

Вие сте ръководител на отдел и търсите идеалния човек за изпълнение на конкретна задача. С огромното количество данни в компанията, намирането на най-подходящия кандидат е почти невъзможно, особено ако задачата ви е срочна.
Освен това, кой има времето да пита всеки дали има достатъчно знания в дадена област?
Ами ако просто можехте да попитате системата: „На кого е възложена [задача] най-често?“ и да получите незабавен и точен отговор, базиран на реални данни? Това е функцията на системите за извличане на информация.
Тези системи пресяват огромни количества данни, за да намерят точно това, от което се нуждаете.
Сега пренесете тази идея в глобална база данни – IR системата организира огромни количества данни, помагайки ви да намерите най-подходящите отговори за секунди. Този наръчник ще разгледа различни модели за извличане на информация, как работят те и ролята на AI технологиите в IR системата.
⏰ 60-секундно резюме
📌 Системите за извличане на информация (IR) помагат да намерите подходяща информация от големи колекции от данни, като функционират като виртуален асистент, който пресява данните, за да намери това, от което се нуждаете.
📌 IR системите имат ключови компоненти: база данни, индексатор, интерфейс за търсене, процесор за заявки, модели за извличане и механизми за класиране/оценяване.
📌 Използват се четири основни IR модела: Булев (използва оператори AND/OR/NOT), Векторно пространство (представлява документите като вектори), Вероятностен (използва статистически подходи) и Взаимозависимост на термините (анализира взаимоотношенията между термините).
📌 Машинното обучение и обработката на естествен език подобряват IR системите чрез подобряване на разпознаването на модели, класифицирането на резултатите и разбирането на контекста.
📌 Основните предизвикателства включват поверителността на данните, мащабируемостта и поддържането на качеството на данните при обработката на големи масиви от данни.
Какво е извличане на информация (IR)?
Извличането на информация (IR) означава просто намиране на нужната информация от големи колекции от данни, като цифрови библиотеки, бази данни или интернет архиви.
Това е като да имате виртуален асистент, който пресява огромно количество данни, за да ви предостави точно това, от което се нуждаете. *
На пръв поглед потребителят въвежда заявка, често използвайки ключови думи или фрази, за да търси конкретна информация. Зад кулисите, усъвършенствани техники и алгоритми анализират търсените низове и ги съпоставят с подходящи данни.
Вместо да идентифицират само един отговор, IR системите предоставят няколко обекта, всеки от които с различна степен на релевантност към вашата заявка. Освен това, те се използват навсякъде и имат множество приложения (повече за това скоро 🔔).
💡Съвет от професионалист: Трябва да намерите най-квалифицирания човек за дадена задача? Въведете конкретни термини като „анализ на отчетите за продажбите за първото и второто тримесечие, задачи, възложени на“ в системата за извличане на информация. По този начин тя бързо филтрира нерелевантните данни и посочва кой се е занимавал най-много с тях.
Приложения на IR в различни области
От здравеопазването до електронната търговия, IR системите се използват в много области за управление и категоризиране на данни. Ето няколко примера 👇
Здравеопазване
В здравеопазването IR системите сканират бази данни с медицински записи и научни статии, за да помогнат на лекарите и изследователите да намерят най-подходящата информация. В резултат на това те ускоряват диагностицирането на заболявания, идентифицират възможности за лечение и намират най-подходящите проучвания, използвайки релевантна обратна връзка.
Обслужване на клиенти
Техниките за извличане на информация правят обслужването на клиенти по-бързо и по-точно. Например, агентите могат да въведат заявки на потребители като „политика за възстановяване на суми“ в системата на компанията, за да получат незабавни отговори.
AI чатботовете и центровете за помощ, задвижвани от извличането на информация, правят още една крачка напред, предлагайки решения в реално време без човешка намеса. Ето защо вашите въпроси често получават отговор за секунди!
Платформи за електронна търговия
Системите за извличане на информация правят онлайн пазаруването лесно. Те анализират бази данни и съпоставят поведението на клиентите, за да препоръчат продукти, които ще ви харесат.
Например, Amazon използва IR, за да ви предложи артикули въз основа на историята на вашите търсения и предишни покупки, помагайки ви да намерите точно това, от което се нуждаете.
Компоненти на система за извличане на информация
Сега знаем какво е извличане на информация и как работи. Нека разгледаме основните елементи на една IR система. →
1. База данни
Всичко започва с базата данни. Тя е колекция от взаимосвързани данни, като текстови документи, имейли, уеб страници, изображения и видеоклипове. Когато въведете дадена заявка, системата за извличане на информация претърсва тези съвпадения в базата данни, за да извлече най-релевантната информация за вашите нужди.
2. Индексатор
Преди системата да може да извлича нещо, индексаторът организира данните. Това е като подготовка на библиотечен каталог, за да се ускори търсенето. Индексаторът обработва документите по следния начин:
- Токенизация: Разделяне на съдържанието на по-малки части, като разделяне на изречения на думи или фрази (наречени токени).
- Стеминг: Опростяване на думите до тяхната основна форма (например „бягане” става „бягам”).
- Премахване на излишни думи: Пропускане на думи като „и“, „или“ и „на“, за да се фокусирате върху основния въпрос.
- Извличане на ключови думи: Идентифициране на основните ключови думи в текста
- Извличане на метаданни: Извличане на допълнителни подробности като автор, дата на публикуване или заглавие.
3. Интерфейс за търсене
Интерфейсът за търсене действа като вашата врата към системата за извличане на информация. Тук въвеждате заявката си, използвайки прости ключови думи или по-подробни филтри. Проектиран да бъде лесен за използване, той ви гарантира, че можете лесно да съобщите вашите нужди за достъп до информация и да получите подходящите резултати, които търсите.
4. Процесор за заявки
След като натиснете „търсене“, процесорът за заявки поема контрола. Той усъвършенства въведените от вас данни, като прилага техниките, изброени в раздела за индексатори. Освен това, той обработва и булеви оператори като „AND“, „OR“ и „NOT“, за да направи заявката ви по-интелигентна.
5. Модели за извличане
Ето къде се случва магията. Системата сравнява зададения от вас запитване с индексираните документи с помощта на модели за извличане. Тези методи определят как да се съпостави вашето запитване със съхранените данни. Някои от най-често срещаните имена включват:
- Булеви модели
- Векторни пространствени модели
- Вероятностни модели
- И още... (ще бъде обсъдено по-късно)
6. Класиране и оценяване
След като бъдат намерени потенциални съвпадения, системата ги класифицира според релевантността им. Всеки документ получава оценка, като се използват методи като TF-IDF (Term Frequency-Inverse Document Frequency) или други алгоритми. Това гарантира, че най-релевантният резултат се появява на първо място.
7. Презентация или показ
Накрая резултатите ви се представят. Обикновено системата показва класифициран списък с текстови документи с допълнителни функции като откъси, филтри или опции за сортиране. Това улеснява избора на най-подходящия документ. Броят на показаните резултати обаче може да варира в зависимост от вашите предпочитания, заявката или системните настройки.
🔍Знаете ли, че...: Традиционните системи за извличане на информация разчитаха в голяма степен на структурирани бази данни и основно съпоставяне на ключови думи. Резултатът? Значителни проблеми с релевантността и персонализацията.
Тогава съвременните технологии за изкуствен интелект трансформираха извличането на текст чрез:
- Машинно обучение (ML): Помага на IR системите да се учат от моделите в поведението на потребителите и да подобряват резултатите от търсенето с течение на времето.
- Дълбоки невронни мрежи: Алгоритми, които могат да обработват неструктурирани данни (като изображения или видеоклипове) и да разкриват сложни взаимоотношения.
- Обработка на естествен език (NLP): Позволява на системите да разбират значението и контекста на заявките, за да поддържат разпознаване на изображения и анализ на настроения, което прави достъпа до информация по-гъвкав.
Модели за извличане на информация
Съществуват различни IR системи, които оптимизират процеса на намиране на подходящи документи. Нека разгледаме най-широко използваните от тях:
1. Теория на множествата и булеви модели
Булевият модел е една от най-простите техники за извличане на информация. Ето как работи:
- AND: Извлича документи, съдържащи всички термини от заявката. Например, търсене на „котка AND куче“ ще върне документи, в които се споменават и двете думи в търсачката.
- ИЛИ: Намира документи, съдържащи някой от термините в заявката. За „котка ИЛИ куче“ извлича документи, в които се споменават котка, куче или и двете.
- NOT: Изключва документи, съдържащи определен термин. Например, „cat AND NOT dog” връща документи, в които се споменава котка, но не и куче.
Този модел използва концепцията „bag of words” (торба с думи), при която се създава 2D матрица. В тази матрица:
- Колоните представляват документи
- Редовете представляват термини от заявката
На всяка клетка се присвоява стойност 1 (ако терминът е налице) или 0 (ако не е).

✅ Предимства
- Лесно за разбиране и прилагане
- Извлича документи, които точно съответстват на термините от заявката
❌ Недостатъци
- Булевите модели не класифицират документите по релевантност, така че всички резултати се третират като еднакво важни.
- Фокусира се върху точни съвпадения на термини, така че резултатите могат да варират в зависимост от значението или контекста на заявката.
2. Векторни пространствени модели
Векторният пространствен модел е алгебричен модел, който представя както документи, така и заявки като вектори в многоизмерно пространство. Ето как работи:
1. Създава се матрица термин-документ, в която редовете са термини, а колоните са документи.
2. Векторът на заявката се формира въз основа на търсените термини от потребителя.
3. Системата изчислява цифров резултат, използвайки мярка, наречена косинусова подобност, която определя колко точно векторът на заявката съответства на векторите на документа.

Като система за извличане на информация, документите се класират въз основа на тези резултати, като най-високо класираните са най-релевантни.
✅ Предимства
- Извлича елементи, дори ако само някои термини съвпадат
- Разлики в употребата на термини и дължината на документите, съобразени с различни типове документи
❌ Недостатъци
- По-големите речници и колекции от документи правят изчисленията на сходството ресурсоемки.
3. Вероятностни модели
Този модел използва статистически подход, като използва вероятността, за да оцени колко релевантен е даден документ за заявката. Той взема предвид:
- Честота на термините в документа
- Колко често термините се срещат заедно (съвместно появяване)
- Дължина на документа и общ брой термини в заявката
Системата третира процеса на извличане като вероятностно събитие, като класифицира съхранените документи въз основа на вероятността за тяхната релевантност. Този подход добавя дълбочина, като оценява обектите от данни отвъд основното наличие на термини.
✅ Предимства
- Адаптира се добре към различни приложения, включително анализ на надеждността и оценки на потока на натоварването.
❌ Недостатъци
- Разчита на предположения за взаимоотношенията между данните, което може да доведе до подвеждащи резултати.
4. Модели за взаимозависимост на термините
За разлика от по-опростените модели, моделите за взаимозависимост на термините се фокусират върху взаимоотношенията между термините, а не само върху тяхната честота. Тези модели анализират как думите и изразите се отнасят една към друга, за да подобрят точността на резултатите.
Те използват един от двата подхода:
- Иманентен режим: Изследва взаимоотношенията в самия текст.
- Трансцендентен режим: Взема предвид външни данни или контекст, за да направи изводи за взаимоотношенията
Този метод е особено полезен за улавяне на нюанси в значението, като синоними или фрази, специфични за контекста.
✅ Предимства
- Улавя нюансите в езика, като отчита взаимоотношенията между термините.
- Подобрява ефективността на извличането чрез разбиране на зависимостите между термините и контекста.
❌ Недостатъци
- Изисква обширни данни за точно моделиране на взаимоотношенията между термините, които не винаги са налични.
Това е всичко! Това са някои от често използваните системи за извличане на информация, с техните предимства и недостатъци.
➡️ Прочетете още: 4 алтернативи и конкуренти на Spotlight Search
Извличане на информация срещу заявка за данни
Макар и двата термина да изглеждат почти еднакви, те функционират по различен начин. Нека сравним IR и Data Querying, за да видим как се различават по отношение на предназначение, примери за употреба и примери:
| Аспект | Извличане на информация (IR) | Запитване на данни |
| Определение | Действа като търсачка, която претърсва огромно количество данни, за да ви предостави най-релевантните резултати. | Представете си го като задаване на конкретен въпрос на база данни на език, който тя разбира (като SQL). |
| Цел/Предназначение | Помага ви да намерите точна и релевантна информация или ресурси в търсачките – бързо и лесно. | Извлича точни данни, за да можете да анализирате, актуализирате или обработвате цифри. |
| Примери за употреба | Използва се за уеб търсене, препоръки за електронна търговия, цифрови библиотеки, информация за здравеопазването и др. | Идеален за задачи като управление на запасите в електронната търговия, анализ на финансите и оптимизиране на веригите за доставки. |
| Пример | Търсене в Google на „Най-добрите лаптопи между 800 и 1000 долара“, за да получите класифицирани резултати | Задайте заявка към инвентарната си система за „SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000”, за да видите какво има на склад. |
Ролята на машинно обучение и NLP в извличането на информация
Системите за извличане на информация са като ловци на съкровища за данни – те пресяват огромни количества информация, за да намерят точно това, което търсите. Но когато ML и NLP обединят сили, тези системи стават по-умни, по-бързи и много по-точни.
Мислете за ML като мозъка зад IR системите. 🧠
Той помага на системата да се учи, адаптира и подобрява резултатите при всяко търсене на информация. Ето как работи:
- Откриване на модели: ML проучва върху какво кликват потребителите, какво пренебрегват и на какво отделят най-много време за четене. След това използва тази информация, за да ви покаже най-релевантните резултати следващия път.
- Резултати от класирането: ML извлича информация и я класира. Това означава, че най-добрите и най-полезни резултати се появяват в горната част на търсенето ви.
- Адаптиране във времето: С всяко запитване ML става по-добър. Той улавя тенденциите, усъвършенства разбирането си и лесно се справя дори с най-трудните въпроси.
Например, ако днес търсите „най-добри лаптопи на достъпна цена“ и взаимодействате с конкретни резултати, ML ще знае да даде приоритет на подобни опции, когато по-късно търсите „достъпни преносими компютри“. Чрез комбинирането на AI с ML, уеб търсачките могат дори да предскажат какво може да ви е необходимо след това.
Сега нека поговорим за NLP. То помага на IR системите да разберат какво имате предвид, а не само думите, които въвеждате. С прости думи:
- Разбира контекста: NLP знае, че когато казвате „ягуар“, може да имате предвид животното или колата – и го разбира въз основа на останалата част от вашето запитване.
- Работи с комплексен език: Независимо дали вашата заявка е проста („евтини полети“) или подробна („директни полети до Токио под 500 долара“), NLP гарантира, че системата разбира и предоставя правилните резултати.
Заедно, NLP и IR правят търсенето интуитивно, като разговор с някой, който просто ви разбира. Това означава по-малко превъртане, по-малко разочарование и повече моменти от типа „Уау, точно това ми трябваше!“.
Ролята на ClickUp в извличането на информация
ClickUp, „приложението за всичко, свързано с работата“, подобрява управлението на данни с IR модели.
Вградената AI технология уникално идентифицира и съпоставя резултатите с заявката на потребителя, като извежда интелигентната технология на ново ниво.
А за да направим офертата още по-атрактивна, свързаното търсене на ClickUp ви позволява да получите всичко, от което се нуждаете, „незабавно“ на един клик разстояние. Това означава:
- Търсете всичко: Кой обича да претърсва имейли и системи за управление на знания, за да намери важни файлове? Намерете всеки файл за секунди с помощта на опцията Connected Search. Още по-добре, търсете файлове във всичките си свързани приложения и имайте достъп до всичко на едно място.
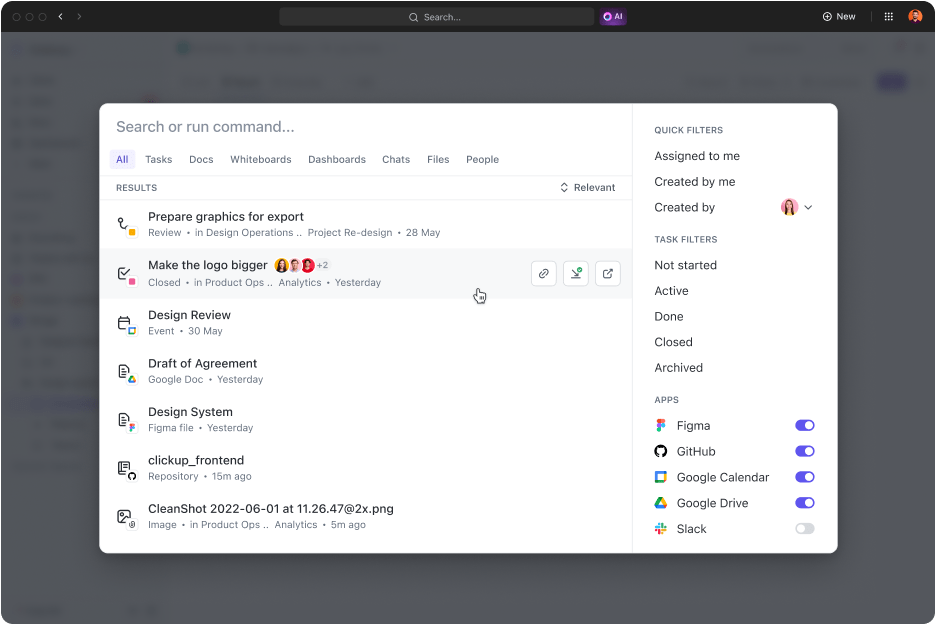
- Свържете любимите си приложения: ClickUp разполага с едни от най-добрите интеграции, които разширяват възможностите му за търсене до приложения на трети страни като Google Drive, Slack, Dropbox, Figma и други.

- Уточнете резултатите: Колкото повече го използвате, толкова по-добре разбира какво търсите и ви предоставя резултати, съобразени специално с вашите нужди.
- Търсете по свой начин: Достъп до Connected Search и бързо търсене в PDF файлове от всяка точка на работното ви пространство. Например, можете да започнете търсене от Command Center, Global Action Bar или от вашия десктоп.
- Създайте персонализирани команди за търсене: Добавете персонализирани команди за търсене, като преки пътища към връзки, съхранение на текст за по-късно и други, за да оптимизирате работния си процес.
Ами ако имаше начин да автоматизирате досадните задачи, да работите по-бързо и да свършите повече работа за по-кратко време?
ClickUp Brain, вграденият AI асистент, прави това реалност за вас. Той е най-добрият асистент за управление на данни – умен, бърз и винаги готов да помогне.
Накратко 👇
- Цялостен център за знания: Никога повече не разчитайте на имейли и съобщения за актуализации. Задавайте всякакви въпроси относно вашите задачи, документи или хора и седнете удобно, докато ClickUp Brain изготвя отговори въз основа на контекста от вътрешни и свързани приложения.

- Намерете по-бързо това, от което се нуждаете: ClickUp Brain класифицира резултатите интелигентно, като усъвършенствана система за извличане на информация. Тя дава приоритет на релевантните файлове, предлага свързани задачи и дори ви помага да откриете скрити работни натоварвания във вашите данни.
- Автоматизирайте задачите: Brain автоматизира създаването на отчети или проследяването на крайни срокове чрез своите AI инструменти. Това е личен асистент, който ви освобождава време за по-важни решения, като същевременно поддържа всичко в ред.
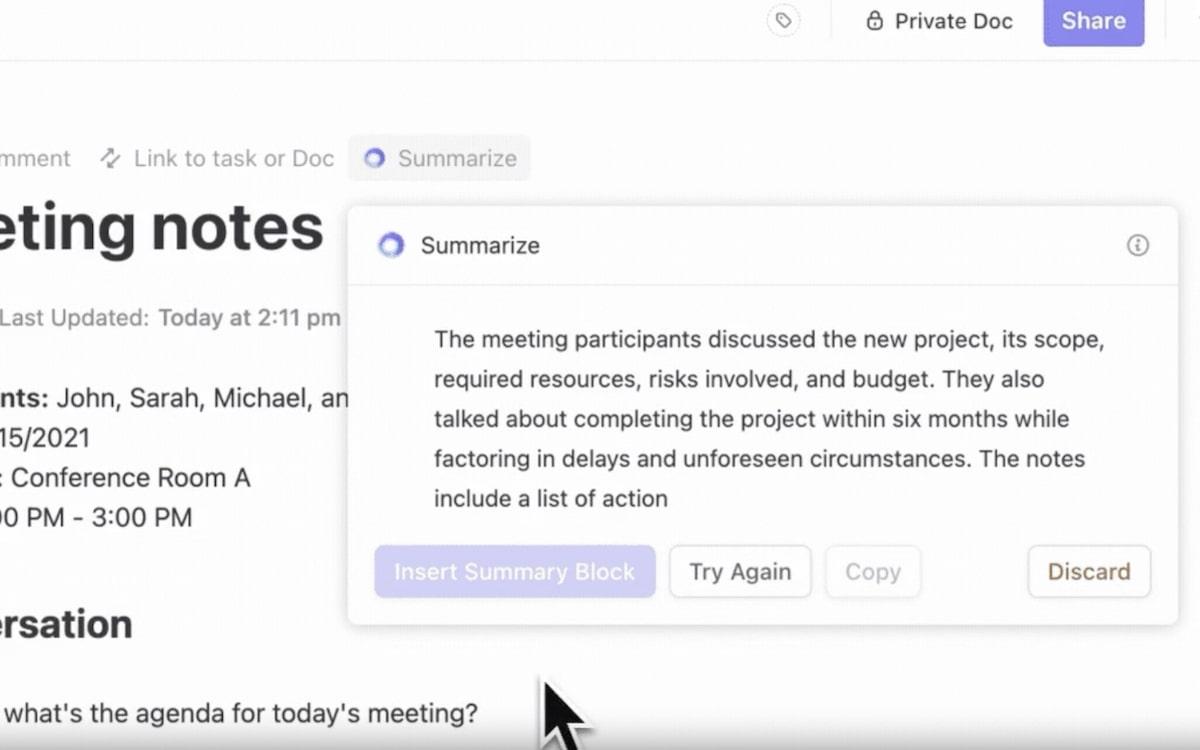
- Контекстно-ориентирано търсене: С помощта на NLP, то разбира вашия въпрос, дори ако той е сложен или неясен. Например, при търсене на „отчет за продажбите за първото тримесечие“ получавате точен отчет, свързан с вашата задача.
➡️ Прочетете още: Какво е система за управление на работата и как да я внедрите?
Предизвикателства и бъдещи насоки в извличането на информация
Светът на извличането на информация се състои в осмислянето на огромни количества данни, но дори и най-модерните IR системи се сблъскват с някои препятствия по пътя.
Нека разгледаме общите предизвикателства и вълнуващите тенденции, които оформят бъдещето на тази важна научна дисциплина:
- Поверителност и сигурност на данните: За да може един IR модел да предоставя фактически резултати, често се налага да има достъп до чувствителни данни. Защитата на потребителските данни обаче не е лесна задача за ресурсите за извличане на информация.
- Мащабируемост и производителност: Когато потребителите търсят в големи масиви от данни, обработката на нарастващото количество съдържание може да претовари дори и най-мощните модели за извличане. Предизвикателството е да се осигури ефективно извличане, без да се компрометира релевантността на резултатите от търсенето.
- Качество на данните и контекстуално разбиране: Неясните заявки или лошо организираните метаданни могат да доведат до несъответствия, което затруднява системата да идентифицира еднозначно намерението на потребителя.
Нови тенденции и напредък в IR технологията
Въпреки многото препятствия, последните технологични постижения ни позволиха да изградим по-умни и по-ефективни системи.
Съвременните системи за извличане на информация вече използват усъвършенствани методи като графичен анализ, за да интерпретират числата, текста и контекста, метаданните и взаимоотношенията между данните.
Какво означава това за потребителите? Това позволява по-прецизно извличане на текст и подробен анализ, особено в области като научните изследвания и индустриите, работещи с големи обеми данни.
В комбинация със семантични уеб технологии, той се фокусира върху търсените низове и намерението на потребителя. Тези системи могат да надхвърлят буквалните съвпадения и да извличат документи с висока релевантност, дори при сложни потребителски запитвания в процеса на извличане на информация.
Например, търсенето на „ползи от дистанционната работа“ може да доведе до резултати, свързани с производителността, психичното здраве и баланса между работата и личния живот – всичко това, защото системата разбира връзките.
Бързо извличане на документи с управлението на данни на ClickUp
Претърсването на безкрайни файлове, приложения и инструменти, за да намерите един важен документ, е изтощително. Представете си, че се опитвате да анализирате извлечените документи като изследовател, студент, ИТ специалист или учен в областта на данните – и това се превръща в хаос от прекалено много информация.
Но с ClickUp никога повече няма да губите време в търсене на информация.
Това е всеобхватно решение, което обединява работата ви на едно място. С функции като Connected Search и ClickUp Brain, няма значение къде се намират данните ви – ClickUp улеснява намирането, управлението и действията с тях.
Защо да се задоволявате с „просто добре“, когато можете да имате „невероятно“? Опитайте ClickUp безплатно и вижте как превръща работния ви процес в нещо смело, ефективно и направо неудържимо!