![Hur man tränar Gemini på dina egna data i [år]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Enligt en färsk företagsundersökning uppger 73 % av organisationerna att deras AI-modeller inte förstår företagsspecifik terminologi och kontext, vilket leder till resultat som kräver omfattande manuell korrigering. Detta blir en av de största utmaningarna med AI-implementering.
Stora språkmodeller som Google Gemini är redan tränade på enorma offentliga datamängder. Det som de flesta företag verkligen behöver är inte att träna en ny modell, utan att lära Gemini om din affärsmiljö: dina dokument, arbetsflöden, kunder och interna kunskaper.
Denna guide leder dig genom hela processen för att träna Googles Gemini-modell på dina egna data. Vi går igenom allt från att förbereda datamängder i rätt JSONL-format till att köra inställningsjobb i Google AI Studio.
Vi undersöker också om en konvergerad arbetsyta med inbyggd AI-kontext kan spara veckor av installationstid.
Vad är finjustering av Gemini och varför är det viktigt?
Finjustering av Gemini är processen att träna Googles grundmodell på dina egna data.
Du vill ha en AI som förstår din verksamhet, men färdiga modeller ger generiska svar som inte träffar rätt. Det innebär att du slösar tid på att ständigt korrigera resultaten, förklara ditt företags terminologi på nytt och bli frustrerad när AI:n inte förstår.
Denna ständiga fram-och-tillbaka-rörelse saktar ner ditt team och undergräver AI:s produktivitetslöfte.
Genom att finjustera Gemini skapas en anpassad Gemini-modell som lär sig dina specifika mönster, tonfall och domänkunskap, vilket gör att den kan svara mer exakt på dina unika användningsfall. Denna metod fungerar bäst för konsekventa, repeterbara uppgifter där basmodellen upprepade gånger misslyckas.
Hur finjustering skiljer sig från prompt engineering
Prompt engineering innebär att du ger modellen tillfälliga, sessionsbaserade instruktioner varje gång du interagerar med den. När konversationen är avslutad glömmer modellen ditt sammanhang.
Denna metod når sin gräns när ditt användningsfall kräver specialkunskaper som basmodellen helt enkelt inte har. Du kan bara ge ett begränsat antal instruktioner innan modellen måste lära sig dina mönster.
Finjustering däremot justerar modellens beteende permanent genom att modifiera dess interna vikter baserat på dina tränings exempel, så att ändringarna kvarstår i alla framtida sessioner.
Finjustering är inte en snabb lösning på tillfälliga AI-frustrationer, utan en betydande investering i tid och data. Det är mest meningsfullt i specifika scenarier där basmodellen konsekvent brister och du behöver en permanent lösning.
Överväg finjustering när du behöver AI:n för att behärska:
- Specialiserad terminologi: Din bransch använder jargong som modellen konsekvent misstolkar eller inte använder korrekt.
- Konsekvent utdataformat: Du behöver svar i en mycket specifik struktur varje gång, till exempel för att generera rapporter eller kodsnuttar.
- Domänkunskap: Modellen saknar kunskap om dina nischprodukter, interna processer eller egna arbetsflöden.
- Varumärkesröst: Du vill att alla AI-genererade resultat ska matcha ditt företags varumärkesröst, stil och personlighet perfekt.
| Aspekt | Prompt engineering | Finjustering |
| Vad är det? | Skapa bättre instruktioner i prompten för att styra modellens beteende | Träna modellen ytterligare med dina egna exempel |
| Vilka förändringar | Den input du skickar till modellen | Modellens interna vikter |
| Snabb implementering | Omedelbar – fungerar direkt | Långsam – kräver förberedelse av dataset och träningstid |
| Teknisk komplexitet | Låg – ingen ML-expertis krävs | Medelhög till hög – kräver ML-pipelines |
| Data som krävs | Några bra exempel i prompten | Hundratals till tusentals märkta exempel |
| Konsistens i resultatet | Medium – varierar mellan olika uppmaningar | Hög – beteendet är inbyggt i modellen |
| Bäst för | Engångsuppgifter, experiment, snabb iteration | Repetitiva uppgifter som kräver konsekventa resultat |
Prompt engineering formar vad du säger till modellen. Finjustering formar hur modellen tänker.
Även om den här artikeln fokuserar på Gemini kan förståelsen för alternativa metoder för AI-anpassning ge värdefulla perspektiv på olika metoder för att uppnå liknande mål.
Den här videon visar hur du skapar en anpassad GPT, en annan populär metod för att skräddarsy AI för specifika användningsfall:
📖 Läs också: Hur man blir en promptingenjör
Hur du förbereder dina träningsdata för Gemini
De flesta finjusteringsprojekt misslyckas redan innan de ens har startat eftersom teamen underskattar dataprepareringsprocessen. Gartner förutspår att 60 % av AI-projekten kommer att överges på grund av otillräckliga AI-klara data.
Du kan spendera veckor på att samla in och formatera data på fel sätt, bara för att träningen misslyckas eller resulterar i en oanvändbar modell. Detta är ofta den mest tidskrävande delen av hela processen, men att göra det rätt är den enskilt viktigaste faktorn för att lyckas.
Principen ”skräp in, skräp ut” gäller i hög grad här. Kvaliteten på din anpassade modell kommer att vara en direkt återspegling av kvaliteten på de data du tränar den på.
Krav på datasetformat
Gemini kräver att dina träningsdata har ett specifikt format som kallas JSONL, vilket står för JSON Lines. I en JSONL-fil är varje rad ett komplett, fristående JSON-objekt som representerar ett tränings exempel. Denna struktur gör det enkelt för systemet att bearbeta stora datamängder en rad i taget.
Varje träningsexempel måste innehålla två nyckelfält:
- text_input: Detta är den fråga eller uppmaning du skulle ställa till modellen.
- utdata: Detta är det ideala, perfekta svaret som du vill att modellen ska lära sig att producera.
För enkelhetens skull accepterar Google AI Studio även uppladdningar i CSV-format och konverterar dem till den erforderliga JSONL-strukturen åt dig.
Detta kan göra den initiala datainmatningen lite enklare om ditt team är mer vana vid att arbeta i kalkylblad.
Rekommendationer för datamängdens storlek
Även om kvalitet är viktigare än kvantitet behöver du ändå ett minimalt antal exempel för att modellen ska kunna känna igen och lära sig mönster. Om du börjar med för få exempel kommer modellen inte att kunna generalisera eller fungera tillförlitligt.
Här är några allmänna riktlinjer för datamängdens storlek:
- Minsta möjliga: För enkla, mycket specifika uppgifter kan du börja se resultat med cirka 100 till 500 högkvalitativa exempel.
- Bättre resultat: För mer komplexa eller nyanserade resultat bör du sträva efter 500 till 1 000 exempel för att få en mer robust och tillförlitlig modell.
- Avtagande avkastning: Vid en viss punkt kommer det inte att förbättra prestandan nämnvärt att bara lägga till mer repetitiva data. Fokusera på mångfald och kvalitet framför ren volym.
Att samla in hundratals högkvalitativa exempel är en stor utmaning för de flesta team. Planera denna datainsamlingsfas noggrant innan du påbörjar finjusteringsprocessen.
📮 ClickUp Insight: En genomsnittlig yrkesverksam person lägger mer än 30 minuter om dagen på att söka efter arbetsrelaterad information – det innebär att över 120 timmar om året går förlorade på att söka igenom e-postmeddelanden, Slack-trådar och spridda filer.
En intelligent AI-assistent inbyggd i din arbetsyta kan ändra på det. Presentera ClickUp Brain. Den ger omedelbara insikter och svar genom att visa rätt dokument, konversationer och uppgiftsdetaljer på några sekunder – så att du kan sluta söka och börja arbeta.
💫 Verkliga resultat: Team som QubicaAMF har sparat över 5 timmar per vecka med hjälp av ClickUp – det är över 250 timmar per person och år – genom att eliminera föråldrade processer för kunskapshantering. Tänk vad ditt team skulle kunna åstadkomma med en extra produktiv vecka varje kvartal!
Bästa praxis för datakvalitet
Inkonsekventa eller motstridiga exempel kommer att förvirra modellen, vilket leder till opålitliga och oförutsägbara resultat. För att undvika detta måste dina träningsdata noggrant sammanställas och rensas. Ett enda dåligt exempel kan förstöra lärandet från många bra exempel.
Följ dessa riktlinjer för att säkerställa hög datakvalitet:
- Konsistens: Alla exempel ska följa samma format, stil och ton. Om du vill att AI:n ska vara formell ska alla dina utdataexempel vara formella.
- Mångfald: Din dataset bör täcka hela spektrumet av indata som modellen sannolikt kommer att möta i verklig användning. Träna inte bara på de enkla fallen.
- Noggrannhet: Varje enskilt utdataexempel måste vara perfekt. Det ska vara exakt det svar du vill att modellen ska producera, utan några fel eller stavfel.
- Renlighet: Innan träningen måste du ta bort dubbla exempel, korrigera alla stav- och grammatikfel och lösa eventuella motsägelser i data.
Vi rekommenderar starkt att flera personer granskar och validerar träningsexemplen. Ett par friska ögon kan ofta upptäcka fel eller inkonsekvenser som du kanske har missat.
Hur du finjusterar Gemini steg för steg
Finjusteringsprocessen för Gemini omfattar flera tekniska steg på Googles plattformar. En enda felkonfiguration kan slösa bort timmar av värdefull träningstid och beräkningsresurser, vilket tvingar dig att börja om från början. Denna praktiska genomgång är utformad för att minska behovet av trial-and-error och guidar dig genom processen från början till slut. 🛠️
Innan du börjar behöver du ett Google Cloud-konto med aktiverad fakturering och åtkomst till Google AI Studio. Avsätt minst några timmar för den initiala installationen och ditt första träningsjobb, plus ytterligare tid för att testa och iterera din modell.
Steg 1: Konfigurera Google AI Studio
Google AI Studio är ett webbaserat gränssnitt där du kan hantera hela finjusteringsprocessen. Det är ett användarvänligt sätt att ladda upp data, konfigurera träning och testa din anpassade modell utan att behöva skriva kod.
Gå först till ai.google.dev och logga in med ditt Google-konto.
Du måste godkänna användarvillkoren och skapa ett nytt projekt i Google Cloud Console om du inte redan har ett. Se till att du aktiverar de nödvändiga API:erna enligt anvisningarna på plattformen.
Steg 2: Ladda upp din träningsdatauppsättning
När du är klar med installationen går du till inställningsavsnittet i Google AI Studio. Här börjar du processen med att skapa din anpassade modell.
Välj alternativet ”Skapa justerad modell” och välj din basmodell. Gemini 1. 5 Flash är ett vanligt och kostnadseffektivt val för finjustering.
Ladda sedan upp JSONL- eller CSV-filen som innehåller din förberedda träningsdatabas. Plattformen validerar sedan din fil för att säkerställa att den uppfyller formateringskraven och markerar vanliga fel som saknade fält eller felaktig struktur.
Steg 3: Konfigurera dina finjusteringsinställningar
När dina data har laddats upp och validerats konfigurerar du träningsparametrarna. Dessa inställningar, som kallas hyperparametrar, styr hur modellen lär sig av dina data.
De viktigaste alternativen du kommer att se är:
- Epoker: Detta avgör hur många gånger modellen kommer att träna på hela din dataset. Fler epoker kan leda till bättre inlärning, men också riskera överanpassning.
- Inlärningshastighet: Detta styr hur aggressivt modellen justerar sina vikter baserat på dina exempel.
- Batchstorlek: Detta anger hur många träningsexempel som bearbetas tillsammans i en enda grupp.
För ditt första försök är det bäst att börja med de standardinställningar som rekommenderas av Google AI Studio. Plattformen förenklar dessa komplexa beslut och gör dem tillgängliga även om du inte är expert på maskininlärning.
Steg 4: Kör inställningsjobbet
När du har konfigurerat dina inställningar kan du starta finjusteringen. Googles servrar börjar bearbeta dina data och justera modellens parametrar. Träningsprocessen kan ta allt från några minuter till flera timmar, beroende på storleken på din dataset och den modell du har valt.
Du kan övervaka jobbet direkt i Google AI Studio-instrumentpanelen. Eftersom jobbet körs på Googles servrar kan du stänga webbläsaren och komma tillbaka senare för att kontrollera statusen. Om ett jobb misslyckas beror det nästan alltid på ett problem med kvaliteten eller formateringen av dina träningsdata.
Steg 5: Testa din anpassade modell
När träningen är klar är din anpassade modell redo att testas. ✨
Du kan komma åt den via playground-gränssnittet i Google AI Studio.
Börja med att skicka testfrågor som liknar dina tränings exempel för att verifiera dess noggrannhet. Testa sedan på gränsfall och nya variationer som den inte har sett tidigare för att utvärdera dess förmåga att generalisera.
- Noggrannhet: Ger den exakt de resultat som du har tränat den för?
- Generalisering: Hanterar den korrekt nya indata som liknar men inte är identiska med dina träningsdata?
- Konsistens: Är dess svar tillförlitliga och förutsägbara vid flera försök med samma prompt?
Om resultaten inte är tillfredsställande måste du troligen gå tillbaka, förbättra dina träningsdata genom att lägga till fler exempel eller åtgärda inkonsekvenser och sedan träna om modellen.
Bästa praxis för att träna Gemini på anpassade data
Att bara följa de tekniska stegen garanterar inte en bra modell. Många team slutför processen bara för att bli besvikna på resultaten eftersom de missar de optimeringsstrategier som erfarna praktiker använder. Det är detta som skiljer en funktionell modell från en högpresterande modell.
Det är inte förvånande att Deloittes rapport State of Generative AI in the Enterprise visar att två tredjedelar av företagen uppger att 30 % eller mindre av deras gen-AI-experiment kommer att skalas upp fullt ut inom sex månader.
Genom att följa dessa bästa praxis sparar du tid och får ett mycket bättre resultat.
- Börja i liten skala och skala sedan upp: Innan du påbörjar en fullständig träningsomgång bör du testa din metod med en liten delmängd av dina data (t.ex. 100 exempel). På så sätt kan du validera ditt dataformat och snabbt få en uppfattning om prestandan utan att slösa bort timmar.
- Versionshantera dina datamängder: När du lägger till, tar bort eller redigerar tränings exempel, spara varje version av din datamängd. Detta gör att du kan spåra ändringar, reproducera resultat och återgå till en tidigare version om en ny version fungerar sämre.
- Testa före och efter: Innan du börjar finjustera, fastställ en baslinje genom att utvärdera basmodellens prestanda på dina viktigaste uppgifter. Detta gör att du objektivt kan mäta hur mycket förbättring dina finjusteringar har åstadkommit.
- Iterera på fel: När din anpassade modell ger ett felaktigt eller dåligt formaterat svar, bli inte frustrerad. Lägg till det specifika felet som ett nytt, korrigerat exempel i dina träningsdata för nästa iteration.
- Dokumentera din process: För logg över varje träningsomgång och notera vilken version av datasetet som använts, hyperparametrarna och resultaten. Denna dokumentation är ovärderlig för att förstå vad som fungerar och vad som inte fungerar över tid.
Att hantera dessa iterationer, datauppsättningsversioner och dokumentation kräver robust projektledning. Genom att centralisera detta arbete i en plattform som är utformad för strukturerade arbetsflöden kan du förhindra att processen blir kaotisk.
Vanliga utmaningar vid träning av Gemini
Team investerar ofta mycket tid och resurser i finjustering, bara för att stöta på förutsägbara hinder som leder till slöseri med tid och frustration. Att känna till dessa vanliga fallgropar i förväg kan hjälpa dig att navigera genom processen på ett smidigare sätt.
Här är några av de vanligaste utmaningarna och hur du hanterar dem:
- Överanpassning: Detta inträffar när modellen memorerar dina tränings exempel perfekt men misslyckas med att generalisera till nya, osedda ingångar. För att åtgärda detta kan du lägga till mer mångfald i dina träningsdata, överväga att minska antalet epoker eller utforska alternativa metoder som återvinningsförstärkt generering.
- Inkonsekventa resultat: Om modellen ger olika svar på mycket liknande frågor beror det troligen på att dina träningsdata innehåller motstridiga eller inkonsekventa exempel. En grundlig datarensning krävs för att lösa dessa konflikter.
- Formatförskjutning: Ibland börjar en modell följa den önskade utdatastrukturen, men avviker sedan från den med tiden. Lösningen är att inkludera tydliga formatinstruktioner i utdata från dina tränings exempel, inte bara innehållet.
- Långsamma iterationscykler: När varje träningsomgång tar flera timmar går det betydligt långsammare att experimentera och förbättra. Testa dina idéer på mindre datamängder först för att få snabbare feedback innan du startar en fullständig träningsomgång.
- Flaskhals vid datainsamling: Ofta är det svåraste att samla in tillräckligt med högkvalitativa exempel, vilket kan vara en flaskhals vid datainsamlingen. Börja med att utnyttja ditt bästa befintliga innehåll, till exempel supportärenden, marknadsföringstexter eller tekniska dokument, och utgå från det.
Dessa utmaningar är en viktig anledning till att många team i slutändan söker alternativ till den manuella finjusteringsprocessen.
📮ClickUp Insight: 88 % av våra undersökningsdeltagare använder AI för sina personliga uppgifter, men över 50 % drar sig för att använda det på jobbet. De tre största hindren? Brist på sömlös integration, kunskapsluckor eller säkerhetsproblem. Men vad händer om AI är inbyggt i din arbetsyta och redan är säkert? ClickUp Brain, ClickUps inbyggda AI-assistent, gör detta till verklighet. Den förstår kommandon i klarspråk och löser alla tre problemen med AI-användning samtidigt som den kopplar samman din chatt, dina uppgifter, dokument och kunskap i hela arbetsytan. Hitta svar och insikter med ett enda klick!
Varför ClickUp är ett smartare alternativ
Att finjustera Gemini är kraftfullt – men det är också en tillfällig lösning.
I denna artikel har vi sett att finjustering i slutändan handlar om en sak: att lära AI att förstå ditt företags sammanhang. Problemet är att finjustering gör detta indirekt. Du förbereder datamängder, konstruerar exempel, tränar om modeller och underhåller pipelines, allt för att AI ska kunna approximera hur ditt team arbetar.
Det är vettigt för specialiserade användningsfall. Men för de flesta team är det verkliga målet inte Gemini-anpassning för dess egen skull. Målet är enklare:
Du vill ha AI som förstår ditt arbete.
Det är här ClickUp har en helt annan – och smartare – approach.
ClickUps Converged AI Workspace ger ditt team en AI som omedelbart förstår ditt arbetssammanhang – utan att du behöver göra något extra. Istället för att träna AI att lära sig ditt sammanhang senare, arbetar du med ClickUp Brain, den integrerade AI-assistenten, där ditt sammanhang redan finns.
Dina uppgifter, dokument, kommentarer, projekthistorik och beslut är integrerade. Du behöver inte träna AI:n på dina data eftersom den redan finns där du arbetar och utnyttjar ditt befintliga ekosystem för kunskapshantering.
| Aspekt | Gemini-finjustering | ClickUp Brain |
|---|---|---|
| Installationstid | Dagar till veckor av datapreparering | Omedelbar – fungerar med befintliga arbetsytedata |
| Kontextkälla | Manuellt utvalda tränings exempel | Automatisk åtkomst till allt anslutet arbete |
| Underhåll | Omskola när dina behov förändras | Uppdateras kontinuerligt i takt med att din arbetsmiljö utvecklas |
| Tekniska kunskaper krävs | Medel till hög | Ingen |
Eftersom ClickUp är ditt arbetssystem fungerar ClickUp Brain inuti din anslutna datagraf. Det finns ingen AI-spridning över icke-anslutna verktyg, inga bräckliga träningspipelines och ingen risk att modellen hamnar ur synk med hur ditt team faktiskt arbetar.
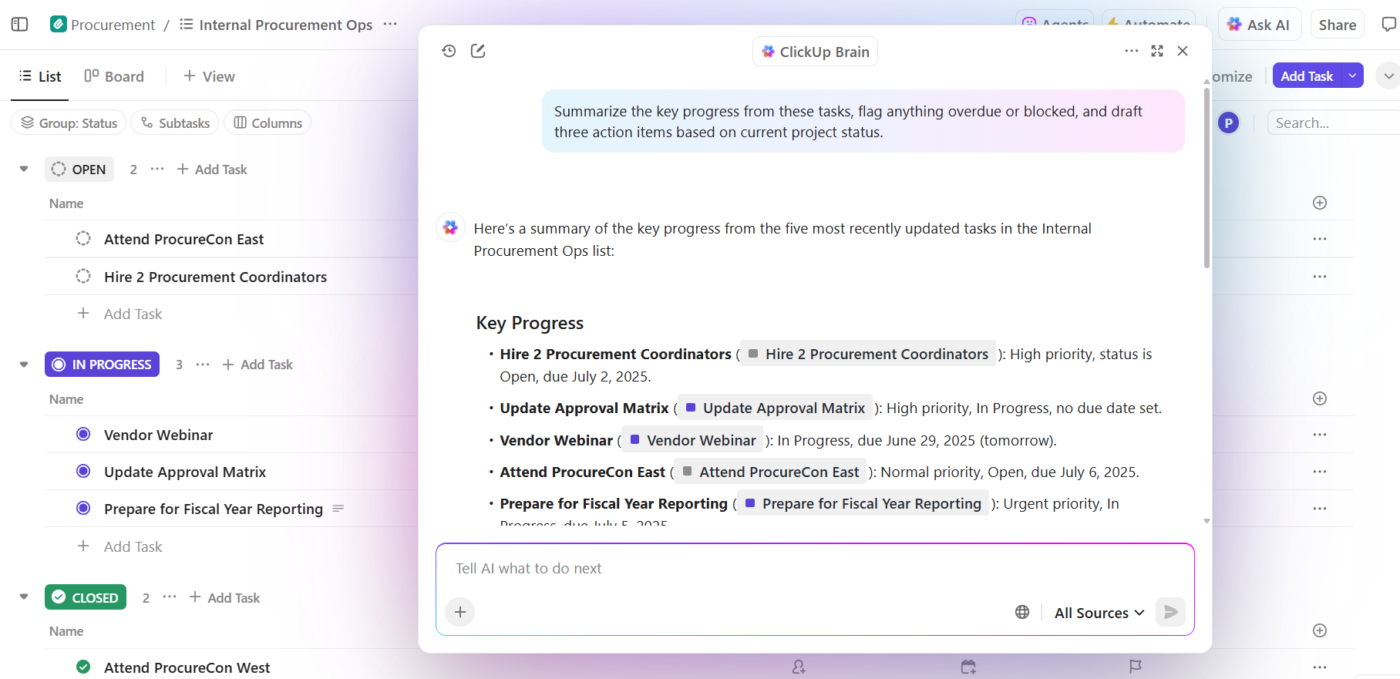
Så här ser det ut i praktiken:
- Ställ frågor om dina projekt: ClickUp Brain söker igenom arbetsytan bland uppgifter, dokument, kommentarer och uppdateringar för att besvara frågor med hjälp av dina verkliga projektdata – inte generisk träningskunskap.
- Skapa innehåll med sammanhang: ClickUp Brain har redan säker åtkomst till dina uppgifter, filer, kommentarer och projekthistorik. Det kan skapa dokument, sammanfattningar och statusuppdateringar som hänvisar till ditt faktiska arbete, tidslinjer och prioriteringar. Inget mer sammanhangsspridning, där teamen slösar timmar på att söka efter information i olika appar och filer.
- Automatisera med förståelse: Med ClickUp Automations kan du skapa automatiseringar som reagerar intelligent på projektets sammanhang, såsom deadlines, ägarskap och statusförändringar, och inte bara statiska regler. AI kan till och med skapa dessa åt dig, utan att någon kod krävs.
💡Proffstips: Utnyttja AI:s verkliga kraft i din arbetsmiljö med ClickUp Super Agents.
Superagenter är ClickUps AI-drivna teammedlemmar – konfigurerade som AI-”användare” som arbetar tillsammans med ditt team i arbetsytan. De är omgivningsanpassade och kontextuella och kan tilldelas uppgifter, nämnas i kommentarer, triggas av händelser eller scheman eller styras via chatt – precis som en mänsklig teammedlem.
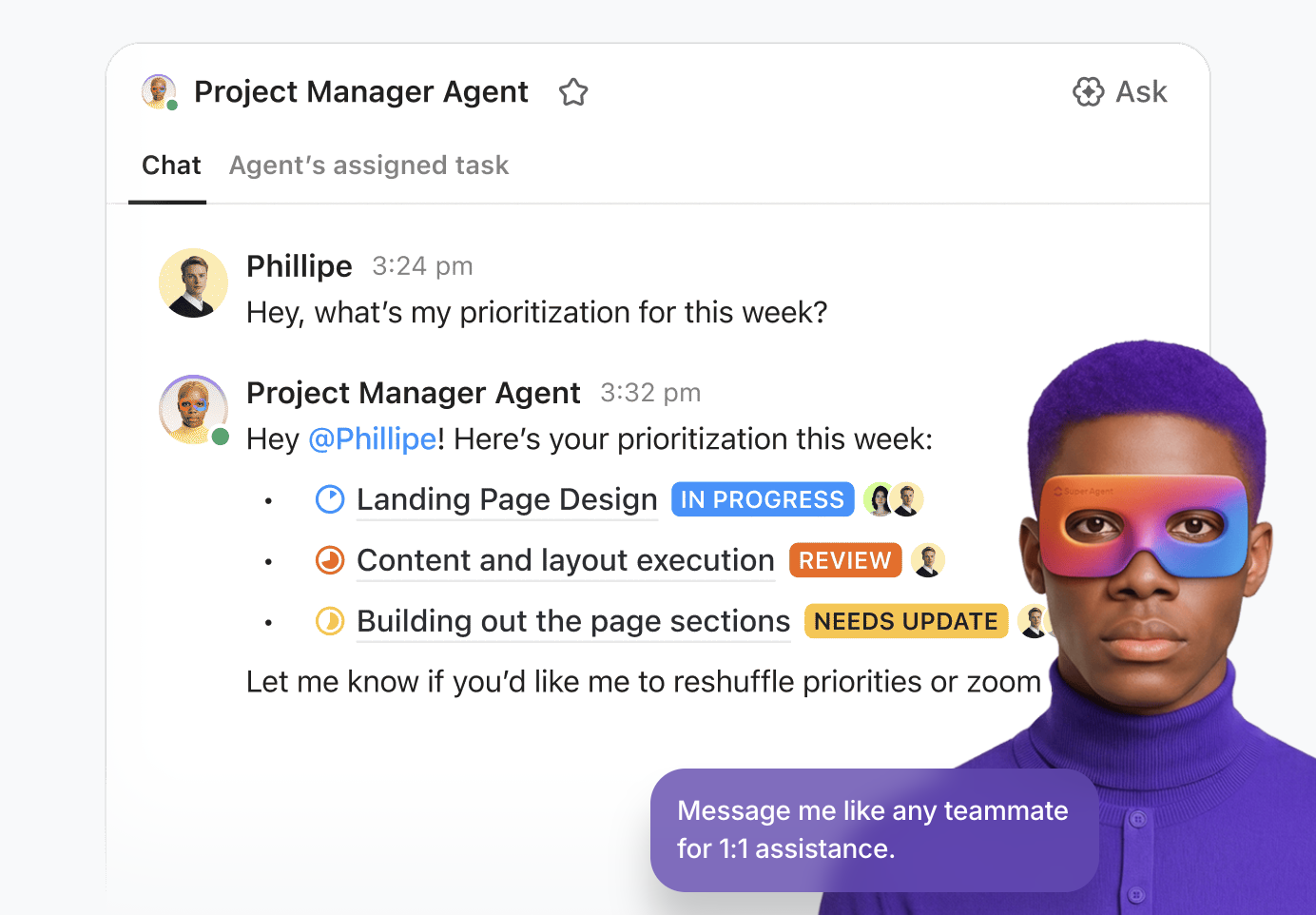
Du kan bygga och distribuera dem med hjälp av den kodfria visuella byggaren som låter dig:
- Identifiera start händelsen, till exempel ett meddelande eller en förändring i uppgiftsstatus.
- Skissera operativa regler, inklusive hur man sammanfattar data, delegerar arbete eller justerar prioriteringar.
- Utför externa åtgärder via integrerade verktyg och tillägg
- Tillhandahåll stödjande data genom att ansluta agenten till relevanta kunskapsbaser.
Läs mer om Super Agents i videon nedan.
Finjustera din AI-strategi: Skaffa ClickUp
Finjustering lär en AI dina mönster genom statiska exempel, men genom att använda konvergerad programvara i en arbetsyta som ClickUp elimineras kontextförvirring genom att din AI får live, automatisk kontext.
Detta är kärnan i en framgångsrik AI-omvandling: team som centraliserar sitt arbete i en ansluten plattform lägger mindre tid på att träna AI och mer tid på att dra nytta av den. När din arbetsplats utvecklas utvecklas din AI automatiskt – utan behov av omskolning.
Är du redo att hoppa över träningen och börja med AI som redan känner till ditt arbete? Kom igång gratis med ClickUp och upplev fördelarna med en samlad arbetsplats.
Vanliga frågor (FAQ)
Din finjusterade modell lär sig av dina tränings exempel, men Googles basmodell Gemini behåller eller lär sig inte från dina konversationsdata som standard. Din anpassade modell är separat från den grundläggande modellen som används av andra användare.
Själva träningen tar kanske bara några timmar, men det är förberedelsen av högkvalitativa träningsdata som tar mest tid. Denna fas kan ofta ta dagar eller till och med veckor att genomföra på ett korrekt sätt.
Ja, du kan finjustera en modell utan att skriva kod med hjälp av Google AI Studio. Det erbjuder ett visuellt gränssnitt som hanterar det mesta av den tekniska komplexiteten, men du måste fortfarande förstå kraven på dataformatering.
Anpassade instruktioner är tillfälliga, sessionsbaserade uppmaningar som styr modellens beteende under en enskild konversation. Finjustering justerar däremot permanent modellens interna parametrar baserat på dina träningsexempel, vilket skapar varaktiga förändringar i dess beteende.