

A mesterséges intelligencia megváltoztatta, hogy mit kell a mérnököknek maguknak dokumentálniuk. A GitHub Copilot, a Cursor és a Mintlify képesek első lépésként dokumentumokat generálni: paraméterleírásokat, függvényösszefoglalókat és README-vázlatokat. Amit viszont nem tudnak megírni, az az Intent Layer: a meghozott döntés, az elfogadott kompromisszum, a fontos korlátok és a csapat által elutasított lehetőségek.
A kód a viselkedést mutatja. Ritkán őrzi meg az indoklást. Az indoklás általában egy Slack-szálban, jegyhez fűzött megjegyzésben, incidens-áttekintésben vagy valakinek az emlékezetében él.
A Stack Overflow 2024-es fejlesztői felmérése szerint a hivatásos fejlesztők 61%-a naponta több mint 30 percet tölt válaszok keresésével a munkahelyén, és minden negyedik fejlesztő több mint egy órát szán erre. Természetesen bizonyos mértékű keresés elkerülhetetlen. Az igazi pazarlás azonban az a sprintkontextus, amely soha nem került be a dokumentációba.
Ez az útmutató bemutatja, mit kell a mérnököknek maguknak megírniuk, hol segíthet a mesterséges intelligencia, és hogyan lehet a kóddokumentációt a sprint befejezése után is hasznosnak tartani.
TL;DR
Az AI megírhatja a dokumentáció mechanikus rétegét: docstringeket, paramétertípusokat, függvényösszefoglalókat és README-vázlatokat. A mérnököknek továbbra is meg kell írniuk a szándékréteget: a kód mögött álló döntéseket, kompromisszumokat, korlátokat és elvetett lehetőségeket.
A mérnököknek továbbra is maguknak kell megírniuk ezeket az Architecture Decision Records-ban, a PR-leírásokban és a kóddal együtt elküldött „why” megjegyzésekben. A szándék réteg megakadályozza, hogy a következő fejlesztő a változónevek, a commit üzenetek és a régi PR-ek alapján visszafejtsen döntéseket. Az AI most már meg tudja írni a rutin részeket: paramétertípusokat, visszatérési leírásokat és alapvető függvényösszefoglalókat.
Mit kell valójában tartalmaznia a kóddokumentációnak?
A kóddokumentációnak segítenie kell a következő fejlesztőt abban, hogy megértse, mit csinál a kód, hogyan kell biztonságosan használni, és miért építették így. Két helyen jelenik meg: a forrásfájlokon belül megjegyzések és docstringek formájában, valamint a forrásfájlokon kívül README-k, API-referenciák, futtatási útmutatók és architektúra-jegyzetek formájában.
A legtöbb kódbázis nehezen olvashatóvá válik, miután a döntés kontextusa eltűnik. Lehet, hogy az eredeti fejlesztő okos kompromisszumot kötött. A következő fejlesztő azonban csak a végeredményt látja, nem pedig az érvelést.
Az eredmény: minden új csapattag visszafejti a szándékot a változónevek, a commit üzenetek és a régi PR-ek alapján. Ez lassítja az új munkatársak beilleszkedését, a felülvizsgálatokat, a hibakeresést és a jövőbeli változtatásokat ugyanazon a területen.
A jó dokumentáció négy kérdésre ad választ:
- Kinek szól ez a kód? Belső fejlesztőknek, nyílt forráskódú közreműködőknek, külső API-felhasználóknak vagy végfelhasználóknak
- Milyen problémát old meg? A modul mögött álló üzleti vagy technikai igény
- Miért választották ezt a megközelítést? A fontolóra vett alternatívák és az elfogadott kompromisszumok
- Hol találhatók a kapcsolódó elemek? Függő modulok, upstream szolgáltatások, architektúra-döntések, jegyek és futtatási útmutatók
A „miért” kérdés érdemel a legtöbb figyelmet.
A keresés már a mérnöki munkán kívül is jelentős terhet jelent a tudásalapú munkában. A ClickUp tudásmenedzsment-felmérése szerint az alkalmazottak 57%-a vesztegeti az idejét azzal, hogy belső dokumentumokban vagy tudásbázisokban keres munkával kapcsolatos információkat. Ha nem találják meg, amire szükségük van, minden hatodik alkalmazott személyes megoldásokhoz folyamodik: régi e-maileket, jegyzeteket vagy képernyőképeket kutat át.
A kóddokumentáció ugyanúgy megbukik: ha a fejlesztők nem találják meg a magyarázatot, akkor az akár nem is létezhetne.
A hibák ára magas. Az r/AskProgramming egyik kommentelője leírt egy RPA-munkafolyamatot, ahol egy dokumentálatlan gomb nyomására majdnem automatikus banki díjak és ügyféllevelek kerültek kibocsátásra.
A keresés már a mérnöki munkán kívül is jelentős terhet jelent a tudásalapú munkában. A ClickUp tudásmenedzsment-felmérése szerint az alkalmazottak 57%-a vesztegeti az idejét azzal, hogy belső dokumentumokban vagy tudásbázisokban keres munkával kapcsolatos információkat. Amikor nem találják meg, amire szükségük van, minden hatodik alkalmazott személyes megoldásokhoz folyamodik: régi e-maileket, jegyzeteket vagy képernyőképeket kutat át.
A kóddokumentáció is ugyanúgy megbukik: ha a fejlesztők nem találják meg a magyarázatot, akkor az akár nem is létezhetne.
A hibák ára magas. Az r/AskProgramming egyik kommentelője leírt egy RPA-munkafolyamatot, ahol egy dokumentálatlan gomb nyomására majdnem automatikus banki terhelések és ügyféllevelek indultak el.
Melyek a kóddokumentáció főbb típusai?
Az öt fő típus a beágyazott megjegyzések, a docstringek, a README fájlok, a belső wikik és a külső API-dokumentáció. Mindegyik más-más olvasót szolgál ki, más-más pillanatban. Ha ezeket összekeverjük, a dokumentációk megírása és használata is nehezebbé válik. A docstringhez hasonló README elriasztja az új közreműködőket. A wiki-oldalhoz hasonló docstring pedig felesleges terhet jelent a forrásfájlokban.
Beágyazott megjegyzések és docstringek
A soron belüli megjegyzéseknek a nem egyértelmű érvelést kell magyarázniuk. Egy megjegyzés, amely az x = x + 1 kifejezést „x növelése” formában fogalmazza meg, semmit sem ad hozzá. Egy olyan megjegyzés, amely azt mondja, hogy „eltolás a nullával indexelt API-válaszhoz”, megérdemli a helyét, mert a kód nem tudja megmutatni ezt a külső korlátot. A soron belüli megjegyzéseket tartalékolja a függvénytestben található, nem egyértelmű logikára.
A docstringek a függvényekhez, osztályokhoz vagy modulokhoz csatolt strukturált leírások. Kiterjednek a paraméterekre, a visszatérési értékekre, a kivételekre és a használati példákra. Minden nyelvnek megvannak a maga konvenciói. Kövesse az adott nyelv által elvárt konvenciókat: PEP 257 a Python docstringekhez, Javadoc a Java-hoz, valamint JSDoc a JavaScript-hez és a TypeScript-hez.
Hasonlítsa össze ezt a kettőt:
Gyenge docstring:
Erős docstring:
A második egyértelműen megnevezi a függvényt, dokumentálja a paramétereit, és feltár egy feltételezést: a fizetési folyamat 8,25%-os adókulcsot alkalmaz.
README-k, wikik és külső dokumentumok
A README-nek öt kérdésre kell választ adnia a következő sorrendben: Mit csinál ez a projekt? Hogyan telepítsem? Hogyan használjam? Hogyan járulhatok hozzá? Hol kaphatok segítséget? Ha egy új közreműködő nem találja meg gyorsan a telepítési útvonalat, akkor a README vagy túlterhelt, vagy rosszul van rendezve.
A wikik és a tudásbázisok leginkább olyan tartalmakhoz alkalmasak, amelyek több tárolót vagy szolgáltatást is érint: architektúra-döntések, bevezető útmutatók és üzemeltetési kézikönyvek. Egy olyan wiki, amelyre senki sem hivatkozik a kódból, egy második keresési problémává válik.
A külső dokumentáció magában foglalja az API-referenciákat, az SDK-útmutatókat és a felhasználóknak szóló dokumentumokat. Ez a kód felhasználóinak szól, nem pedig a közreműködőknek. A külső dokumentumoknak több beállítási részletre, egyértelműbb hitelesítési lépésekre és referencia-szerű felépítésre van szükségük, mivel az olvasó esetleg egyáltalán nem ismeri a kódbázist.
Ha a csapatnak még nincs struktúrája, kezdjen egy technikai dokumentációs sablonnal az architektúra és a beállítási megjegyzésekhez, vagy egy projektdokumentációs sablonnal a célok, a felelősök, a mérföldkövek és a döntésekhez. Alkalmazza a meglévő szakaszokat, ahelyett, hogy teljesen új formátumot találna ki.
| Típus | Elsődleges célközönség | Frissítési gyakoriság | Jellemző helyszín |
|---|---|---|---|
| Beágyazott megjegyzések | Egy adott kódútvonalat olvasó fejlesztők | Amikor a kód viselkedése megváltozik | Forrásfájlok |
| Docstringek | Funkciót, osztályt vagy modult hívó fejlesztők | Amikor az interfész megváltozik | Forrásfájlok |
| README | Új közreműködők és értékelők | Főbb kiadások vagy projektváltozások szerint | A lerakat gyökérkönyvtára |
| Wiki vagy tudásbázis | Belső csapatok és csapatok közötti érdekelt felek | Ahogy a döntések vagy a folyamatok változnak | Repozitórium-wiki vagy megosztott tudásbázis |
| Külső API-dokumentáció | API-felhasználók és végfelhasználók | Kiadásonként vagy API-verziónként | Dokumentációs platform |
Hogyan írja ma valójában a dokumentációt?
Használja az AI-t azokhoz a részekhez, amelyeket az képes megfogalmazni. Az emberi munkaidőt fordítsa a döntésekre, a korlátokra és a kompromisszumokra.
Az AI ma már a mechanikus munka nagy részét elvégezheti: paramétertípusok, visszatérési leírások és alapvető függvényösszefoglalók. Az emberi dokumentációs munka két kategóriába sorolható.
Először írjon öndokumentáló kódot
A legjobb dokumentáció az a kód, amely alig igényel dokumentációt. A leíró nevek, az egycélú függvények és a következetes konvenciók már az első megjegyzés megírása előtt csökkentik a dokumentációs terhet.
Az öndokumentáló kód megkönnyíti a viselkedés értelmezését. Ritkán magyarázza el azonban a viselkedés mögötti okokat. A nevek segítenek a fejlesztőknek azonosítani, hogy mi a funkciója valaminek. A dokumentációnak azokat az okokat kell elmagyaráznia, amelyeket a névadás nem tud átadni.
Mielőtt megjegyzést fűzne hozzá, kérdezze meg magától, hogy egy változó átnevezése vagy egy függvény kivonása szükségtelenné tenné-e a megjegyzést. Ha a válasz igen, akkor először végezzen refaktorálást. Egy egyértelmű név feleslegessé teszi azokat a megjegyzéseket, amelyek csupán a rossz névválasztást magyarázzák.
Korábban:
Utána:
Az átalakított változat pusztán a névválasztás révén közvetíti ugyanazt az információt. Az egyetlen hasznos megjegyzés most az lenne, amely elmagyarázza, miért vannak kizárva bizonyos szerepkörök, ami egy olyan irányelvi döntés, amelyet a kód önmagában nem tud kifejezni.
Írja meg a szándék réteget (azt a részt, amit az AI nem tud)
A megvalósítás látható a kódban. A szándék eltűnik, ha valaki nem írja le. A kód ritkán őrzi meg, miért született egy kompromisszum, milyen korlátok vezettek egy tervhez, vagy melyik alternatívát utasították el.
Egy általános fejlesztői szabály jól összefoglalja ezt: dokumentálja a miértet, ne a mitet. A r/coding legnépszerűbb kommentje:
Látom, hogy ez a feltételes elágazás a piros és a kék felhasználók között történik. Mondja el, miért osztályozzák így a felhasználókat, és miért történik elágazás közöttük.
Látom, hogy ez a feltételes elágazás a piros és a kék felhasználók között történik. Mondja el, miért osztályozzák így a felhasználókat, és miért történik elágazás közöttük.
A commit üzenet segíthet a felülvizsgálat során, de hosszú távon nem alkalmas a tervezési indoklás tárolására, mivel a jövőbeli olvasók ritkán találják meg azt abban a pillanatban, amikor szükségük lenne rá.
Will Larson, a Calm korábbi technológiai igazgatója és az An Elegant Puzzle című könyv szerzője írt az architektúra-döntési jegyzőkönyvek értékéről, mivel ezek a kódbázison kívül őrzik meg a mérnöki indoklást.
Az ADR-ek azért hasznosak, mert stabil alapot biztosítanak a tervezési indokoknak. Ha a csapatának nincs erre vonatkozó formátuma, használjon egy egyszerű ADR-sablont: döntés, kontextus, mérlegelt lehetőségek, kompromisszumok és következmények.
Dokumentációját a következő kategóriákra összpontosítsa:
- Tervezési döntések és alternatívák: „Itt a write-back helyett a write-through cache-t választottuk, mert ebben a fizetési folyamatban az adatok konzisztenciája fontosabb, mint az írási késleltetés.”
- Ismert korlátozások: technikai adósság, méretezési korlátok, ideiglenes megoldások vagy olyan területek, amelyeket a jövőben rendezni kell
- Feltételezések: A kód által nem érvényesített várható bemeneti formátumok, környezeti követelmények vagy upstream függőségek
- Hivatkozások: Linkek a szélesebb kontextust magyarázó releváns jegyekhez, RFC-khez vagy architektúra-döntési jegyzőkönyvekhez (ADR-ekhez)
A különböző kontextusokhoz különböző helyek kellenek. A docstringek a függvények szintjén rögzítik a szándékot. A kódkommentek a sorok szintjén kezelik az érvelést. A PR-leírások a változások szintjén biztosítják a kontextust. Az ADR-ek a rendszer szintjén kezelik a döntéseket. A commit üzenetek is segítenek, de nem szabad, hogy ezek legyenek az egyetlen feljegyzések egy fontos döntésről.
Gyakori hibás gyakorlat: a rendezési algoritmus működésének soronkénti dokumentálása. A valódi kérdés az, hogy miért használtak egyéni rendezést a szabványos könyvtár helyett. Egyéni kódútvonalak esetén dokumentálja a megvalósítás mögötti döntést.
Melyek a legfontosabb dokumentációs bevált gyakorlatok?
Öt gyakorlat segít abban, hogy a dokumentáció a sprint vége után is hasznos maradjon. A legtöbb egyéb dokumentációs tanács attól függ, hogy ezek a szokások először is működjenek.
- Dokumentáljon a kódolás közben, ne utána. A kontextus gyorsan elhalványul. A következő sprintre már el is felejti, melyik alternatívát utasította el és miért. Írja le a magyarázatot ugyanabban a commitban, mint a kódot, különben egyáltalán nem fogja megírni.
- Használjon egységes stílusútmutatót. Válasszon ki egy docstring formátumot, például a Google-stílust, a NumPy-stílust, a Javadoc-ot vagy a JSDoc-ot, és érvényesítse azt a kódfelülvizsgálat vagy a linting során. Az egységesség fontosabb, mint az, hogy melyik formátumot választja. A közös stílusútmutató kiküszöböli a „hogyan formázzam ezt?” kérdést, és lehetővé teszi az automatizált lintinget.
- Kezelje a dokumentációt a kódfelülvizsgálat részeként. Vegye fel a dokumentáció ellenőrzését a PR-felülvizsgálati ellenőrzőlistájára. Ha egy PR megváltoztatja a viselkedést, a felülvizsgálónak ellenőriznie kell, hogy a dokumentáció tükrözi-e a változást. A Google mérnöki gyakorlatokról szóló dokumentációja arra kéri a felülvizsgálókat, hogy ellenőrizzék, megfelelően van-e dokumentálva a kód. Alkalmazzon ugyanazt a szabályt belsőleg is: ha egy PR megváltoztatja a viselkedést, a felülvizsgálóknak ellenőrizniük kell, hogy a megjegyzések, a docstringek, a README-k és a runbookok továbbra is egyeznek-e
- Törölje az elavult dokumentációt. Az elavult dokumentumok komoly kárt okoznak, mert a olvasókat rossz implementáció, API vagy folyamat felé terelik. Negyedévente vagy minden nagyobb kiadás előtt vizsgálja felül a dokumentumokat. Rendeljen hozzá felelőst, hogy a dokumentáció ne legyen mindenki felelőssége, és így senkié sem.
- A példák legyenek futtathatók. A kódpéldákat könnyen másolni, futtatni és tesztelni kell. Ez a legbiztonságosabb módja annak, hogy a felhasználók előtt észleljük az eltéréseket.
Milyen eszközöket érdemes használni a kóddokumentáció elkészítéséhez?
A dokumentációs eszközök két csoportba sorolhatók: a hagyományos generátorok és a mesterséges intelligencia-asszisztensek. Ezek különböző feladatokat látnak el.
A hagyományos generátorok elemzik a forráskódban található strukturált megjegyzéseket, és böngészhető hivatkozásokat állítanak elő. A megfelelő generátor általában a használt nyelvtől függ.
| Eszköz | Nyelv/Ökoszisztéma | Mit generál |
|---|---|---|
| Javadoc | Java | API-referencia a dokumentációs megjegyzésekből |
| JSDoc | JavaScript/TypeScript | API-referencia kommentekkel ellátott megjegyzésekből |
| Sphinx | Python (más nyelveket pluginok segítségével támogat) | Teljes dokumentációs oldalak reStructuredText vagy Markdown formátumban |
| Doxygen | C, C++, Java, Python és mások | Nyelvközi hivatkozási dokumentáció |
| Godoc | Indulás | Csomagdokumentáció a forráskód megjegyzéseiből |
A kimenet minősége teljes mértékben a docstringjeitől függ. Ezek formázzák és teszik közzé, amit írt. Nem találnak ki hiányzó szándékokat.
Az AI-alapú asszisztensek egy további réteget adnak hozzá. A GitHub Copilot, a Cursor és a Windsurf megjegyzéseket és docstringeket tud megfogalmazni az editoron belül. A Mintlify segíthet a fejlesztői dokumentációk létrehozásában és karbantartásában a kód és a meglévő dokumentáció alapján. A Swimm arra összpontosít, hogy a belső dokumentációkat a kódváltozásokhoz kössék. A ReadMe és a GitBook segít a csapatoknak API-referenciák és fejlesztőknek szóló dokumentációk közzétételében, gyakran AI-támogatott keresési vagy szerzői funkciókkal.
A Stack Overflow tanulmánya megállapította, hogy a dokumentáció volt a leggyakrabban kért AI-automatizálási kategória , amelyet a fejlesztők nyitott kérdésekre adott válaszaik körülbelül 33,9%-ában említettek. Ezek az eszközök akkor a leghatékonyabbak, ha a forráskód már eleve egyértelműen feltárja a viselkedést.
Az AI gyengébbé válik, ha a magyarázat a kódbázison kívül hozott döntésektől függ: egy Slack-szál, egy tervezési megbeszélés, egy jegy vagy egy incidens-áttekintés. Összefoglalhatja a funkciót. Nem tudja azonban, melyik korlátozás volt tárgyalható, melyik opciót utasították el, vagy miért fogadták el a kompromisszumot.
Gyakorlati munkafolyamat:
- Hagyja, hogy a mesterséges intelligencia készítse el a vázlatot: a függvény összefoglalását, paramétereit, visszatérési értékeit és a gyakori kivételeket
- Hasonlítsa össze a kód tényleges viselkedésével
- Adja hozzá az okot: a döntést, a korlátot, a feltételezést vagy az elvetett alternatívát
- Írjon ADR-t a rendszer szintű döntésekhez
- Ne tegyen közzé AI által generált dokumentumokat felülvizsgálat nélkül
Hol illeszkedik a ClickUp, és hol nem
A ClickUp nem kódszintű dokumentáció-generátor. Nem helyettesíti a Javadocot, a Sphinxet, a JSDocot vagy a Godocot. Segít a kód körüli dokumentációban: README-k, futtatási útmutatók, bevezető útmutatók, ADR-ek és döntési naplók, amelyeknek kapcsolatban kell maradniuk azokkal a feladatokkal, jegyekkel és sprintekkel, amelyekből származnak.
A ClickUp Docs segítségével ezeket a mérnöki munkája mellett is megfogalmazhatja, a ClickUp Brain pedig a feladat vagy a projekt kontextusából készíthet dokumentumvázlatot, amelyhez a fejlesztők hozzáadhatják a döntés indokait, a korlátokat és a kompromisszumokat.
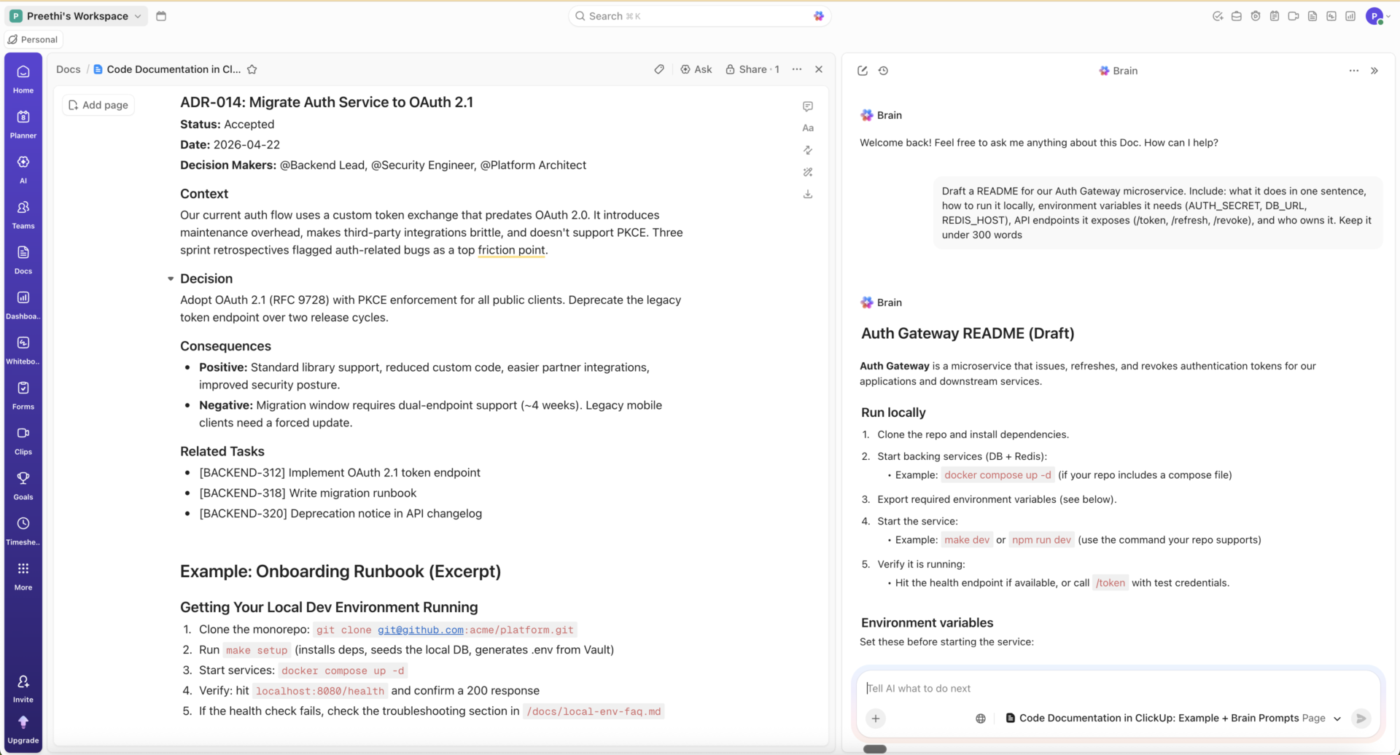
A mérnöki csapatok számára ez azt jelenti, hogy kevesebb időt kell szétszórt dokumentumok, csevegések és jegyek között kutatni, és több időt fordíthatnak azokra a döntésekre, amelyeket ezek az eszközök általában eltemetnek.
Ha az Ön problémája az, hogy „a dokumentációnk technikailag teljes, de senki sem találja meg”, akkor ez egy megtalálhatósági probléma. Egy összekapcsolt munkaterület segíthet.
Ha az Ön problémája az, hogy „az API-referenciánk elavult”, akkor az generálási és felülvizsgálati probléma. A Sphinx, a Javadoc, a JSDoc vagy a Godoc többet segít, mint egy munkaterületi eszköz. Ne keverje össze a kettőt.
Mi változik, ha a dokumentáció nagy részét a mesterséges intelligencia írja?
Az r/developersIndia, r/webdev és r/AskProgramming fórumokon gyakran felbukkan egy vicc a mérnöki dokumentációval kapcsolatban. Amikor valaki megkérdezi, hogy a csapat hogyan kezeli a dokumentációt, a leggyakrabban kapott válasz valamilyen formában a következő: „Én vagyok a dokumentáció.”
Vicces, mert igaz. Évek óta a hiányzó dokumentáció helyettesítésére az a mérnök szolgál, aki véletlenül emlékszik rá.
A mesterséges intelligencia megváltoztatja az alapvető elvárásokat. Gyorsan elkészítheti a rutin dokumentációt, ami miatt a dokumentálatlan döntéseket nehezebb lesz igazolni. Amikor a mesterséges intelligencia másodpercek alatt felépíti a dokumentumok mechanikus részeit, a „majd megjegyzem” már nem elfogadható indok a rögzítés helyett.
Ezáltal a mérnök munkája a szándék, a döntések és a kompromisszumok felé tolódik el: azok a részek, amelyeket a szintaxis önmagában nem tud megmagyarázni.
A régi dokumentációs tanácsok nagy része még a mesterséges intelligencia előtti munkafolyamatokra készült. Ezek elsősorban a paraméterek leírására, a függvények aláírására és a részletes beállítási megjegyzésekre koncentrálnak.
Az AI ma már ennek a munkának a nagy részét elvégezheti. Ha a mérnökök a dokumentálásra szánt idejük nagy részét mechanikus összefoglalókra fordítják, akkor az emberi figyelmet a legkevésbé értékes rétegre összpontosítják.
Szánjon időt a szándékra: miért létezik a funkció, melyik lehetőséget utasította el, és milyen feltételezésen alapul a kód. Ezekre a jegyzetekre lesz szüksége a jövőbeli csapatának, az AI kódoló ügynököknek és annak a mérnöknek, aki 2027-ben átveszi a kódbázist.
Ha a dokumentációs problémája a szétszórt kontextus, a ClickUp segíthet abban, hogy a döntések története közelebb maradjon azokhoz a feladatokhoz, dokumentumokhoz és projektekhez, amelyek során születtek.
Gyakran feltett kérdések a kóddokumentációról
Mi az a README?
A README akkor felel meg az első tesztnek, ha a közreműködő gyorsan megtalálja az alábbi öt dolgot: mit csinál a projekt, hogyan kell telepíteni, hogyan kell használni, hogyan lehet hozzájárulni, és hol lehet segítséget kapni. Ha a beállítások el vannak rejtve a jelvények, az architektúra megjegyzései vagy a változásnapló részletei alatt, akkor a README rosszul van felépítve.
Mi a különbség a kódkommentek és a dokumentáció között?
A kódkommentek a forrásfájlokban találhatók, és konkrét sorokat vagy blokkokat magyarázzák. A dokumentáció általában a forrásfájlokon kívül található, README-fájlokban, wikikben, generált referenciaoldalakon vagy API-dokumentációkban. A kommentek segítenek a következő fejlesztőnek, aki elolvassa a függvényét. A dokumentáció pedig annak segít, aki a projektjét használni, futtatni vagy ahhoz hozzájárulni próbál.
Mi az a szándékréteg a kóddokumentációban?
Az Intent Layer (szándékréteg) a kóddokumentáció azon része, amely nem azt rögzíti, hogy mit csinál a kód, hanem azt, hogy miért létezik: a meghozott döntést, az elfogadott kompromisszumot, a tervezést meghatározó korlátokat és a csapat által elutasított lehetőségeket. A kód a viselkedést mutatja, az Intent Layer pedig az indokokat őrzi meg. Az olyan AI-eszközök, mint a GitHub Copilot és a Mintlify, meg tudják fogalmazni a mechanikus réteget (paramétertípusok, függvényösszefoglalók), de a szintaxisból nem tudják levezetni a szándékréteget. Ez általában az architektúra-döntési jegyzőkönyvekben, a PR-leírásokban vagy a megjegyzésekben található, amelyek inkább a miért-et, mint a mit magyarázzák.
Milyen gyakran kell frissíteni a kóddokumentációt?
Frissítse a dokumentációt ugyanabban a pull requestben, amely megváltoztatja az alapul szolgáló viselkedést. Ha egy függvény szignatúrája megváltozik, a docstring is megváltozik abban a PR-ben. A README-k és az architektúra-dokumentumok esetében legalább minden kiadáskor vagy negyedévente végezzen ellenőrzést. Az elavult dokumentáció veszélyes, mert rossz viselkedést, API-t vagy folyamatot tanít az olvasóknak.
Melyek a dokumentáció négy típusa?
A széles körben elterjedt Diátaxis keretrendszer a dokumentációt négy típusra osztja: oktatóanyagok (tanulásorientált, kezdőknek), útmutatók (feladatorientált, egy konkrét problémát megoldó felhasználóknak), referencia (információorientált, részleteket kereső felhasználóknak) és magyarázat (megértésorientált, kontextust kereső felhasználóknak). Ezek keverése olyan dokumentációt eredményez, amelyet senki sem tud használni. Egy olyan README, amely teljes oktatóanyagnak próbál lenni, elrejtheti a telepítési útvonalat. Egy esszé formájában megírt referenciaoldal elrejtheti az API-hívást.
Hogyan dokumentálja a kódot a mesterséges intelligencia segítségével?
Használja az AI-t a mechanikai réteghez, és írja meg maga a szándékréteget. Az olyan eszközök, mint a GitHub Copilot, a Cursor és a Mintlify, közvetlenül a szerkesztőjében készíthetnek vázlatot a docstringekről, a paraméterleírásokról, a visszatérési értékekről és a függvényösszefoglalásokról. Hasonlítsa össze a vázlatot a kód tényleges viselkedésével, majd adja hozzá azokat a részeket, amelyeket az AI nem tud kikövetkeztetni: a döntés indoklását, a döntést motiváló korlátot, az elutasított opciót és minden olyan feltételezést, amelyre a kód épül. Rendszer szintű döntések esetén írjon Architecture Decision Record-ot. Soha ne tegyen közzé AI által generált dokumentumokat emberi áttekintés nélkül.
Megbízhatóak az AI által generált dokumentációk?
Az AI által generált dokumentáció hasznos olyan mechanikus feladatokhoz, mint a paraméterek leírása, a visszatérési értékek és az alapvető funkciók összefoglalása, de még mindig szükség van emberi ellenőrzésre. Az olyan eszközök, mint a GitHub Copilot, a Cursor, a Codeium és a Mintlify, jól kezelik ezeket a feladatokat. Az AI nem tudja következtetni, hogy miért született egy kompromisszum, mely alternatívákat utasítottak el, vagy milyen termék-, üzleti vagy infrastrukturális korlátok alakították a tervezést. Használja az AI-t az első vázlat elkészítéséhez. A szándékot és a kontextust adja hozzá saját maga.
Minden függvénynek szüksége van docstringre?
Nem. A nyilvános API-knak és minden olyan függvénynek, amelyet más fejlesztők is meghívnak, szükségük van docstringekre. Az egy fájlban használt privát segítő függvényeknek általában nincs szükségük rá, kivéve, ha a logikájuk nem egyértelmű. A triviális kód túlzott dokumentálása karbantartási terhet jelent anélkül, hogy egyértelműbbé tenné a kódot. A dokumentáció részletességét igazítsa a függvény célközönségéhez.
Mi a legjobb eszköz a kóddokumentáció létrehozásához?
A megfelelő eszköz a használt nyelvtől függ. A Java-csapatok a Javadoc-ot, a JavaScript- és TypeScript-csapatok a JSDoc-ot, a Python-csapatok a Sphinx-et, a Go-csapatok a Godoc-ot használják, míg a Doxygen a C, C++ és számos más nyelvet kezeli. Az olyan AI-támogatott eszközök, mint a Mintlify, a Swimm, a Copilot és a Cursor, segíthetnek a dokumentáció megírásában vagy karbantartásában a munkafolyamat különböző részein, de nem helyettesítik a nyelvhez tartozó generátorokat.
Milyen hosszú legyen egy README fájl?
Legyen elég hosszú ahhoz, hogy gyorsan megválaszolja az alapvető kérdéseket: mit csinál a projekt, hogyan kell telepíteni, hogyan kell használni, hogyan lehet hozzájárulni, és hol lehet segítséget kapni. A részletesebb beállítási, architektúra- és API-adatokat helyezze el linkelt dokumentumokban vagy alkönyvtárakban.