![Hogyan képezze a Gemini-t a saját adataival [év]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Egy friss vállalati tanulmány szerint a szervezetek 73%-a jelenti, hogy mesterséges intelligencia modelljeik nem értik a vállalatspecifikus terminológiát és kontextust, ami miatt a kimenetek jelentős kézi javítást igényelnek. Ez az egyik legnagyobb kihívás a mesterséges intelligencia bevezetése során.
A Google Geminihez hasonló nagy nyelvi modellek már hatalmas nyilvános adatkészleteken vannak betanítva. A legtöbb vállalatnak valójában nem új modell betanítására van szüksége, hanem arra, hogy megtanítsa a Gemini-nek az üzleti környezetét: dokumentumait, munkafolyamatait, ügyfeleit és belső tudását.
Ez az útmutató végigvezeti Önt a Google Gemini modell saját adataival történő betanításának teljes folyamatán. Mindent áttekintünk, a megfelelő JSONL formátumú adatkészletek előkészítésétől a Google AI Studio-ban végzett beállítási feladatok futtatásáig.
Azt is megvizsgáljuk, hogy egy beépített AI-kontextussal rendelkező konvergens munkaterület hetekkel csökkentheti-e a beállítási időt.
Mi az a Gemini finomhangolás és miért fontos?
A Gemini finomhangolása az a folyamat, amelynek során a Google alapmodelljét a saját adataival képezi ki.
Olyan mesterséges intelligenciát szeretne, amely megérti az üzleti tevékenységét, de a kész modellek általános válaszokat adnak, amelyek nem találják el a célt. Ez azt jelenti, hogy időt pazarol a kimenetek folyamatos javítására, a vállalat terminológiájának újbóli elmagyarázására, és frusztrált lesz, amikor a mesterséges intelligencia egyszerűen nem érti meg.
Ez a folyamatos oda-vissza mozgás lassítja a csapat munkáját és aláássa az AI termelékenységi ígéretét.
A Gemini finomhangolásával egy egyedi Gemini-modell jön létre, amely megtanulja az Ön konkrét mintáit, hangnemét és domain-ismereteit, így pontosabban tud reagálni az Ön egyedi felhasználási eseteire. Ez a megközelítés leginkább konzisztens, ismételhető feladatok esetén működik jól, ahol az alapmodell ismétlődően kudarcot vall.
Miben különbözik a finomhangolás a prompt engineeringtől?
A prompt engineering során minden egyes interakció alkalmával ideiglenes, munkamenet-alapú utasításokat ad a modellnek. A beszélgetés befejezése után a modell elfelejti a kontextust.
Ez a megközelítés akkor ütközik korlátokba, ha az Ön felhasználási esete olyan speciális ismereteket igényel, amelyekkel az alapmodell egyszerűen nem rendelkezik. Csak korlátozott számú utasítást adhat meg, mielőtt a modellnek ténylegesen meg kell tanulnia a mintáit.
Ezzel szemben a finomhangolás véglegesen módosítja a modell viselkedését azáltal, hogy a képzési példák alapján megváltoztatja a modell belső súlyait, így a változások minden jövőbeli munkamenetben megmaradnak.
A finomhangolás nem egy gyors megoldás az AI-vel kapcsolatos alkalmi frusztrációkra; jelentős idő- és adatbefektetést igényel. Leginkább olyan speciális esetekben van értelme, amikor az alapmodell következetesen nem felel meg, és állandó megoldásra van szükség.
Fontolja meg a finomhangolást, ha az AI-nak el kell sajátítania a következőket:
- Szakmai terminológia: Az Ön iparágában olyan szakszavakat használnak, amelyeket a modell következetesen félreértelmez vagy nem használ helyesen.
- Következetes kimeneti formátum: Minden alkalommal nagyon specifikus szerkezetű válaszokra van szüksége, például jelentések vagy kódrészletek generálásához.
- Szakterületi szakértelem: A modell nem rendelkezik ismeretekkel a niche termékekről, a belső folyamatokról vagy a saját fejlesztésű munkafolyamatokról.
- Márka hangja: Szeretné, ha az AI által generált összes kimenet tökéletesen illeszkedne vállalatának márka hangjához, stílusához és személyiségéhez.
| Aspect | Prompt engineering | Finomhangolás |
| Mi ez? | Jobb utasítások kidolgozása a promptban a modell viselkedésének irányításához | A modell továbbképzése a saját példáival |
| Milyen változások | A modellnek elküldött bemeneti adatok | A modell belső súlyozása |
| Gyors megvalósítás | Azonnali – azonnal működik | Lassú – adatállomány előkészítést és képzési időt igényel |
| Műszaki komplexitás | Alacsony – nincs szükség gépi tanulási szakértelemre | Közepes-magas – ML-pipeline-ok szükségesek |
| Szükséges adatok | Néhány jó példa a promptban | Több száz vagy több ezer címkézett példa |
| A kimenet konzisztenciája | Közepes – a promptok között eltérő | Magas – a viselkedés beépül a modellbe |
| Legalkalmasabb | Egyszeri feladatok, kísérletek, gyors iteráció | Ismétlődő feladatok, amelyek konzisztens eredményeket igényelnek |
A prompt engineering alakítja, amit a modellnek mond. A finomhangolás alakítja, ahogy a modell gondolkodik.
Bár ez a cikk a Gemini-re összpontosít, az AI testreszabásának alternatív megközelítéseinek megértése értékes perspektívát nyújthat a hasonló célok elérésének különböző módszereiről.
Ez a videó bemutatja , hogyan lehet egyedi GPT-t létrehozni, ami egy másik népszerű módszer az AI-t konkrét felhasználási esetekhez igazítani:
📖 Olvassa el még: Hogyan lehet prompt mérnök?
Hogyan készítse elő a Gemini számára a képzési adatokat
A legtöbb finomhangolási projekt még meg sem kezdődik, máris kudarcot vall, mert a csapatok alábecsülik az adatelőkészítési folyamatot. A Gartner előrejelzése szerint az AI-projektek 60%-a az AI-kompatibilis adatok hiányossága miatt kerül elvetésre.
Heteket tölthet el az adatok helytelen összegyűjtésével és formázásával, csak azért, hogy a képzési feladat kudarcba fulladjon, vagy haszontalan modellt eredményezzen. Ez gyakran a teljes folyamat legidőigényesebb része, de a helyes elvégzése a siker legfontosabb tényezője.
Itt nagyon fontos a „garbage in, garbage out” elv. Az egyéni modell minősége közvetlenül tükrözi a képzéshez használt adatok minőségét.
Adatkészlet formátum követelmények
A Gemini megköveteli, hogy a képzési adatok egy JSONL nevű speciális formátumban legyenek, amely a JSON Lines rövidítése. A JSONL fájlban minden sor egy teljes, önálló JSON objektum, amely egy képzési példát képvisel. Ez a struktúra megkönnyíti a rendszer számára a nagy adathalmazok soronkénti feldolgozását.
Minden képzési példának két kulcsmezőt kell tartalmaznia:
- text_input: Ez az a kérdés vagy felvetés, amelyet a modellnek feltesz.
- kimenet: Ez az ideális, tökéletes válasz, amelyet a modellnek meg kell tanulnia előállítani.
A kényelem érdekében a Google AI Studio CSV formátumú fájlokat is elfogad, és azokat a szükséges JSONL struktúrába konvertálja.
Ez megkönnyítheti a kezdeti adatbevitelét, ha csapata jobban szereti a táblázatokkal dolgozni.
Ajánlott adatkészlet méret
Bár a minőség fontosabb, mint a mennyiség, mégis szükség van egy minimális számú példára ahhoz, hogy a modell felismerje és megtanulja a mintákat. Túl kevés példával kezdve olyan modell jön létre, amely nem képes általánosítani és megbízhatóan működni.
Íme néhány általános irányelv az adatkészlet méretére vonatkozóan:
- Minimális megvalósíthatóság: Egyszerű, nagyon specifikus feladatok esetén körülbelül 100–500 kiváló minőségű példával már látható eredményeket érhet el.
- Jobb eredmények: összetettebb vagy árnyaltabb kimenetek esetén 500–1000 példa megadása robusztusabb és megbízhatóbb modellt eredményez.
- Csökkenő hozam: Egy bizonyos ponton a több ismétlődő adat hozzáadása már nem javítja jelentősen a teljesítményt. A puszta mennyiség helyett a sokszínűségre és a minőségre koncentráljon.
Több száz kiváló minőségű példa összegyűjtése jelentős kihívást jelent a legtöbb csapat számára. A finomhangolási folyamat megkezdése előtt megfelelően tervezze meg ezt az adatgyűjtési fázist.
📮 ClickUp Insight: Az átlagos szakember naponta több mint 30 percet tölt munkával kapcsolatos információk keresésével – ez évente több mint 120 óra, amelyet e-mailek, Slack-szálak és szétszórt fájlok átkutatásával veszít el.
A munkaterületébe beépített intelligens AI-asszisztens megváltoztathatja ezt. Ismerje meg a ClickUp Brain-t! Azonnali betekintést és válaszokat nyújt, másodpercek alatt előkeresve a megfelelő dokumentumokat, beszélgetéseket és feladatokat – így nem kell tovább keresnie, hanem azonnal munkához láthat.
💫 Valós eredmények: A QubicaAMF-hez hasonló csapatok a ClickUp használatával hetente több mint 5 órát spóroltak meg – ez évente több mint 250 óra fejenként –, mivel megszüntették az elavult tudásmenedzsment-folyamatokat. Képzelje el, mit tudna létrehozni a csapata egy plusz hétnyi termelékenységgel minden negyedévben!
A legjobb gyakorlatok az adatminőség terén
Az inkonzisztens vagy ellentmondásos példák megzavarják a modellt, ami megbízhatatlan és kiszámíthatatlan eredményekhez vezet. Ennek elkerülése érdekében a képzési adatokat gondosan össze kell állítani és tisztítani kell. Egyetlen rossz példa is semmissé teheti a sok jó példából tanultakat.
Kövesse ezeket az irányelveket a magas adatminőség biztosítása érdekében:
- Következetesség: Minden példának ugyanazt a formátumot, stílust és hangnemet kell követnie. Ha azt szeretné, hogy az AI formális legyen, akkor minden kimeneti példának formálisnak kell lennie.
- Sokszínűség: Az adatkészletének le kell fednie a modell valós használat során valószínűleg előforduló összes bemeneti adatot. Ne csak az egyszerű eseteken képezze ki.
- Pontosság: Minden egyes kimeneti példának tökéletesnek kell lennie. Pontosan olyan válaszoknak kell lenniük, amilyeneket a modelltől elvár, hibáktól és elírásoktól mentesen.
- Tisztaság: A képzés előtt el kell távolítania az ismétlődő példákat, kijavítania az összes helyesírási és nyelvtani hibát, valamint megoldania az adatokban található ellentmondásokat.
Erősen ajánlott, hogy több ember is áttekintse és ellenőrizze a képzési példákat. Egy friss szem gyakran észreve olyan hibákat vagy következetlenségeket, amelyek Önnek esetleg elkerültek a figyelmét.
Hogyan hangolhatja finomra a Gemini-t lépésről lépésre
A Gemini finomhangolási folyamata több technikai lépést is magában foglal a Google platformjain. Egyetlen hibás beállítás is órákat vesz igénybe a értékes képzési időből és számítási erőforrásokból, és arra kényszeríti Önt, hogy elölről kezdje az egészet. Ez a gyakorlati útmutató arra szolgál, hogy csökkentse a próba-hiba folyamatot, és végigkísérje Önt a folyamaton az elejétől a végéig. 🛠️
Mielőtt elkezdené, szüksége lesz egy Google Cloud-fiókra, amelyen engedélyezve van a számlázás, és hozzáféréssel rendelkezik a Google AI Studio-hoz. Szánjon legalább néhány órát a kezdeti beállításra és az első képzési feladatra, valamint további időt a modell tesztelésére és iterálására.
1. lépés: Állítsa be a Google AI Studio-t
A Google AI Studio egy webes felület, ahol az egész finomhangolási folyamatot kezelheti. Ez egy felhasználóbarát módszert kínál az adatok feltöltésére, a képzés konfigurálására és az egyéni modell tesztelésére kódírás nélkül.
Először lépjen az ai.google.dev oldalra, és jelentkezzen be Google-fiókjával.
El kell fogadnia a szolgáltatási feltételeket, és létre kell hoznia egy új projektet a Google Cloud Console-ban, ha még nincs ilyenje. Győződjön meg arról, hogy engedélyezi a szükséges API-kat, ahogyan azt a platform kéri.
2. lépés: Töltse fel a képzési adatkészletét
A beállítás után lépjen a Google AI Studio hangolási szakaszába. Itt kezdheti el az egyéni modell létrehozásának folyamatát.
Válassza a „Beállított modell létrehozása” opciót, és válassza ki az alapmodellt. A Gemini 1. 5 Flash egy gyakori és költséghatékony választás a finomhangoláshoz.
Ezután töltse fel a JSONL vagy CSV fájlt, amely tartalmazza az előkészített képzési adatkészletet. A platform ezután ellenőrzi a fájlt, hogy megfelel-e a formázási követelményeknek, és jelzi az olyan gyakori hibákat, mint a hiányzó mezők vagy a nem megfelelő szerkezet.
3. lépés: Finomhangolási beállítások konfigurálása
Az adatok feltöltése és érvényesítése után konfigurálja a képzési paramétereket. Ezek a beállítások, az úgynevezett hiperparaméterek, szabályozzák, hogy a modell hogyan tanul az adatokból.
A legfontosabb opciók a következők:
- Epokok: Ez határozza meg, hogy a modell hányszor fogja betanítani az egész adatkészletet. Több epok jobb tanulást eredményezhet, de túlillesztés kockázatával is jár.
- Tanulási sebesség: Ez szabályozza, hogy a modell milyen agresszíven módosítja súlyait az Ön példái alapján.
- Batch size (Batch méret): Ez határozza meg, hogy hány képzési példát dolgoznak fel együtt egy csoportban.
Első próbálkozásként a legjobb, ha a Google AI Studio által ajánlott alapértelmezett beállításokkal kezdi. A platform leegyszerűsíti ezeket a komplex döntéseket, így azok akkor is elérhetőek, ha Ön nem gépi tanulás szakértő.
4. lépés: Futtassa a beállítási feladatot
A beállítások konfigurálása után elindíthatja a hangolási feladatot. A Google szerverei megkezdik az adatok feldolgozását és a modell paramétereinek beállítását. Ez a képzési folyamat néhány perctől több óráig is eltarthat, az adatkészlet méretétől és a kiválasztott modelltől függően.
A feladat előrehaladását közvetlenül a Google AI Studio irányítópultján követheti nyomon. Mivel a feladat a Google szerverein fut, nyugodtan bezárhatja a böngészőt, és később visszatérhet, hogy ellenőrizze az állapotát. Ha egy feladat sikertelen, az szinte mindig a képzési adatok minőségével vagy formázásával kapcsolatos probléma miatt történik.
5. lépés: Tesztelje az egyéni modellt
A képzés befejezése után az egyedi modell készen áll a tesztelésre. ✨
A Google AI Studio játszótér felületén keresztül érheti el.
Kezdje azzal, hogy olyan tesztparancsokat küld neki, amelyek hasonlóak a képzési példákhoz, hogy ellenőrizze a pontosságát. Ezután tesztelje szélsőséges eseteken és olyan új variációkon, amelyeket még nem látott, hogy értékelje általánosítási képességét.
- Pontosság: Pontosan azokat az eredményeket hozza-e, amelyekre betanította?
- Általánosítás: Helyesen kezeli-e az új bemeneteket, amelyek hasonlóak, de nem azonosak a képzési adataival?
- Következetesség: A válaszok megbízhatóak és előre jelezhetőek-e többszöri próbálkozás után is ugyanazzal a prompttal?
Ha az eredmények nem kielégítőek, valószínűleg vissza kell térnie, javítania kell a képzési adatokat további példák hozzáadásával vagy az inkonzisztenciák kijavításával, majd újra kell képeznie a modellt.
A Gemini egyéni adatokon történő betanításának bevált gyakorlata
A technikai lépések egyszerű követése nem garantálja a kiváló modellt. Sok csapat csak azért végzi el a folyamatot, hogy aztán csalódjon az eredményekben, mert nem alkalmazza azokat az optimalizálási stratégiákat, amelyeket a tapasztalt szakemberek használnak. Ez az, ami megkülönbözteti a funkcionális modellt a magas teljesítményű modelltől.
Nem meglepő, hogy a Deloitte „State of Generative AI in the Enterprise” jelentése szerint a vállalatok kétharmada jelenti, hogy generatív mesterséges intelligencia kísérleteik 30%-a vagy annál kevesebb fog teljes mértékben megvalósulni hat hónapon belül.
Ezeknek a bevált gyakorlatoknak az alkalmazásával időt takaríthat meg és sokkal jobb eredményeket érhet el.
- Kezdje kicsiben, majd bővítse: Mielőtt teljes képzési futtatásba kezdene, tesztelje meg a módszert az adatok egy kis részével (pl. 100 példával). Így ellenőrizheti az adatformátumot, és gyorsan képet kaphat a teljesítményről, anélkül, hogy órákat pazarolna.
- Adatállományok verzióinak kezelése: Amikor képzési példákat ad hozzá, eltávolít vagy szerkeszt, mentse el az adatállomány minden verzióját. Ez lehetővé teszi a változások nyomon követését, az eredmények reprodukálását és a korábbi verzióra való visszatérést, ha az új verzió rosszabb teljesítményt nyújt.
- Tesztelés előtte és utána: A finomhangolás megkezdése előtt állapítson meg egy alapvonalat azáltal, hogy értékeli az alapmodell teljesítményét a legfontosabb feladatokon. Ez lehetővé teszi, hogy objektíven mérje, mennyivel javult a finomhangolás eredményeként.
- Ismételje meg a hibákat: Ha az egyéni modellje helytelen vagy rosszul formázott választ ad, ne csüggedjen el. Adja hozzá ezt a konkrét hibaesetet új, javított példaként a képzési adataihoz a következő iterációhoz.
- Dokumentálja a folyamatot: vezessen naplót minden edzésről, jegyezze fel a használt adatkészlet verzióját, a hiperparamétereket és az eredményeket. Ez a dokumentáció felbecsülhetetlen értékű ahhoz, hogy megértsük, mi működik és mi nem működik az idő múlásával.
Ezeknek az iterációknak, adatkészlet-verzióknak és dokumentációnak a kezelése megbízható projektmenedzsmentet igényel. Ha ezt a munkát egy strukturált munkafolyamatokhoz tervezett platformon központosítja, megakadályozhatja, hogy a folyamat kaotikus legyen.
Gyakori kihívások a Gemini betanítása során
A csapatok gyakran jelentős időt és erőforrásokat fektetnek a finomhangolásba, csak hogy előre látható akadályokba ütközzenek, ami felesleges erőfeszítésekhez és frusztrációhoz vezet. Ha előre ismeri ezeket a gyakori buktatókat, az segíthet a folyamat zökkenőmentesebb lebonyolításában.
Íme néhány gyakori kihívás és azok megoldása:
- Túlillesztés: Ez akkor fordul elő, amikor a modell tökéletesen megjegyzi a képzési példákat, de nem képes általánosítani az új, még nem látott bemenetekre. A probléma megoldásához növelheti a képzési adatok sokszínűségét, fontolóra veheti az epochok számának csökkentését, vagy kipróbálhat alternatív módszereket, például a visszakereséssel kiegészített generálást.
- Inkonzisztens eredmények: Ha a modell nagyon hasonló kérdésekre eltérő válaszokat ad, az valószínűleg azért van, mert a képzési adatok ellentmondásos vagy inkonzisztens példákat tartalmaznak. Ezeknek az ellentmondásoknak a megoldásához alapos adat tisztításra van szükség.
- Formátumeltérés: Előfordulhat, hogy egy modell kezdetben a kívánt kimeneti struktúrát követi, de idővel eltér attól. A megoldás az, hogy a képzési példák kimenetébe nem csak a tartalmat, hanem kifejezett formátumra vonatkozó utasításokat is belefoglal.
- Lassú iterációs ciklusok: Ha minden edzés futtatása órákig tart, az jelentősen lassítja a kísérletezési és fejlesztési képességét. Először kisebb adatkészleteken tesztelje ötleteit, hogy gyorsabb visszajelzést kapjon, mielőtt elindítaná a teljes edzésmunkát.
- Adatgyűjtési szűk keresztmetszet: Gyakran a legnehezebb rész az adatgyűjtés szűk keresztmetszete, vagyis egyszerűen elegendő mennyiségű, jó minőségű példa összegyűjtése. Kezdje a már meglévő legjobb tartalmak – például ügyfélszolgálati jegyek, marketing szövegek vagy műszaki dokumentumok – felhasználásával, és onnan induljon tovább.
Ezek a kihívások az egyik fő oka annak, hogy sok csapat végül alternatívákat keres a manuális finomhangolási folyamatra.
📮ClickUp Insight: A felmérésünkben résztvevők 88%-a használja az AI-t személyes feladatokhoz, de több mint 50%-uk nem meri használni a munkában. A három fő akadály? A zökkenőmentes integráció hiánya, a tudáshiány vagy a biztonsági aggályok. De mi lenne, ha az AI beépülne a munkaterületébe, és már eleve biztonságos lenne? A ClickUp Brain, a ClickUp beépített AI asszisztense ezt valósággá teszi. Megérti a közönséges nyelven megfogalmazott utasításokat, megoldva mindhárom AI-bevezetési aggályt, miközben összekapcsolja a csevegést, a feladatokat, a dokumentumokat és a tudást a munkaterületen. Találjon válaszokat és betekintést egyetlen kattintással!
Miért a ClickUp a legokosabb alternatíva?
A Gemini finomhangolása hatékony, de egyben átmeneti megoldás is.
Ebben a cikkben láthattuk, hogy a finomhangolás végső soron egy dologról szól: megtanítani az AI-t arra, hogy megértse az Ön üzleti környezetét. A probléma az, hogy a finomhangolás ezt közvetett módon teszi. Ön adatokat készít elő, példákat tervez, modelleket újratanít és folyamatokat tart karban, mindezt azért, hogy az AI megközelítőleg megértse, hogyan működik a csapata.
Ez speciális felhasználási esetekben értelmes. De a legtöbb csapat számára a valódi cél nem a Gemini személyre szabása önmagáért. A cél egyszerűbb:
Olyan mesterséges intelligenciát szeretne, amely megérti a munkáját.
Itt jön be a ClickUp alapvetően más – és okosabb – megközelítése.
A ClickUp Converged AI Workspace egy olyan mesterséges intelligenciát biztosít a csapatának, amely azonnal megérti a munkakörnyezetét – nincs szükség nagy erőfeszítésekre. Ahelyett, hogy a mesterséges intelligenciát később megtanítaná a munkakörnyezetére, a ClickUp Brain integrált mesterséges intelligencia asszisztenssel dolgozhat, amely már eleve ismeri a munkakörnyezetét.
Feladatai, dokumentumai, megjegyzései, projektjeinek története és döntései natívan kapcsolódnak egymáshoz. Nincs szükség az AI-t az Ön adatai alapján betanítani, mert az már ott van, ahol Ön dolgozik, és kihasználja a meglévő tudásmenedzsment-ökosziszt émáját.
| Aspektus | Gemini finomhangolás | ClickUp Brain |
|---|---|---|
| Beállítási idő | Napokig vagy hetekig tartó adatelőkészítés | Azonnali – a meglévő munkaterületi adatokkal működik |
| Kontextus forrása | Kézzel válogatott képzési példák | Automatikus hozzáférés az összes csatlakoztatott munkához |
| Karbantartás | Ha az igényei megváltoznak, végezzen újratréninget. | Folyamatosan frissül, ahogy munkaterülete fejlődik. |
| Szükséges technikai ismeretek | Közepes-magas | Nincs |
Mivel a ClickUp az Ön munkarendszere, a ClickUp Brain az Ön összekapcsolt adatgrafikonján belül működik. Nincs AI-terjedés a nem összekapcsolt eszközök között, nincsenek törékeny képzési folyamatok, és nincs kockázata annak, hogy a modell nem lesz szinkronban a csapata tényleges munkamódszerével.
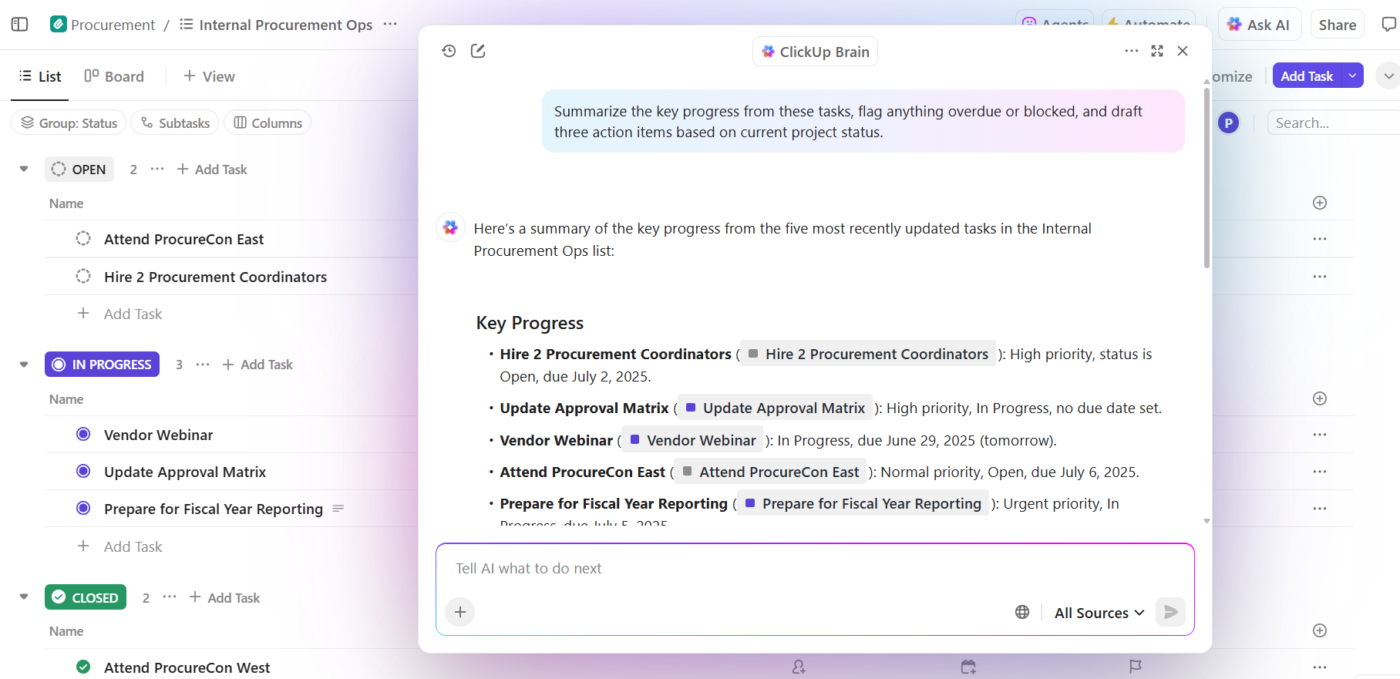
Így néz ez ki a gyakorlatban:
- Kérdéseket tehet fel a projektjeivel kapcsolatban: a ClickUp Brain a feladatok, dokumentumok, megjegyzések és frissítések között keres a munkaterületen, hogy a valódi projektadatok alapján válaszoljon a kérdésekre – nem általános képzési ismeretek alapján.
- Kontextusos tartalom generálása: A ClickUp Brain már biztonságos hozzáféréssel rendelkezik a feladatokhoz, fájlokhoz, megjegyzésekhez és a projekt előzményeihez. Dokumentumokat, összefoglalókat és állapotfrissítéseket hozhat létre, amelyek hivatkoznak a tényleges munkájára, ütemterveire és prioritásaira. Nincs többé kontextus-szétszóródás, ahol a csapatok órákat pazarolnak az alkalmazásokban és fájlokban való információkeresésre.
- Automatizálás megértéssel: A ClickUp Automations segítségével olyan automatizálást hozhat létre, amely intelligensen reagál a projekt kontextusára, például a határidőkre, a tulajdonjogra és az állapotváltozásokra, és nem csak statikus szabályokra. Az AI akár ezeket is elkészítheti Önnek, kód írása nélkül.
💡Profi tipp: Használja ki az AI valódi erejét a munkaterületén a ClickUp Super Agents segítségével.
A Super Agents a ClickUp mesterséges intelligenciával működő csapattársai, amelyek mesterséges intelligencia „felhasználókként” vannak konfigurálva, és a munkaterületen belül a csapatával együtt dolgoznak. Környezetfüggőek és kontextusfüggőek, és feladatokhoz rendelhetők, megjegyzésekben említhetők, események vagy ütemezés alapján aktiválhatók, vagy csevegésen keresztül irányíthatók – akárcsak egy emberi csapattárs.
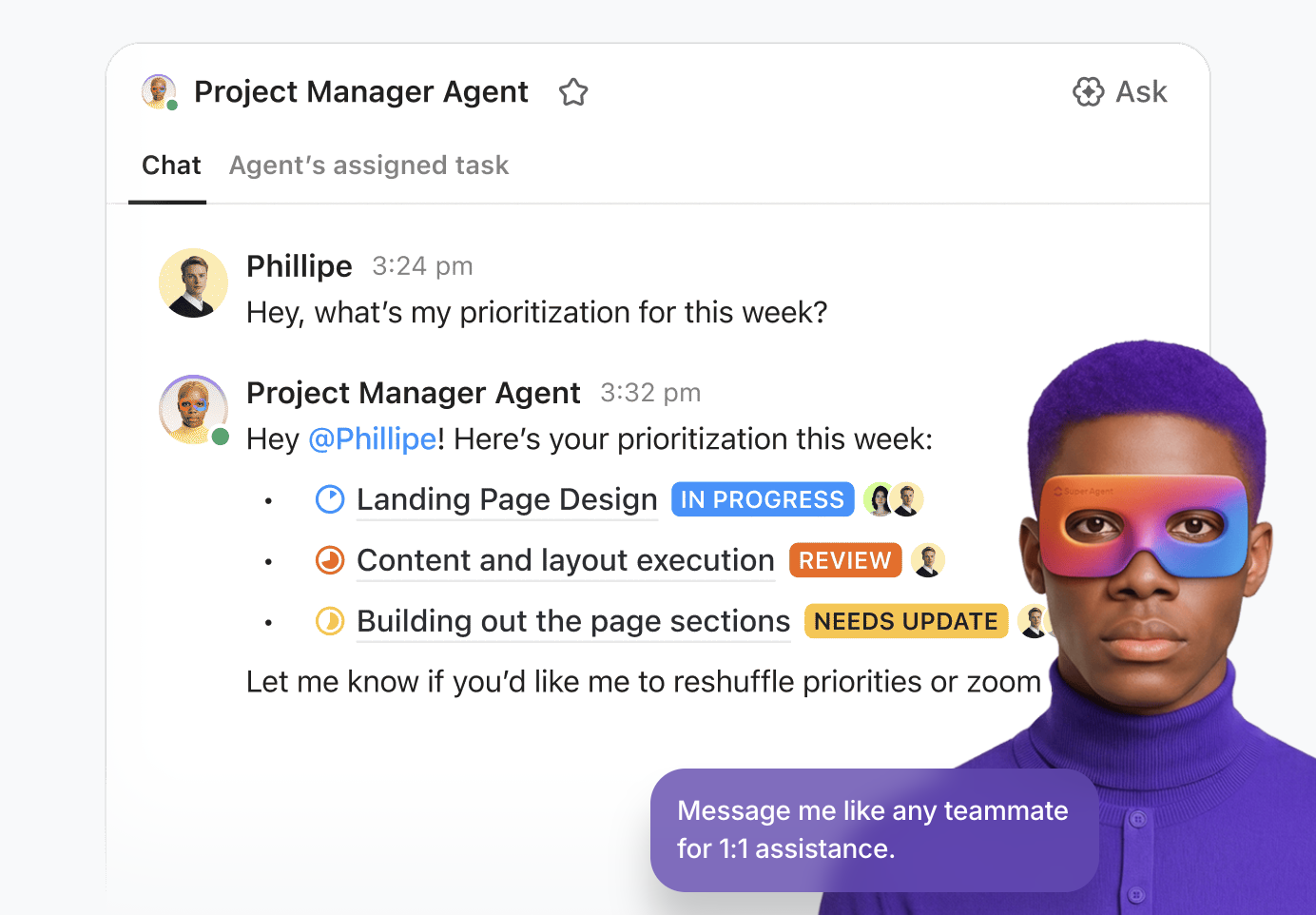
A modelleket a kódolás nélküli vizuális építő segítségével hozhatja létre és telepítheti, amely lehetővé teszi a következőket:
- Határozza meg a kiindulási eseményt, például egy üzenetet vagy a feladat állapotának változását.
- Vázolja fel az operatív szabályokat, beleértve az adatok összefoglalásának, a munkák delegálásának vagy a prioritások módosításának módját.
- Végezzen külső műveleteket integrált eszközök és kiterjesztések segítségével.
- Adjon meg támogató adatokat az ügynököt a releváns tudásbázisokhoz csatlakoztatva.
Az alábbi videóban többet megtudhat a szuperügynökökről.
Finomítsa AI-stratégiáját: szerezze be a ClickUp-ot
A finomhangolás statikus példákon keresztül tanítja meg az AI-nek a mintáit, de a ClickUp-hoz hasonló munkaterületen konvergált szoftver használata kiküszöböli a kontextus szétaprózódását, mivel az AI-nek élő, automatikus kontextust biztosít.
Ez a sikeres AI-átalakulás lényege: azok a csapatok, amelyek munkájukat egy összekapcsolt platformon központosítják, kevesebb időt töltenek az AI betanításával, és több időt fordíthatnak annak előnyeinek kihasználására. A munkaterület fejlődésével az AI is automatikusan fejlődik – nincs szükség újratanítási ciklusokra.
Készen áll arra, hogy kihagyja a képzést, és azonnal elkezdje használni a már az Ön munkáját ismerő mesterséges intelligenciát? Kezdje el ingyenesen a ClickUp használatát, és tapasztalja meg a konvergált munkaterület előnyeit.
Gyakran ismételt kérdések (GYIK)
A finomhangolt modell a képzési példákból tanul, de a Google alap Gemini modellje alapértelmezés szerint nem tárolja és nem tanul a beszélgetési adataiból. Az egyéni modell elkülönül a többi felhasználót kiszolgáló alapmodelltől.
Míg a képzés maga csak néhány órát vesz igénybe, a nagyobb időbefektetés a kiváló minőségű képzési adatok előkészítésével jár. Ez az adatelőkészítési fázis gyakran napokig, sőt hetekig is eltarthat, ha megfelelően szeretné elvégezni.
Igen, a Google AI Studio segítségével kód írása nélkül is finomhangolhatja a modellt. A program vizuális felületet biztosít, amely kezeli a technikai komplexitás nagy részét, de Önnek még mindig meg kell értenie az adatok formázási követelményeit.
Az egyéni utasítások ideiglenes, munkamenet-alapú utasítások, amelyek egy adott beszélgetés során irányítják a modell viselkedését. A finomhangolás azonban a képzési példák alapján véglegesen módosítja a modell belső paramétereit, tartós változásokat hozva létre a viselkedésében.