

Ön egy osztályvezető, aki a tökéletes embert keresi egy adott feladat elvégzésére. A hatalmas vállalati adatbázisban szinte lehetetlen megtalálni a legalkalmasabb jelöltet, különösen, ha a feladat időérzékeny.
Ráadásul, kinek van ideje megkérdezni mindenkitől, hogy rendelkezik-e elegendő ismerettel egy adott területen?
De mi lenne, ha egyszerűen megkérdezhetné a rendszert: „Kinek osztották ki a legtöbb [feladatot]?”, és valós adatok alapján azonnali, pontos választ kapna? Ez az, amit az információkereső rendszerek tesznek.
Ezek a rendszerek hatalmas adatmennyiségeket vizsgálnak át, hogy pontosan megtalálják, amire szüksége van.
Most pedig terjessze ki ezt az elképzelést egy globális adatbázisra: egy IR-rendszer hatalmas mennyiségű adatot szervez, segítve Önt abban, hogy másodpercek alatt megtalálja a legrelevánsabb válaszokat. Ez az útmutató különböző információkeresési modelleket, azok működését és az AI-technológiák szerepét vizsgálja egy IR-rendszerben.
⏰ 60 másodperces összefoglaló
📌 Az információkereső (IR) rendszerek segítenek megtalálni a releváns információkat nagy adatgyűjteményekből, úgy működnek, mint egy virtuális asszisztens, aki átnézi az adatokat, hogy megtalálja, amire szüksége van.
📌 Az IR-rendszereknek kulcsfontosságú elemei vannak: adatbázis, indexelő, keresőfelület, lekérdezési processzor, visszakeresési modellek és rangsorolási/pontozási mechanizmusok.
📌 Négy fő IR-modell használatos: Boole-modell (AND/OR/NOT operátorokat használ), vektorterület-modell (a dokumentumokat vektorokként ábrázolja), valószínűségi modell (statisztikai megközelítéseket használ) és kifejezésfüggőségi modell (a kifejezések közötti kapcsolatokat elemzi).
📌 A gépi tanulás és a természetes nyelvfeldolgozás javítja az IR-rendszereket a minták felismerésének, az eredmények rangsorolásának és a kontextus megértésének fejlesztésével.
📌 A főbb kihívások közé tartozik az adatvédelem, a skálázhatóság és az adatok minőségének fenntartása nagy adathalmazok feldolgozása közben.
Mi az információkeresés (IR)?
Az információkeresés (IR) egyszerűen azt jelenti, hogy megtalálja a megfelelő információt nagy adatgyűjteményekből, például digitális könyvtárakból, adatbázisokból vagy internetes archívumokból.
Olyan, mintha egy virtuális asszisztens lenne, aki átnézi a hatalmas adatmennyiséget, hogy pontosan azt hozza el Önnek, amire szüksége van.
A felhasználó a felületen, gyakran kulcsszavak vagy kifejezések segítségével, lekérdezést ad meg, hogy konkrét információt keressen. A háttérben fejlett technikák és algoritmusok elemzik a keresési karakterláncokat, és összevetik azokat a releváns adatokkal.
Az IR-rendszerek nem csak egyetlen választ adnak meg, hanem több objektumot is, amelyek mindegyike különböző mértékben releváns a keresési lekérdezéshez. Ráadásul mindenhol használják őket, és többféle alkalmazásuk is van (erről hamarosan bővebben 🔔).
💡Profi tipp: Meg kell találnia a legalkalmasabb személyt egy feladat elvégzésére? Írjon be konkrét kifejezéseket, például „értékesítési jelentés elemzése Q1 és Q2 feladatok hozzárendelése” az információkereső rendszerbe. Ezzel gyorsan kiszűri az irreleváns adatokat, és meghatározza, ki kezelte azokat a leggyakrabban.
Az IR alkalmazásai különböző területeken
Az egészségügytől az e-kereskedelemig, az IR-rendszereket számos területen használják az adatok kezelésére és kategorizálására. Íme néhány példa 👇
Egészségügy
Az egészségügyben az IR-rendszerek átvizsgálják az orvosi nyilvántartások és kutatási cikkek adatbázisait, hogy segítsék az orvosokat és a kutatókat a legrelevánsabb információk megtalálásában. Ennek eredményeként felgyorsítják a betegségek diagnosztizálását, azonosítják a kezelési lehetőségeket, és releváns visszajelzések segítségével megtalálják a legrelevánsabb tanulmányokat.
Ügyfélszolgálat
Az információkeresési technikák gyorsabbá és pontosabbá teszik az ügyfélszolgálatot. Az ügyintézők például beírhatják a felhasználói lekérdezéseket, például „visszatérítési szabályzat”, a vállalat rendszerébe, hogy azonnali válaszokat kapjanak.
Az információkeresésen alapuló AI chatbotok és ügyfélszolgálatok még egy lépéssel tovább mennek, valós idejű megoldásokat kínálnak emberi beavatkozás nélkül. Ezért kapja meg kérdéseire gyakran másodpercek alatt választ!
E-kereskedelmi platformok
Az IR-rendszerek megkönnyítik az online vásárlást. Elemezik az adatbázisokat és összevetik a vásárlói viselkedést, hogy olyan termékeket ajánljanak , amelyek tetszeni fognak Önnek.
Az Amazon például az IR-t használja arra, hogy a keresési előzmények és a korábbi vásárlások alapján termékeket javasoljon, így segítve Önt abban, hogy pontosan azt találja meg, amire szüksége van.
Az információkereső rendszer összetevői
Most már tudjuk, mi az információkeresés és hogyan működik. Nézzük meg az IR-rendszer legfontosabb építőelemeit! →
1. Adatbázis
Minden az adatbázissal kezdődik. Ez egy egymással összefüggő adatpontok gyűjteménye, például szöveges dokumentumok, e-mailek, weboldalak, képek és videók. Amikor megad egy lekérdezést, az IR-rendszer átkutatja ezeket az adatbázis-találatokat, hogy a legrelevánsabb információkat keresse ki az Ön igényeinek megfelelően.
2. Indexelő
Mielőtt a rendszer bármit is visszakereshetne, az indexelő rendszerezi az adatokat. Ez olyan, mint egy könyvtári katalógus elkészítése a gyorsabb keresés érdekében. Az indexelő a következőképpen dolgozza fel a dokumentumokat:
- Tokenizálás: A tartalom kisebb részekre bontása, például a mondatok szavakra vagy kifejezésekre (tokenek) való felbontása.
- Szótőkezelés: A szavak egyszerűsítése alapformájukra (pl. a „running” szó „run”-ná válik).
- Stop word removal (stop szó eltávolítás): Az olyan töltelékszavak kihagyása, mint „és”, „vagy” és „a”, hogy a fő keresési kifejezésre összpontosítson.
- Kulcsszó-kivonás: A szöveg fő kulcsszavainak azonosítása
- Metadatok kivonása: További részletek, például a szerző, a közzététel dátuma vagy a cím lekérése.
3. Keresési felület
A keresőfelület az IR-rendszer kapujaként működik. Itt írhatja be keresési lekérdezését egyszerű kulcsszavak vagy részletesebb szűrők segítségével. A felhasználóbarát kialakításnak köszönhetően könnyedén közölheti információhoz való hozzáférési igényeit, és megkapja a keresett releváns eredményeket.
4. Lekérdezésfeldolgozó
Miután rákattintott a „keresés” gombra, a lekérdezési processzor átveszi az irányítást. Az indexelő részben felsorolt technikák alkalmazásával finomítja a bevitt adatokat. Ezenkívül booli operátorokat is kezel, mint például „AND”, „OR” és „NOT”, hogy a lekérdezése okosabb legyen.
5. Keresési modellek
Itt történik a varázslat. A rendszer a keresési modellek segítségével összehasonlítja az Ön által megadott lekérdezést az indexelt dokumentumokkal. Ezek a módszerek határozzák meg, hogy a lekérdezés hogyan illeszkedik a tárolt adatokhoz. Néhány gyakori név:
- Booles modellek
- Vektortér modellek
- Valószínűségi modellek
- És még sok más... (később tárgyaljuk)
6. Rangsorolás és pontozás
Miután megtalálta a potenciális találatokat, a rendszer relevancia alapján rangsorolja azokat. Minden dokumentum pontszámot kap olyan módszerekkel, mint a TF-IDF (Term Frequency-Inverse Document Frequency) vagy más algoritmusok. Ez biztosítja, hogy a legrelevánsabb eredmények jelenjenek meg az első helyen.
7. Prezentáció vagy megjelenítés
Végül az eredmények megjelennek Önnek. Általában a rendszer rangsorolt listát jelenít meg a szöveges dokumentumokról, olyan extra funkciókkal, mint kivonatok, szűrők vagy rendezési opciók. Ez megkönnyíti a legrelevánsabb dokumentum kiválasztását. Azonban a megjelenített eredmények száma változhat az Ön preferenciái, lekérdezése vagy a rendszer beállításai alapján.
🔍Tudta?: A hagyományos információkereső rendszerek nagymértékben támaszkodtak strukturált adatbázisokra és alapvető kulcsszó-egyeztetésre. Az eredmény? Jelentős relevancia- és személyre szabási problémák.
Ekkor a modern AI technológiák átalakították a szövegkeresést a következők révén:
- Gépes tanulás (ML): Segít az IR-rendszereknek a felhasználói viselkedés mintáiból tanulni és idővel javítani a keresési eredményeket.
- Mély neurális hálózatok: Olyan algoritmusok, amelyek képesek feldolgozni a strukturálatlan adatokat (például képeket vagy videókat) és feltárni a komplex kapcsolatokat.
- Természetes nyelvfeldolgozás (NLP): Lehetővé teszi a rendszerek számára a lekérdezések jelentésének és kontextusának megértését a képfelismerés és az érzelemelemzés támogatása érdekében, így az információhoz való hozzáférés sokoldalúbbá válik.
Információkeresési modellek
Különböző IR-rendszerek léteznek, amelyek egyszerűsítik a releváns dokumentumok keresésének folyamatát. Nézzük meg a legszélesebb körben használtakat:
1. Halmazelmélet és boole-i modellek
A Boole-modell az egyik legegyszerűbb információkeresési technika. Így működik:
- ÉS: Azok a dokumentumok kerülnek előkerítésre, amelyek az összes keresési kifejezést tartalmazzák. Például a „macska ÉS kutya” keresésre a keresőmotor mindkét kifejezést tartalmazó dokumentumokat ad vissza.
- VAGY: Megtalálja azokat a dokumentumokat, amelyek bármelyik kifejezést tartalmaznak a lekérdezésben. A „macska VAGY kutya” kifejezésre olyan dokumentumokat talál, amelyek vagy macskát, vagy kutyát, vagy mindkettőt említik.
- NOT: Kizárja az adott kifejezést tartalmazó dokumentumokat. Például a „cat AND NOT dog” kifejezésre a macskát említő, de kutyát nem említő dokumentumok jelennek meg.
Ez a modell a „szavak táskája” koncepciót alkalmazza, amelyben egy 2D mátrix jön létre. Ebben a mátrixban:
- Az oszlopok dokumentumokat jelölnek.
- A sorok a lekérdezésben szereplő kifejezéseket jelölik.
Minden cellához 1 (ha a kifejezés szerepel) vagy 0 (ha nem szerepel) érték van rendelve.

✅ Előnyök
- Könnyen érthető és megvalósítható
- Pontosan a keresési feltételeknek megfelelő dokumentumokat talál meg.
❌ Hátrányok
- A boole-i modellek nem rangsorolják a dokumentumokat relevancia szerint, így minden eredmény egyformán fontosnak tekinthető.
- A pontos kifejezésmegfelelésekre összpontosít, ezért az eredmények a lekérdezés jelentése vagy kontextusa szerint eltérhetnek.
2. Vektorterületi modellek
A vektortér-modell egy algebrai modell, amely a dokumentumokat és a lekérdezéseket egy többdimenziós térben vektorokként ábrázolja. Így működik:
1. Létrehozunk egy kifejezés-dokumentum mátrixot, amelynek sorai a kifejezéseket, oszlopai pedig a dokumentumokat tartalmazzák.
2. A lekérdezési vektor a felhasználó keresési kifejezései alapján alakul ki.
3. A rendszer egy numerikus pontszámot számol ki egy koszinusz-hasonlóság nevű mérőszám segítségével, amely meghatározza, hogy a lekérdezési vektor mennyire hasonlít a dokumentumvektorokhoz.

Információkereső rendszerként a dokumentumokat ezeknek a pontszámoknak megfelelően rangsorolják, a legmagasabb pontszámmal rendelkező dokumentumok a legrelevánsabbak.
✅ Előnyök
- Az elemeket akkor is visszakeresi, ha csak néhány kifejezés egyezik
- A kifejezések használatának és a dokumentumok hosszának változatossága, a különböző dokumentumtípusok figyelembevétele
❌ Hátrányok
- A nagyobb szókincsek és dokumentumgyűjtemények miatt a hasonlóságok kiszámítása erőforrás-igényes.
3. Valószínűségi modellek
Ez a modell statisztikai megközelítést alkalmaz, valószínűségeket használva annak becslésére, hogy egy dokumentum mennyire releváns a lekérdezéshez. A következőket veszi figyelembe:
- A kifejezések gyakorisága a dokumentumban
- Milyen gyakran fordulnak elő a kifejezések együtt (együttes előfordulás)
- A dokumentum hossza és a lekérdezési kifejezések teljes száma
A rendszer a visszakeresési folyamatot valószínűségi eseményként kezeli, és a dokumentumokat relevanciájuk valószínűsége alapján rangsorolja. Ez a megközelítés mélyebb értelmet ad az adatoknak, mivel nem csak az alapvető kifejezések jelenlétét értékeli.
✅ Előnyök
- Jól alkalmazkodik különböző alkalmazásokhoz, beleértve a megbízhatósági elemzéseket és a terhelésáramlás-értékeléseket.
❌ Hátrányok
- Adatkapcsolatokra vonatkozó feltételezéseken alapul, ami félrevezető eredményekhez vezethet.
4. Kifejezések egymástól való függőségének modelljei
Az egyszerűbb modellektől eltérően a szavak egymástól való függőségét modellező modellek a szavak gyakorisága helyett azok közötti kapcsolatokra koncentrálnak. Ezek a modellek elemzik, hogy a szavak és kifejezések hogyan kapcsolódnak egymáshoz, hogy javítsák az eredmények pontosságát.
Kétféle megközelítést alkalmaznak:
- Immanens mód: A szövegben lévő kapcsolatok feltárása
- Transzcendens mód: külső adatokat vagy kontextust vesz figyelembe a kapcsolatok következtetéséhez.
Ez a módszer különösen hasznos a jelentésbeli árnyalatok, például a szinonimák vagy a kontextus-specifikus kifejezések megragadásához.
✅ Előnyök
- A kifejezések közötti kapcsolatok figyelembevételével megragadja a nyelv finom árnyalatait.
- Javítja a visszakeresési teljesítményt a kifejezések függőségének és kontextusának megértésével.
❌ Hátrányok
- A kifejezések közötti kapcsolatok pontos modellezéséhez nagy mennyiségű adat szükséges, amely nem mindig áll rendelkezésre.
Ennyi! Ezek a leggyakrabban használt információkereső rendszerek, mindegyiknek megvannak a maga előnyei és hátrányai.
➡️ További információk: 4 Spotlight Search alternatíva és versenytárs
Információkeresés vs. adatlekérdezés
Bár ezek a kifejezések szinte azonosnak tűnnek, működésük eltérő. Tehát, állítsuk egymás mellé az IR-t és az adatlekérdezést, hogy megnézzük, hogyan viszonyulnak egymáshoz céljuk, felhasználási eseteik és példáik tekintetében:
| Aspect | Információkeresés (IR) | Adatlekérdezés |
| Meghatározás | Úgy működik, mint egy keresőmotor, amely rengeteg adatot átkutat, hogy a legrelevánsabb eredményeket hozza Önnek. | Képzelje el úgy, mintha egy adatbázisnak egy konkrét kérdést tenné fel egy olyan nyelven, amelyet az megért (például SQL). |
| Cél/célkitűzés | Segít megtalálni a pontos és releváns információkat vagy forrásokat a keresőmotorokban – gyorsan és egyszerűen. | Pontos adatokat gyűjt, hogy elemezze, frissítse vagy feldolgozza a számokat. |
| Használati példák | Webes keresésekhez, e-kereskedelmi ajánlásokhoz, digitális könyvtárakhoz, egészségügyi betekintéshez és még sok máshoz használható. | Kiválóan alkalmas olyan feladatokhoz, mint az e-kereskedelemben a készletek kezelése, a pénzügyek elemzése és az ellátási láncok optimalizálása. |
| Példa | Keressen rá a Google -on a „Legjobb laptopok 800 és 1000 dollár között” kifejezésre, hogy rangsorolt eredményeket kapjon. | Kérdezze le a raktárrendszerét a „SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000” lekérdezéssel, hogy megtudja, mi van raktáron. |
A gépi tanulás és az NLP szerepe az információkeresésben
Az IR-rendszerek olyanok, mint az adatok kincskeresői: hatalmas mennyiségű információt átvizsgálnak, hogy pontosan megtalálják, amit keres. De amikor az ML és az NLP összefog, ezek a rendszerek okosabbá, gyorsabbá és sokkal pontosabbá válnak.
Gondoljon az ML-re úgy, mint az IR-rendszerek agyára. 🧠
Segít a rendszernek tanulni, alkalmazkodni és javítani az eredményeket, amikor információt keres. Így működik:
- Minták felismerése: Az ML tanulmányozza, hogy a felhasználók mire kattintanak, mit hagyják figyelmen kívül, és mire fordítják a legtöbb időt olvasás közben. Ezután ezt az ismeretet felhasználva a legrelevánsabb eredményeket jeleníti meg legközelebb.
- Eredmények rangsorolása: Az ML visszakeresi az információkat, és rangsorolja is azokat. Ez azt jelenti, hogy a legjobb és leghasznosabb eredmények jelennek meg a keresés tetején.
- Az idővel való alkalmazkodás: Minden lekérdezéssel az ML egyre jobb lesz. Felismeri a trendeket, finomítja megértését, és még a legbonyolultabb kérdéseket is könnyedén kezeli.
Például, ha ma a „legjobb olcsó laptopok” kifejezésre keres, és konkrét eredményekkel lép kapcsolatba, a gépi tanulás (ML) tudni fogja, hogy később, amikor „megfizethető notebookok” kifejezésre keres, hasonló lehetőségeket kell előtérbe helyeznie. Az AI és az ML kombinálásával a webes keresőmotorok akár azt is megjósolhatják, mire lehet szüksége legközelebb.
Most beszéljünk az NLP-ről. Ez segít az IR-rendszereknek megérteni, hogy mit is jelent az, amit írsz, és nem csak a szavakat, amelyeket beírtál. Egyszerűen fogalmazva:
- Megérti a kontextust: az NLP tudja, hogy amikor azt mondja, hogy „jaguár”, akkor az állatra vagy az autóra utalhat – és ezt a többi keresési kifejezés alapján állapítja meg.
- Komplex nyelvet kezel: Akár egyszerű (pl. „olcsó járatok”) vagy részletes (pl. „500 dollár alatti közvetlen járatok Tokióba”) a keresési lekérdezése, az NLP biztosítja, hogy a rendszer megértse és a megfelelő eredményeket adja vissza.
Az NLP és az IR együttesen intuitívvá teszik a keresést, mintha valakivel beszélgetne, aki egyszerűen megérti Önt. Ez kevesebb görgetést, kevesebb frusztrációt és több „wow, pont erre volt szükségem!” pillanatot jelent.
A ClickUp szerepe az információkeresésben
A ClickUp, a „mindenre kiterjedő munkaalkalmazás” IR-modellekkel javítja az adatkezelést.
Beépített mesterséges intelligenciája egyedülálló módon azonosítja és illeszti az eredményeket a felhasználó keresési lekérdezéséhez, ezzel új szintre emelve az intelligens technológiát.
És hogy még vonzóbbá tegyük az ajánlatot, a ClickUp Connected Search funkciójával minden szükséges információ „azonnal” a keze ügyében lesz. Ez azt jelenti, hogy:
- Bármit kereshet: Ki szereti az e-mailek és tudáskezelő rendszerek között turkálni a fontos fájlok után? A Connected Search opcióval másodpercek alatt megtalálhat bármilyen fájlt. Sőt, a csatlakoztatott alkalmazásokban is kereshet fájlokat, és mindent egy helyen elérhet.
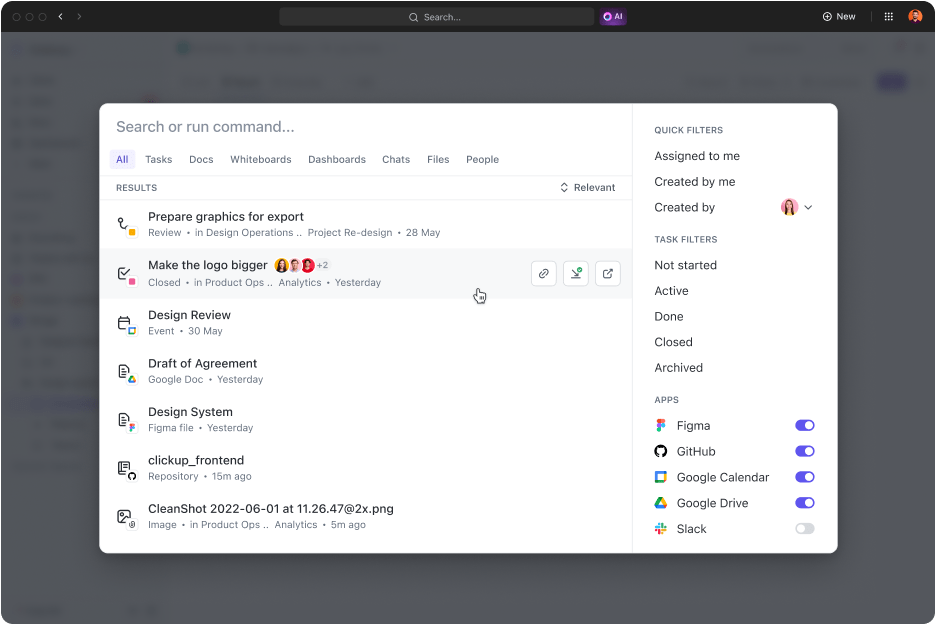
- Csatlakoztassa kedvenc alkalmazásait: A ClickUp néhány a legjobb integrációval rendelkezik, amelyek kiterjesztik keresési képességeit olyan harmadik féltől származó alkalmazásokra, mint a Google Drive, a Slack, a Dropbox, a Figma és még sok más.

- Finomítsa az eredményeket: Minél többet használja, annál jobban megérti, mit keres, és annál jobban személyre szabott eredményeket kap.
- Keresés a saját módján: Hozzáférés a Connected Searchhez és gyors PDF-fájlkeresés a munkaterület bármely pontjáról. Például elindíthat egy keresést a Command Centerből, a Global Action Barból vagy az asztalról.
- Egyéni keresési parancsok létrehozása: Adjon hozzá egyéni keresési parancsokat, például linkekhez való gyorsbillentyűket, szövegek későbbi tárolását és egyebeket, hogy egyszerűsítse a munkafolyamatot.
Ráadásul mi lenne, ha létezne egy módszer, amellyel automatizálhatná az unalmas feladatokat, gyorsabban dolgozhatna és többet tudna elvégezni rövid idő alatt?
A ClickUp Brain, a beépített AI asszisztens, ezt valósággá teszi az Ön számára. Ez a végső asszisztens az adatkezeléshez – intelligens, gyors és mindig készen áll a segítségre.
Röviden 👇
- All-in-one tudásközpont: Soha többé ne támaszkodjon e-mailekre és üzenetekre a frissítésekért. Kérdezzen bármit a feladatairól, dokumentumairól vagy embereiről, és dőljön hátra, míg a ClickUp Brain a kontextus alapján és a kapcsolódó alkalmazásokból kiindulva megtervezi a válaszokat.

- Gyorsabban megtalálja, amire szüksége van: A ClickUp Brain intelligensen rangsorolja az eredményeket, mint egy fejlett IR-rendszer. Prioritást ad a releváns fájloknak, javaslatokat tesz a kapcsolódó feladatokra, és még a rejtett munkaterhelések felfedezésében is segít az adatok között.
- Feladatok automatizálása: A Brain AI-eszközei automatizálják a jelentések készítését és a határidők nyomon követését. Ez egy személyi asszisztens, amely időt szabadít fel a fontosabb döntések meghozatalához, miközben mindent a helyes úton tart.
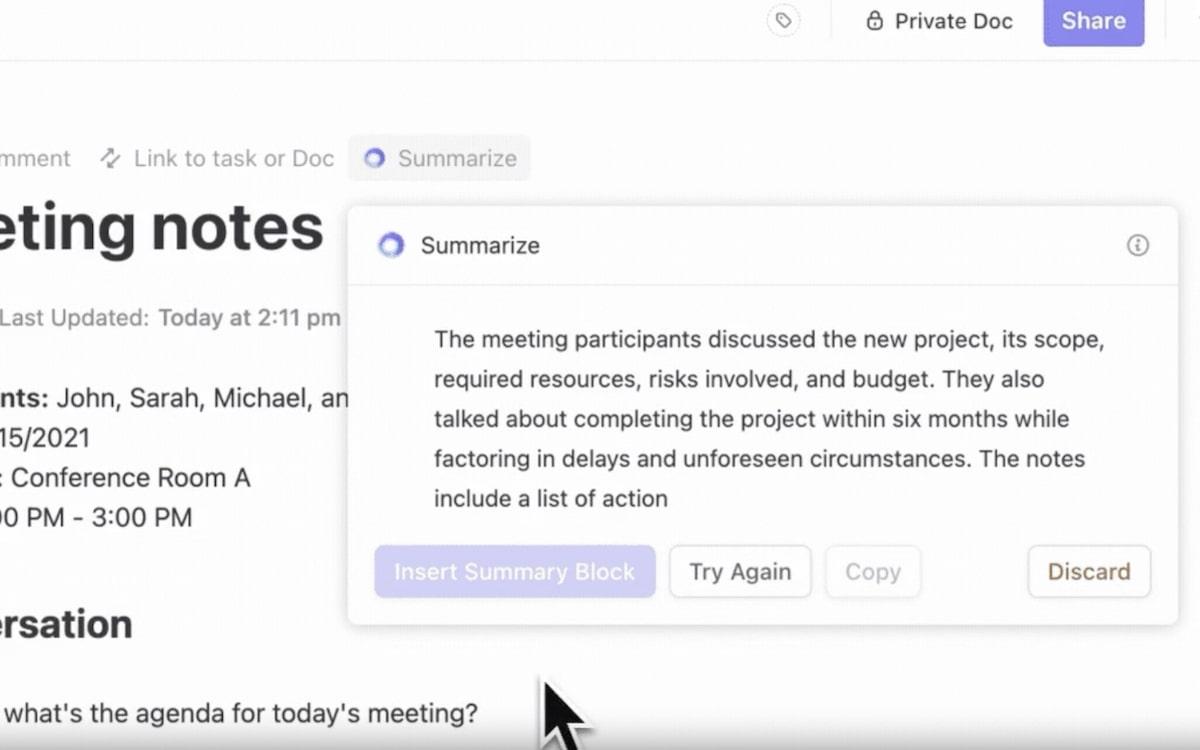
- Kontextusérzékeny keresés: Az NLP segítségével megérti a kérdését, még akkor is, ha az összetett vagy homályos. Például a „jelentés az első negyedévi értékesítésről” keresés pontosan azt a jelentést adja vissza, amely a feladatához kapcsolódik.
➡️ További információk: Mi az a munkamenedzsment-rendszer és hogyan lehet azt bevezetni?
Az információkeresés kihívásai és jövőbeli irányai
Az információkeresés világa arról szól, hogy értelmet nyerjenek a hatalmas adatmennyiségek, de még a legfejlettebb IR-rendszerek is szembesülnek néhány akadályokkal.
Fedezzük fel a közös kihívásokat és az izgalmas trendeket, amelyek alakítják ennek az alapvető tudományos diszciplínának a jövőjét:
- Adatvédelem és biztonság: Ahhoz, hogy egy IR-modell tényeken alapuló eredményeket nyújtson, gyakran érzékeny adatokhoz kell hozzáférnie. A felhasználói adatok védelme azonban nem egyszerű feladat az információkeresési források számára.
- Skálázhatóság és teljesítmény: Amikor a felhasználók nagy adatállományokban keresnek, a növekvő tartalomgyűjtemény kezelése még a legerősebb visszakeresési modelleket is túlterhelheti. A kihívás az, hogy a keresési eredmények relevanciáját nem rontva biztosítsuk a hatékony visszakeresést.
- Adatminőség és kontextus megértése: A kétértelmű lekérdezések vagy a rosszul szervezett metaadatok eltéréseket okozhatnak, ami megnehezíti a rendszer számára a felhasználói szándék egyértelmű azonosítását.
Az IR-technológia új trendjei és fejlesztései
A számos akadály ellenére a legújabb technológiai fejlesztések lehetővé tették számunkra, hogy intelligensebb, hatékonyabb rendszereket építsünk.
A modern információkereső rendszerek ma már olyan fejlett módszereket alkalmaznak, mint a gráf alapú elemzés, hogy értelmezzék a számokat, a szöveget, a kontextust, a metaadatokat és az adatpontok közötti kapcsolatokat.
Mit jelent ez a felhasználók számára? Lehetővé teszi a pontosabb szövegkeresést és a részletesebb elemzést, különösen olyan területeken, mint a kutatás és az adatigényes iparágak.
A szemantikus webtechnológiákkal kombinálva a keresési karakterláncokra és a felhasználói szándékra összpontosít. Ezek a rendszerek túlléphetnek a szó szerinti egyezéseken, és rendkívül releváns dokumentumokat tudnak előhívni, még az információkeresési folyamatban felmerülő bonyolult felhasználói lekérdezések esetén is.
Például a „távmunka előnyei” keresésre a rendszer a termelékenységgel, a mentális egészséggel és a munka-magánélet egyensúlyával kapcsolatos eredményeket ad vissza, mivel megérti a kapcsolatokat.
Gyors dokumentumkeresés a ClickUp adatkezelő rendszerével
Végtelen fájlok, alkalmazások és eszközök között kutatni azért, hogy megtalálja azt az egy fontos dokumentumot kimerítő feladat. Képzelje el, hogy kutatóként, hallgatóként, informatikusként vagy adatelemzőként próbálja elemezni a visszakeresett dokumentumokat – ez egyszerűen csak egy információtúlterhelésből álló zűrzavarrá válik.
A ClickUp segítségével soha többé nem kell időt pazarolnia az információk keresésére.
Ez egy olyan all-in-one megoldás, amely egy helyen egyesíti az összes munkáját. Az olyan funkcióknak köszönhetően, mint a Connected Search és a ClickUp Brain, nem számít, hol tárolja az adatait – a ClickUp segítségével könnyedén megtalálhatja, kezelheti és felhasználhatja azokat.
Miért elégedjen meg a „csak rendben” jelzővel, amikor „csodálatos” is lehet? Próbálja ki ingyen a ClickUp-ot, és nézze meg, hogyan alakítja át a munkafolyamatát merész, hatékony és egyenesen megállíthatatlanná!