ่งที่กล้าหาญ มีประสิทธิภาพ และหยุดไม่อยู่!