![Jak trénovat Gemini na vašich vlastních datech v roce [rok]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Podle nedávné studie podniků 73 % organizací uvádí, že jejich modely umělé inteligence nerozumí terminologii a kontextu specifickému pro danou společnost, což vede k výstupům, které vyžadují rozsáhlé ruční opravy. To se stává jednou z největších výzev při zavádění umělé inteligence.
Velké jazykové modely, jako je Google Gemini, jsou již trénovány na rozsáhlých veřejných datových sadách. Většina společností ve skutečnosti nepotřebuje trénovat nový model, ale naučit Gemini kontext vaší firmy: vaše dokumenty, pracovní postupy, zákazníky a interní znalosti.
Tento průvodce vás provede kompletním procesem trénování modelu Gemini od Google na vašich vlastních datech. Pokryjeme vše od přípravy datových sad ve správném formátu JSONL až po spuštění ladicích úloh v Google AI Studio.
Zjistíme také, zda vám konvergované pracovní prostředí s integrovaným kontextem AI může ušetřit týdny času stráveného nastavováním.
Co je ladění Gemini a proč je důležité?
Dolaďování Gemini je proces trénování základního modelu Google na vašich vlastních datech.
Chcete umělou inteligenci, která rozumí vašemu podnikání, ale hotové modely poskytují obecné odpovědi, které se míjí účinkem. To znamená, že ztrácíte čas neustálým opravováním výstupů, opakovaným vysvětlováním terminologie vaší společnosti a frustrací, když umělá inteligence prostě nerozumí.
Toto neustálé přecházení mezi jednotlivými kroky zpomaluje váš tým a podkopává slib produktivity umělé inteligence.
Díky doladění Gemini vytvoříte vlastní model Gemini, který se naučí vaše specifické vzorce, tón a znalosti dané oblasti, což mu umožní přesněji reagovat na vaše jedinečné případy použití. Tento přístup funguje nejlépe u konzistentních, opakovatelných úkolů, u kterých základní model opakovaně selhává.
Jak se jemné ladění liší od prompt engineeringu
Prompt engineering zahrnuje zadávání dočasných pokynů založených na relaci pokaždé, když s modelem komunikujete. Jakmile konverzace skončí, model zapomene váš kontext.
Tento přístup naráží na své limity, pokud váš případ použití vyžaduje specializované znalosti, které základní model prostě nemá. Můžete zadat pouze omezené množství pokynů, než bude model muset skutečně naučit vaše vzorce.
Naopak jemné ladění trvale upravuje chování modelu změnou jeho vnitřních vah na základě vašich tréninkových příkladů, takže změny přetrvávají ve všech budoucích relacích.
Dolaďování není rychlým řešením pro příležitostné frustrace s AI; je to významná investice času a dat. Má největší smysl v konkrétních scénářích, kde základní model neustále selhává a vy potřebujete trvalé řešení.
Zvažte doladění, pokud potřebujete, aby AI zvládla:
- Specializovaná terminologie: Ve vašem odvětví se používá odborná terminologie, kterou model neustále nesprávně interpretuje nebo nedokáže správně použít.
- Konzistentní výstupní formát: Potřebujete pokaždé odpovědi ve velmi specifické struktuře, například pro generování reportů nebo úryvků kódu.
- Odborné znalosti v dané oblasti: Model postrádá znalosti o vašich specializovaných produktech, interních procesech nebo proprietárních pracovních postupech.
- Hlas značky: Chcete, aby všechny výstupy generované umělou inteligencí dokonale odpovídaly hlasu, stylu a osobnosti vaší značky.
| Aspekt | Prompt engineering | Jemné ladění |
| Co to je | Vytvoření lepších pokynů v příkazu pro řízení chování modelu | Další trénování modelu na vašich vlastních příkladech |
| Jaké změny | Vstupní data, která do modelu zadáte | Vnitřní váhy modelu |
| Rychlost implementace | Okamžité – funguje okamžitě | Pomalé – vyžaduje přípravu datového souboru a čas na trénování |
| Technická složitost | Nízká – nejsou nutné žádné znalosti v oblasti strojového učení | Střední až vysoká – vyžaduje ML pipeline |
| Požadovaná data | Několik dobrých příkladů v rámci výzvy | Stovky až tisíce označených příkladů |
| Konzistence výstupu | Střední — liší se podle výzev | Vysoká – chování je zakomponováno do modelu |
| Nejvhodnější pro | Jednorázové úkoly, experimenty, rychlá iterace | Opakující se úkoly vyžadující konzistentní výstupy |
Prompt engineering určuje, co modelu sdělíte. Fine-tuning určuje, jak model uvažuje.
Ačkoli se tento článek zaměřuje na Gemini, porozumění alternativním přístupům k přizpůsobení AI může poskytnout cenný pohled na různé metody k dosažení podobných cílů.
Toto video ukazuje , jak vytvořit vlastní GPT, což je další oblíbený přístup k přizpůsobení AI pro konkrétní případy použití:
📖 Přečtěte si také: Jak se stát promptovým inženýrem
Jak připravit trénovací data pro Gemini
Většina projektů jemného ladění selže ještě předtím, než vůbec začnou, protože týmy podceňují proces přípravy dat. Společnost Gartner předpovídá, že 60 % projektů umělé inteligence bude opuštěno kvůli nedostatečné připravenosti dat pro umělou inteligenci.
Můžete strávit týdny nesprávným shromažďováním a formátováním dat, jen aby nakonec selhalo trénování nebo vznikl nepoužitelný model. To je často nejčasově náročnější část celého procesu, ale správné provedení je nejdůležitějším faktorem úspěchu.
Zde platí zásada „garbage in, garbage out“ (co tam dáte, to tam máte). Kvalita vašeho vlastního modelu bude přímo odrážet kvalitu dat, na kterých jej trénujete.
Požadavky na formát datového souboru
Gemini vyžaduje, aby vaše trénovací data byla v konkrétním formátu zvaném JSONL, což je zkratka pro JSON Lines. V souboru JSONL je každý řádek kompletním, samostatným objektem JSON, který představuje jeden trénovací příklad. Tato struktura usnadňuje systému zpracování velkých datových sad po jednotlivých řádcích.
Každý trénovací příklad musí obsahovat dvě klíčová pole:
- text_input: Toto je výzva nebo otázka, kterou byste modelu položili.
- výstup: Toto je ideální, dokonalá odpověď, kterou chcete, aby se model naučil generovat.
Pro větší pohodlí Google AI Studio také přijímá soubory ve formátu CSV a převede je za vás do požadované struktury JSONL.
Pokud je váš tým zvyklý pracovat s tabulkami, může to usnadnit počáteční zadávání dat.
Doporučení ohledně velikosti datového souboru
Ačkoli kvalita je důležitější než kvantita, stále potřebujete minimální počet příkladů, aby model mohl rozpoznat a naučit se vzorce. Pokud začnete s příliš malým počtem příkladů, výsledkem bude model, který nebude schopen generalizovat ani spolehlivě fungovat.
Zde je několik obecných pokynů pro velikost datového souboru:
- Minimální proveditelnost: U jednoduchých, vysoce specifických úkolů můžete začít vidět výsledky s přibližně 100 až 500 vysoce kvalitními příklady.
- Lepší výsledky: Pro složitější nebo nuancovanější výstupy je vhodné použít 500 až 1 000 příkladů, což zajistí robustnější a spolehlivější model.
- Klesající výnosy: V určitém okamžiku již pouhé přidávání dalších opakujících se dat výrazně nezlepší výkon. Zaměřte se spíše na rozmanitost a kvalitu než na pouhý objem.
Shromáždění stovek vysoce kvalitních příkladů je pro většinu týmů velkou výzvou. Než se pustíte do procesu ladění, naplánujte si tuto fázi sběru dat odpovídajícím způsobem.
📮 ClickUp Insight: Průměrný profesionál stráví více než 30 minut denně hledáním informací souvisejících s prací – to je více než 120 hodin ročně ztracených prohledáváním e-mailů, konverzací na Slacku a roztroušených souborů.
Inteligentní AI asistent zabudovaný do vašeho pracovního prostoru to může změnit. Představujeme ClickUp Brain. Poskytuje okamžité informace a odpovědi tím, že během několika sekund vyhledá správné dokumenty, konverzace a podrobnosti úkolů – takže můžete přestat hledat a začít pracovat.
💫 Skutečné výsledky: Týmy jako QubicaAMF ušetřily díky ClickUp více než 5 hodin týdně, což představuje přes 250 hodin ročně na osobu, a to díky odstranění zastaralých procesů správy znalostí. Představte si, co by váš tým mohl vytvořit s extra týdnem produktivity každý čtvrtrok!
Osvědčené postupy pro kvalitu dat
Nekonzistentní nebo protichůdné příklady model zmate, což povede k nespolehlivým a nepředvídatelným výstupům. Abyste tomu zabránili, musíte svá trénovací data pečlivě vybírat a čistit. Jediný špatný příklad může zrušit výsledky učení z mnoha dobrých příkladů.
Postupujte podle těchto pokynů, abyste zajistili vysokou kvalitu dat:
- Konzistence: Všechny příklady by měly mít stejný formát, styl a tón. Pokud chcete, aby AI byla formální, všechny vaše výstupní příklady by měly být formální.
- Rozmanitost: Váš datový soubor by měl pokrývat celou škálu vstupů, se kterými se model pravděpodobně setká v reálném použití. Netrénujte jej pouze na jednoduchých případech.
- Přesnost: Každý jednotlivý výstupní příklad musí být dokonalý. Měl by to být přesně ten výstup, který chcete, aby model produkoval, bez jakýchkoli chyb nebo překlepů.
- Čistota: Před tréninkem musíte odstranit duplicitní příklady, opravit všechny pravopisné a gramatické chyby a vyřešit případné rozpory v datech.
Důrazně doporučujeme, aby příklady pro trénování zkontrolovalo a ověřilo více osob. Čerstvý pohled často odhalí chyby nebo nesrovnalosti, které vám mohly uniknout.
Jak krok za krokem doladit Gemini
Proces ladění Gemini zahrnuje několik technických kroků napříč platformami Google. Jediná nesprávná konfigurace může znamenat ztrátu hodin cenného času věnovaného tréninku a výpočetních zdrojů, což vás donutí začít znovu. Tento praktický návod je navržen tak, aby omezil pokusy a omyly, a provede vás procesem od začátku do konce. 🛠️
Než začnete, budete potřebovat účet Google Cloud s povoleným účtováním a přístupem k Google AI Studio. Vyhraďte si alespoň několik hodin na počáteční nastavení a první tréninkovou úlohu, plus další čas na testování a iterování vašeho modelu.
Krok 1: Nastavte Google AI Studio
Google AI Studio je webové rozhraní, ve kterém budete spravovat celý proces ladění. Poskytuje uživatelsky přívětivý způsob nahrávání dat, konfigurace tréninku a testování vašeho vlastního modelu bez nutnosti psát kód.
Nejprve přejděte na stránku ai.google.dev a přihlaste se pomocí svého účtu Google.
Budete muset přijmout podmínky služby a vytvořit nový projekt v Google Cloud Console, pokud jej ještě nemáte. Nezapomeňte povolit potřebná API podle pokynů platformy.
Krok 2: Nahrajte svůj trénovací datový soubor
Po dokončení nastavení přejděte do sekce ladění v Google AI Studio. Zde zahájíte proces vytváření vlastního modelu.
Vyberte možnost „Vytvořit vyladěný model“ a vyberte základní model. Gemini 1. 5 Flash je běžnou a nákladově efektivní volbou pro jemné ladění.
Poté nahrajte soubor JSONL nebo CSV obsahující vámi připravený trénovací datový soubor. Platforma poté ověří, zda váš soubor splňuje požadavky na formátování, a označí případné běžné chyby, jako jsou chybějící pole nebo nesprávná struktura.
Krok 3: Nakonfigurujte nastavení jemného ladění
Po nahrání a ověření dat nakonfigurujete parametry tréninku. Tato nastavení, známá jako hyperparametry, řídí, jak se model učí z vašich dat.
Klíčové možnosti, které uvidíte, jsou:
- Epochy: Určuje, kolikrát se model bude trénovat na celém vašem datovém souboru. Více epoch může vést k lepšímu učení, ale také k riziku přetrénování.
- Rychlost učení: Určuje, jak agresivně model upravuje své váhy na základě vašich příkladů.
- Velikost dávky: Nastavuje, kolik trénovacích příkladů se zpracovává společně v jedné skupině.
Při prvním pokusu je nejlepší začít s výchozím nastavením doporučeným Google AI Studio. Platforma zjednodušuje tato složitá rozhodnutí, takže je přístupná i pro ty, kteří nejsou odborníky na strojové učení.
Krok 4: Spusťte úlohu ladění
Po nakonfigurování nastavení můžete zahájit ladění. Servery Google začnou zpracovávat vaše data a upravovat parametry modelu. Tento proces trénování může trvat několik minut až několik hodin, v závislosti na velikosti vašeho datového souboru a vybraném modelu.
Průběh úlohy můžete sledovat přímo v ovládacím panelu Google AI Studio. Jelikož se úloha spouští na serverech Google, můžete bez obav zavřít prohlížeč a vrátit se později, abyste zkontrolovali stav. Pokud úloha selže, je to téměř vždy způsobeno problémem s kvalitou nebo formátováním vašich trénovacích dat.
Krok 5: Otestujte svůj vlastní model
Jakmile je trénink dokončen, je váš vlastní model připraven k testování. ✨
Přístup k němu získáte prostřednictvím rozhraní playground v Google AI Studio.
Začněte tím, že mu pošlete testovací podněty podobné vašim tréninkovým příkladům, abyste ověřili jeho přesnost. Poté jej otestujte na okrajových případech a nových variantách, které dosud neviděl, abyste vyhodnotili jeho schopnost generalizace.
- Přesnost: Produkuje přesně ty výstupy, na které jste jej trénovali?
- Zobecnění: Zpracovává správně nové vstupy, které jsou podobné, ale ne identické s vašimi trénovacími daty?
- Konzistence: Jsou jeho odpovědi spolehlivé a předvídatelné při více pokusech se stejným podnětem?
Pokud výsledky nejsou uspokojivé, pravděpodobně budete muset vrátit se zpět, vylepšit trénovací data přidáním dalších příkladů nebo opravou nesrovnalostí a poté model znovu trénovat.
📖 Přečtěte si také: Jak co nejlépe využít AI pro inovace a efektivitu
Osvědčené postupy pro trénování Gemini na vlastních datech
Pouhé dodržení technických kroků nezaručuje vytvoření skvělého modelu. Mnoho týmů dokončí tento proces, ale je zklamáno výsledky, protože jim chybí optimalizační strategie, které používají zkušení odborníci. To je to, co odlišuje funkční model od vysoce výkonného modelu.
Není překvapením, že zpráva Deloitte o stavu generativní AI v podnicích zjistila, že dvě třetiny společností uvádějí, že 30 % nebo méně jejich experimentů s generativní AI bude plně škálováno do šesti měsíců.
Přijetím těchto osvědčených postupů ušetříte čas a dosáhnete mnohem lepších výsledků.
- Začněte v malém měřítku a poté rozšiřujte: Než se pustíte do úplného tréninku, otestujte svůj přístup na malé podmnožině svých dat (např. 100 příkladech). To vám umožní ověřit formát dat a rychle získat představu o výkonu, aniž byste ztráceli čas.
- Verzujte své datové sady: Při přidávání, odstraňování nebo úpravách trénovacích příkladů ukládejte každou verzi své datové sady. To vám umožní sledovat změny, reprodukovat výsledky a vrátit se k předchozí verzi, pokud nová verze funguje hůře.
- Testujte před a po: Než začnete s laděním, stanovte si základní linii vyhodnocením výkonu základního modelu při plnění klíčových úkolů. To vám umožní objektivně změřit, jakého zlepšení jste dosáhli díky ladění.
- Opakujte neúspěchy: Když váš vlastní model vyprodukuje nesprávnou nebo špatně formátovanou odpověď, nenechte se tím odradit. Přidejte tento konkrétní neúspěšný případ jako nový, opravený příklad do svých trénovacích dat pro další opakování.
- Zaznamenejte svůj postup: Vedejte si záznamy o každém tréninku a zaznamenávejte použitou verzi datového souboru, hyperparametry a výsledky. Tato dokumentace je neocenitelná pro pochopení toho, co v průběhu času funguje a co ne.
Správa těchto iterací, verzí datových sad a dokumentace vyžaduje robustní projektové řízení. Centralizace této práce na platformě určené pro strukturované pracovní postupy může zabránit chaosu v procesu.
Časté výzvy při trénování Gemini
Týmy často investují značné množství času a zdrojů do ladění, jen aby narazily na předvídatelné překážky, které vedou ke zbytečné námaze a frustraci. Pokud budete předem znát tyto běžné úskalí, můžete procesem projít hladčeji.
Zde jsou některé z nejčastějších výzev a způsoby, jak je řešit:
- Přizpůsobení: K tomu dochází, když si model dokonale zapamatuje vaše tréninkové příklady, ale nedokáže je zobecnit na nové, dosud neznámé vstupy. Chcete-li tento problém vyřešit, můžete přidat více rozmanitosti do svých tréninkových dat, zvážit snížení počtu epoch nebo prozkoumat alternativní metody, jako je generování rozšířené o vyhledávání.
- Nekonzistentní výstupy: Pokud model poskytuje různé odpovědi na velmi podobné otázky, je to pravděpodobně proto, že vaše trénovací data obsahují protichůdné nebo nekonzistentní příklady. K vyřešení těchto konfliktů je nutné provést důkladné čištění dat.
- Formátový posun: Někdy model nejprve sleduje požadovanou výstupní strukturu, ale postupem času se od ní „odchýlí“. Řešením je zahrnout do výstupu trénovacích příkladů explicitní pokyny k formátu, nejen obsah.
- Pomalé iterační cykly: Pokud každý tréninkový běh trvá několik hodin, výrazně to zpomaluje vaši schopnost experimentovat a vylepšovat. Nejprve otestujte své nápady na menších datových sadách, abyste získali rychlejší zpětnou vazbu, než spustíte úplný tréninkový úkol.
- Úzké místo při sběru dat: Nejčastěji je nejtěžší částí úzké místo při sběru dat, tedy shromáždění dostatečného množství kvalitních příkladů. Začněte tím, že využijete svůj nejlepší stávající obsah, jako jsou žádosti o podporu, marketingové texty nebo technické dokumenty, a odtud pokračujte dál.
Tyto výzvy jsou hlavním důvodem, proč mnoho týmů nakonec hledá alternativy k ručnímu procesu ladění.
📮ClickUp Insight: 88 % respondentů našeho průzkumu používá AI pro své osobní úkoly, ale více než 50 % se bojí ji používat v práci. Tři hlavní překážky? Nedostatečná integrace, mezery ve znalostech nebo obavy o bezpečnost. Ale co když je AI zabudována do vašeho pracovního prostoru a je již zabezpečená? ClickUp Brain, vestavěný AI asistent ClickUp, to umožňuje. Rozumí pokynům v běžném jazyce, řeší všechny tři obavy spojené s přijetím AI a zároveň propojuje váš chat, úkoly, dokumenty a znalosti v celém pracovním prostoru. Najděte odpovědi a poznatky jediným kliknutím!
Proč je ClickUp chytřejší alternativou
Dolaďování Gemini je účinné, ale je to také provizorní řešení.
V tomto článku jsme viděli, že ladění má v konečném důsledku jeden cíl: naučit AI rozumět kontextu vašeho podnikání. Problémem je, že ladění to dělá nepřímo. Připravujete datové sady, vytváříte příklady, přeučujete modely a udržujete pipeline, aby AI mohla přibližně odhadnout, jak váš tým pracuje.
To dává smysl pro specializované případy použití. Pro většinu týmů však skutečným cílem není personalizace Gemini sama o sobě. Cíl je jednodušší:
Chcete AI, která rozumí vaší práci.
V tomto ohledu má ClickUp zásadně odlišný – a chytřejší – přístup.
Converged AI Workspace od ClickUp poskytuje vašemu týmu umělou inteligenci, která okamžitě rozumí kontextu vaší práce – bez nutnosti náročného nastavování. Namísto trénování umělé inteligence, aby se naučila váš kontext později, pracujete s ClickUp Brain, integrovaným asistentem umělé inteligence, kde váš kontext již existuje.
Vaše úkoly, dokumenty, komentáře, historie projektů a rozhodnutí jsou nativně propojeny. Není třeba trénovat AI na vašich datech, protože již existuje tam, kde pracujete, a využívá váš stávající ekosystém správy znalostí.
| Aspekt | Jemné ladění Gemini | ClickUp Brain |
|---|---|---|
| Doba nastavení | Příprava dat trvá několik dní až týdnů. | Okamžité – funguje s existujícími daty pracovního prostoru |
| Zdroj kontextu | Ručně vybrané příklady pro trénink | Automatický přístup ke všem připojeným pracím |
| Údržba | Přeškolte systém, když se změní vaše potřeby. | Průběžně aktualizováno podle vývoje vašeho pracovního prostoru |
| Požadované technické dovednosti | Střední až vysoká | Žádné |
Protože ClickUp je váš pracovní systém, ClickUp Brain funguje uvnitř vašeho propojeného datového grafu. Neexistuje žádné rozptýlení AI napříč nepropojenými nástroji, žádné křehké tréninkové procesy a žádné riziko, že model přestane být v souladu s tím, jak váš tým skutečně pracuje.
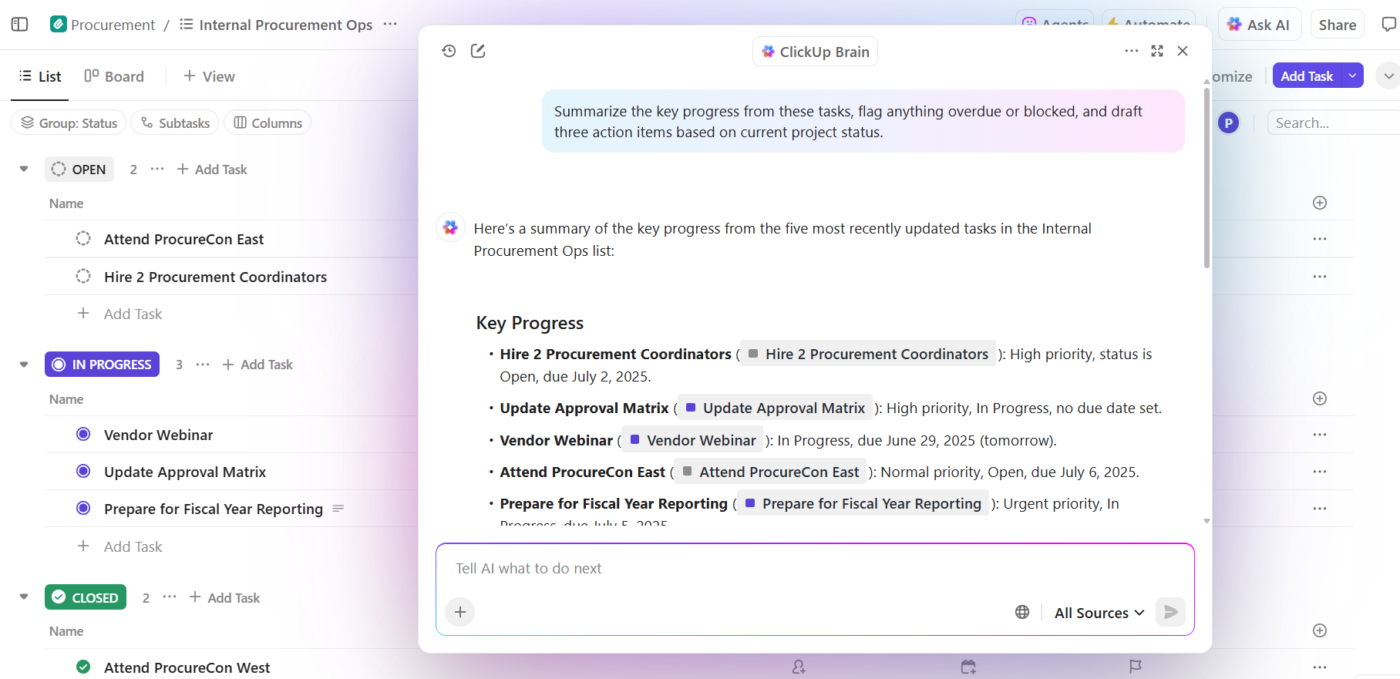
Takto to vypadá v praxi:
- Ptejte se na své projekty: ClickUp Brain provádí vyhledávání v pracovním prostoru napříč úkoly, dokumenty, komentáři a aktualizacemi, aby odpovídal na otázky pomocí vašich skutečných projektových dat – nikoli obecnými znalostmi z tréninku.
- Generujte obsah s kontextem: ClickUp Brain již má zabezpečený přístup k vašim úkolům, souborům, komentářům a historii projektů. Může vytvářet dokumenty, souhrny a aktualizace stavu, které odkazují na vaši skutečnou práci, časové osy a priority. Už žádné rozptýlení kontextu, kdy týmy ztrácejí hodiny hledáním informací v různých aplikacích a souborech.
- Automatizujte s porozuměním: S ClickUp Automations můžete vytvořit automatizaci, která inteligentně reaguje na kontext projektu, jako jsou termíny, vlastnictví a změny stavu, a ne jen na statická pravidla. AI je může dokonce vytvořit za vás, bez nutnosti programování.
💡Tip pro profesionály: Využijte skutečnou sílu umělé inteligence ve svém pracovním prostředí s ClickUp Super Agents.
Super agenti jsou týmoví kolegové ClickUp pohánění umělou inteligencí – jsou nakonfigurováni jako „uživatelé“ umělé inteligence, kteří spolupracují s vaším týmem v rámci pracovního prostoru. Jsou ambientní a kontextoví a lze je přiřadit k úkolům, zmínit v komentářích, spustit prostřednictvím událostí nebo plánů nebo řídit prostřednictvím chatu – stejně jako lidského kolegu.
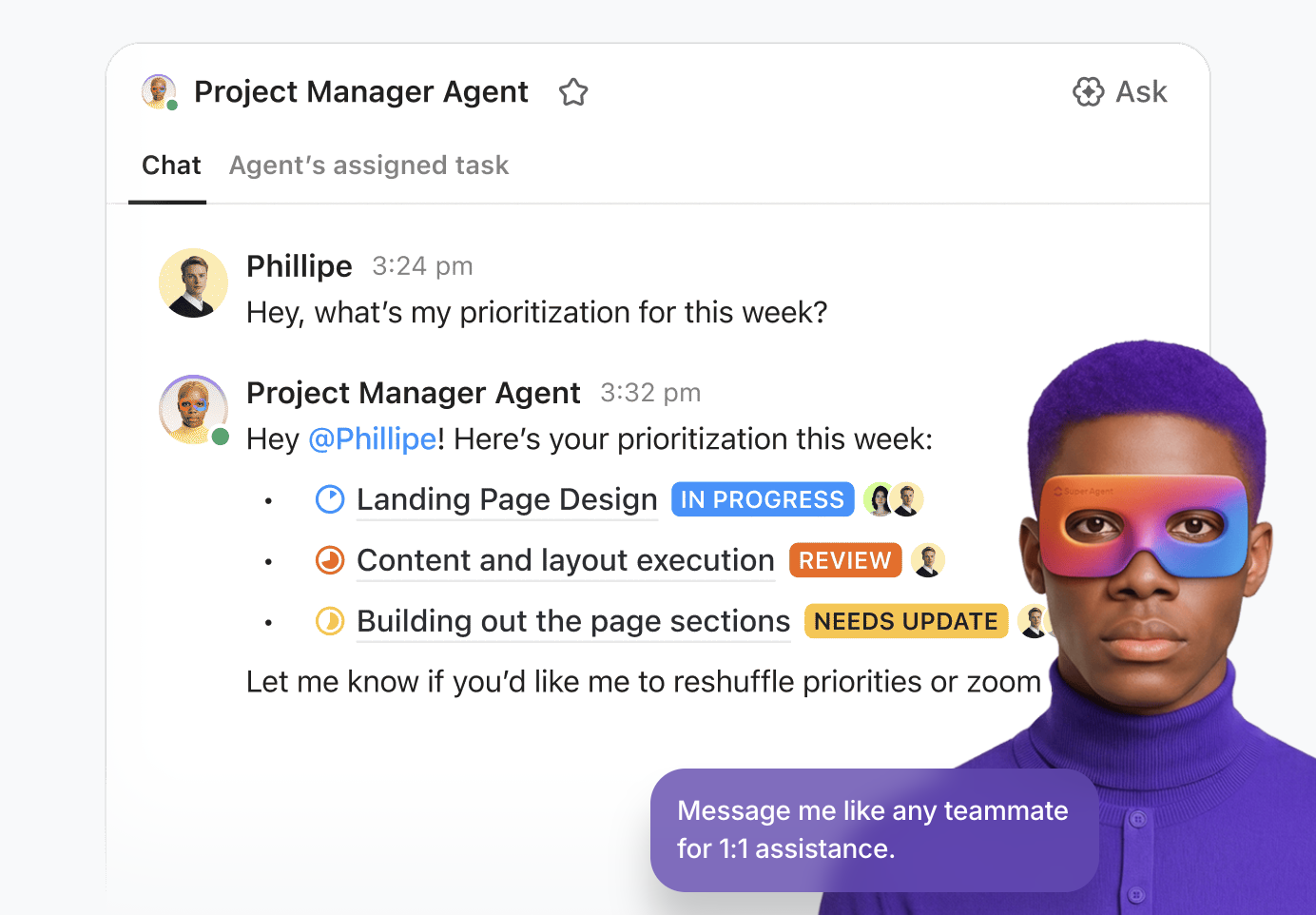
Můžete je vytvořit a nasadit pomocí vizuálního nástroje bez nutnosti programování, který vám umožní:
- Identifikujte počáteční událost, například zprávu nebo změnu stavu úkolu.
- Nastavte provozní pravidla, včetně způsobu shrnutí dat, delegování práce nebo úpravy priorit.
- Provádějte externí akce pomocí integrovaných nástrojů a rozšíření.
- Poskytněte podpůrná data připojením agenta k relevantním znalostním bázím.
Více informací o super agentech najdete v níže uvedeném videu.
Vylepšete svou strategii AI: Pořiďte si ClickUp
Díky jemné úpravě se AI naučí vaše vzorce na statických příkladech, ale použití konvergovaného softwaru v pracovním prostoru, jako je ClickUp, eliminuje rozptýlení kontextu tím, že vaší AI poskytuje živý, automatický kontext.
To je jádro úspěšné transformace AI: týmy, které centralizují svou práci na propojené platformě, tráví méně času trénováním AI a více času využíváním jejích výhod. Jak se váš pracovní prostor vyvíjí, vaše AI se vyvíjí automaticky – bez nutnosti opakovaných tréninkových cyklů.
Jste připraveni přeskočit trénink a začít s AI, která již zná vaši práci? Začněte zdarma s ClickUp a vyzkoušejte výhody konvergovaného pracovního prostoru.
Často kladené otázky (FAQ)
Váš doladěný model se učí z vašich tréninkových příkladů, ale základní model Gemini od Google ve výchozím nastavení neuchovává vaše konverzační data ani se z nich neučí. Váš vlastní model je oddělený od základního modelu, který slouží ostatním uživatelům.
Samotný výcvik může trvat jen několik hodin, ale větší časovou investici vyžaduje příprava vysoce kvalitních výcvikových dat. Tato fáze přípravy dat může často trvat několik dní nebo dokonce týdnů, než bude správně dokončena.
Ano, pomocí Google AI Studio můžete model doladit bez psaní kódu. Poskytuje vizuální rozhraní, které zvládá většinu technické složitosti, i když stále budete muset rozumět požadavkům na formátování dat.
Vlastní pokyny jsou dočasné výzvy založené na relaci, které řídí chování modelu pro jednu konverzaci. Jemné ladění však trvale upravuje vnitřní parametry modelu na základě vašich trénovacích příkladů a vytváří trvalé změny v jeho chování.