![Как да обучите Gemini на базата на вашите собствени данни през [година]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Според скорошно проучване сред предприятия, 73% от организациите съобщават, че техните AI модели не успяват да разберат специфичната за компанията терминология и контекст, което води до резултати, които изискват обширна ръчна корекция. Това се превръща в едно от най-големите предизвикателства при внедряването на AI.
Големите езикови модели като Google Gemini вече са обучени на базата на огромни публични набори от данни. Това, от което повечето компании наистина се нуждаят, не е обучение на нов модел, а обучение на Gemini за контекста на вашия бизнес: вашите документи, работни процеси, клиенти и вътрешни знания.
Това ръководство ви води през целия процес на обучение на модела Gemini на Google въз основа на вашите собствени данни. Ще обхванем всичко – от подготовката на набори от данни в правилния JSONL формат до изпълнението на задачи за настройка в Google AI Studio.
Ще проучим и дали конвергентното работно пространство с вграден AI контекст може да ви спести седмици настройки.
Какво е фино настройване на Gemini и защо е важно?
Настройването на Gemini е процесът на обучение на базовия модел на Google въз основа на вашите собствени данни.
Искате изкуствен интелект, който разбира вашия бизнес, но готовите модели дават общи отговори, които не са точни. Това означава, че губите време в постоянни корекции на резултатите, повторно обясняване на терминологията на вашата компания и се разочаровате, когато изкуственият интелект просто не разбира.
Това постоянно отиване и връщане забавя екипа ви и подкопава обещанието за производителност на изкуствения интелект.
Фината настройка на Gemini създава персонализиран модел Gemini, който научава вашите специфични модели, тон и познания в областта, което му позволява да реагира по-точно на вашите уникални случаи на употреба. Този подход работи най-добре за последователни, повтарящи се задачи, при които базовият модел повтарящо се проваля.
Как фината настройка се различава от промт инженеринга
Процесът на инженеринг на подсказки включва даване на временни инструкции на модела, базирани на сесията, всеки път, когато взаимодействате с него. След като разговорът приключи, моделът забравя вашия контекст.
Този подход достига своя таван, когато вашият случай на употреба изисква специализирани знания, които базовият модел просто не притежава. Можете да дадете само толкова инструкции, преди да се наложи моделът да научи вашите модели.
В контраст с това, фината настройка променя трайно поведението на модела, като модифицира вътрешните му тегла въз основа на вашите примери за обучение, така че промените се запазват във всички бъдещи сесии.
Настройката не е бързо решение за спорадични проблеми с изкуствения интелект; тя е значителна инвестиция на време и данни. Най-смислено е да се използва в конкретни сценарии, в които базовият модел постоянно не отговаря на изискванията и се нуждаете от трайно решение.
Обмислете фина настройка, когато имате нужда AI да овладее:
- Специализирана терминология: Вашата индустрия използва жаргон, който моделът постоянно интерпретира погрешно или не използва правилно.
- Последователен формат на изхода: Имате нужда от отговори с много специфична структура всеки път, като например генериране на отчети или фрагменти от код.
- Експертни познания в областта: Моделът не разполага с познания за вашите нишови продукти, вътрешни процеси или собствени работни потоци.
- Глас на марката: Искате всички резултати, генерирани от изкуствения интелект, да съответстват напълно на точния глас, стил и личност на вашата компания.
| Аспект | Програмиране на подсказки | Фина настройка |
| Какво представлява | Създаване на по-добри инструкции в подсказката, за да насочите поведението на модела | Допълнително обучение на модела въз основа на ваши собствени примери |
| Какви промени | Входните данни, които изпращате към модела | Вътрешните тегла на модела |
| Бързина на внедряване | Незабавно — работи мигновено | Бавно — изисква подготовка на набор от данни и време за обучение |
| Техническа сложност | Ниско — не се изискват познания по машинно обучение | Средно до високо — изисква ML пипалини |
| Необходими данни | Няколко добри примера в подсказката | Стотици до хиляди маркирани примери |
| Последователност на резултатите | Средно — варира в зависимост от подсказките | Високо — поведението е вградено в модела |
| Най-подходящо за | Еднократни задачи, експерименти, бърза итерация | Повтарящи се задачи, изискващи последователни резултати |
Процесът на инженеринг определя какво казвате на модела. Фината настройка определя как моделът мисли.
Макар че тази статия се фокусира върху Gemini, разбирането на алтернативни подходи към персонализирането на изкуствения интелект може да ви даде ценна перспектива за различни методи за постигане на сходни цели.
Това видео показва как да създадете персонализиран GPT, друг популярен подход за адаптиране на изкуствения интелект за конкретни случаи на употреба:
📖 Прочетете също: Как да станете инженер по подсказки
Как да подготвите вашите данни за обучение за Gemini
Повечето проекти за фина настройка се провалят още преди да започнат, защото екипите подценяват процеса на подготовка на данните. Gartner прогнозира, че 60% от AI проектите ще бъдат изоставени поради неадекватни данни, подходящи за AI.
Можете да прекарате седмици в събиране и форматиране на данни по грешен начин, само за да се провали обучението или да се получи безполезен модел. Това често е най-отнемащата част от целия процес, но правилното й изпълнение е най-важният фактор за успеха.
Принципът „гараж в, гараж из“ важи в голяма степен тук. Качеството на вашия персонализиран модел ще бъде пряко отражение на качеството на данните, с които го обучавате.
Изисквания към формата на набора от данни
Gemini изисква вашите данни за обучение да бъдат в специфичен формат, наречен JSONL, което означава JSON Lines. В JSONL файл всеки ред е пълен, самостоятелен JSON обект, който представлява един пример за обучение. Тази структура улеснява системата да обработва големи масиви от данни ред по ред.
Всеки пример за обучение трябва да съдържа две ключови полета:
- text_input: Това е подсказката или въпросът, който бихте задали на модела.
- изход: Това е идеалният, перфектен отговор, който искате моделът да се научи да дава.
За удобство Google AI Studio приема и качвания във формат CSV и ги конвертира в необходимата JSONL структура.
Това може да улесни първоначалното въвеждане на данни, ако вашият екип се чувства по-удобно да работи с електронни таблици.
Препоръки за размера на набора от данни
Макар качеството да е по-важно от количеството, все пак се нуждаете от минимален брой примери, за да може моделът да разпознава и научава модели. Ако започнете с твърде малко примери, моделът няма да може да генерализира или да работи надеждно.
Ето някои общи насоки за размера на набора от данни:
- Минимална жизнеспособност: За прости, високоспецифични задачи можете да започнете да виждате резултати с около 100 до 500 висококачествени примера.
- По-добри резултати: За по-сложни или нюансирани резултати, ако се стремите към 500 до 1000 примера, ще получите по-стабилен и надежден модел.
- Намаляваща възвръщаемост: В определен момент простото добавяне на повече повтарящи се данни няма да подобри значително производителността. Фокусирайте се върху разнообразието и качеството, а не върху обема.
Събирането на стотици висококачествени примери е значително предизвикателство за повечето екипи. Планирайте тази фаза на събиране на данни съответно, преди да се ангажирате с процеса на фина настройка.
📮 ClickUp Insight: Средностатистическият професионалист прекарва над 30 минути на ден в търсене на информация, свързана с работата си – това са над 120 часа годишно, загубени в претърсване на имейли, Slack низове и разпръснати файлове.
Интелигентен AI асистент, вграден във вашето работно пространство, може да промени това. Запознайте се с ClickUp Brain. Той предоставя незабавни прозрения и отговори, като извежда подходящите документи, разговори и подробности за задачите за секунди – така че можете да спрете да търсите и да започнете да работите.
💫 Реални резултати: Екипи като QubicaAMF спестиха над 5 часа седмично с помощта на ClickUp – това са над 250 часа годишно на човек – като премахнаха остарелите процеси за управление на знанията. Представете си какво би могъл да създаде вашият екип с една допълнителна седмица продуктивност на тримесечие!
Най-добри практики за качеството на данните
Непоследователните или противоречиви примери ще объркат модела, което ще доведе до ненадеждни и непредсказуеми резултати. За да избегнете това, вашите данни за обучение трябва да бъдат внимателно подбрани и почистени. Един единствен лош пример може да унищожи наученото от много добри примери.
Следвайте тези указания, за да гарантирате високо качество на данните:
- Последователност: Всички примери трябва да следват един и същ формат, стил и тон. Ако искате AI да бъде формален, всички ваши примери за резултати трябва да бъдат формални.
- Разнообразие: Вашият набор от данни трябва да обхваща пълния спектър от входни данни, с които моделът вероятно ще се сблъска при реалното му използване. Не го обучавайте само на лесни случаи.
- Точност: Всеки отделен пример за резултат трябва да бъде перфектен. Той трябва да бъде точното отговора, който искате моделът да даде, без никакви грешки или правописни грешки.
- Чистота: Преди обучението трябва да премахнете дублиращите се примери, да поправите всички правописни и граматически грешки и да разрешите всички противоречия в данните.
Силно се препоръчва няколко души да прегледат и потвърдят примерите за обучение. Един свеж поглед често може да забележи грешки или несъответствия, които може да сте пропуснали.
Как да настроите Gemini стъпка по стъпка
Процесът на фина настройка на Gemini включва няколко технически стъпки в платформите на Google. Една единствена грешка в конфигурацията може да ви коства часове ценно време за обучение и изчислителни ресурси, като ви принуди да започнете отначало. Това практическо ръководство е създадено, за да намали опитите и грешките, като ви води през процеса от начало до край. 🛠️
Преди да започнете, ще ви е необходим акаунт в Google Cloud с активирана функция за фактуриране и достъп до Google AI Studio. Отделете поне няколко часа за първоначалната настройка и първата си задача за обучение, както и допълнително време за тестване и итерация на модела си.
Стъпка 1: Настройте Google AI Studio
Google AI Studio е уеб-базиран интерфейс, чрез който можете да управлявате целия процес на фина настройка. Той предоставя лесен за ползване начин да качвате данни, да конфигурирате обучението и да тествате своя персонализиран модел, без да пишете код.
Първо, отидете на ai.google.dev и влезте с вашия Google акаунт.
Трябва да приемете условията за ползване и да създадете нов проект в Google Cloud Console, ако все още нямате такъв. Уверете се, че сте активирали необходимите API, както ви подсказва платформата.
Стъпка 2: Качете вашия обучителен набор от данни
След като сте готови, преминайте към раздела за настройка в Google AI Studio. Тук ще започнете процеса на създаване на свой персонализиран модел.
Изберете опцията „Създаване на настроен модел“ и изберете базовия си модел. Gemini 1. 5 Flash е често използван и икономичен избор за фина настройка.
След това качите JSONL или CSV файла, съдържащ подготвения от вас набор от данни за обучение. Платформата ще провери вашия файл, за да се увери, че отговаря на изискванията за форматиране, като отбележи всички често срещани грешки, като липсващи полета или неправилна структура.
Стъпка 3: Конфигурирайте настройките за фина настройка
След като данните ви бъдат качени и валидирани, ще конфигурирате параметрите за обучение. Тези настройки, известни като хиперпараметри, контролират начина, по който моделът се учи от вашите данни.
Основните опции, които ще видите, са:
- Епохи: Това определя колко пъти моделът ще се обучава върху целия ви набор от данни. Повече епохи могат да доведат до по-добро обучение, но също така и до риск от прекомерно приспособяване.
- Скорост на обучение: Това контролира колко агресивно моделът коригира тежестите си въз основа на вашите примери.
- Размер на партидата: Това определя колко примера за обучение се обработват заедно в една група.
За първия си опит е най-добре да започнете с препоръчаните от Google AI Studio настройки по подразбиране. Платформата опростява тези сложни решения, като ги прави достъпни дори и да не сте експерт в областта на машинно обучение.
Стъпка 4: Изпълнете задачата за настройка
След като конфигурирате настройките, можете да започнете работата по настройката. Сървърите на Google ще започнат да обработват вашите данни и да коригират параметрите на модела. Този процес на обучение може да отнеме от няколко минути до няколко часа, в зависимост от размера на вашия набор от данни и избрания от вас модел.
Можете да следите напредъка на задачата директно в таблото за управление на Google AI Studio. Тъй като задачата се изпълнява на сървърите на Google, можете спокойно да затворите браузъра си и да се върнете по-късно, за да проверите състоянието. Ако задачата се провали, това почти винаги се дължи на проблем с качеството или форматирането на вашите данни за обучение.
Стъпка 5: Тествайте своя персонализиран модел
След като обучението приключи, вашият персонализиран модел е готов за тестване. ✨
Можете да го намерите в интерфейса на playground в Google AI Studio.
Започнете, като изпратите тестови команди, които са подобни на вашите примери за обучение, за да проверите неговата точност. След това го тествайте в крайни случаи и нови варианти, които не е виждал преди, за да оцените способността му да генерализира.
- Точност: Дава ли точните резултати, за които сте го обучили?
- Обобщение: Правилно ли обработва нови входни данни, които са подобни, но не идентични с вашите данни за обучение?
- Последователност: Отговорите му надеждни и предсказуеми ли са при многократни опити с една и съща команда?
Ако резултатите не са задоволителни, вероятно ще трябва да се върнете назад, да подобрите данните за обучение, като добавите повече примери или поправите несъответствията, и след това да преобучите модела.
📖 Прочетете също: Как да извлечете максимална полза от изкуствения интелект за иновации и ефективност
Най-добри практики за обучение на Gemini с персонализирани данни
Простото следване на техническите стъпки не гарантира отличен модел. Много екипи завършват процеса, но остават разочаровани от резултатите, защото пропускат стратегиите за оптимизация, които използват опитни практици. Това е разликата между функционален модел и модел с висока производителност.
Не е изненадващо, че докладът на Deloitte „Състоянието на генеративната изкуствена интелигентност в предприятията“ установи, че две трети от компаниите съобщават, че 30% или по-малко от техните експерименти с генеративна изкуствена интелигентност ще бъдат напълно мащабирани в рамките на шест месеца.
Прилагането на тези най-добри практики ще ви спести време и ще доведе до много по-добри резултати.
- Започнете с малко, а след това мащабирайте: Преди да се ангажирате с пълно обучение, тествайте подхода си с малка подгрупа от вашите данни (например 100 примера). Това ви позволява да валидирате формата на данните си и да получите бърза представа за производителността, без да губите часове.
- Версионирайте вашите набори от данни: Когато добавяте, премахвате или редактирате примери за обучение, запазете всяка версия на вашия набор от данни. Това ви позволява да проследявате промените, да възпроизвеждате резултатите и да се връщате към предишна версия, ако новата работи по-зле.
- Тествайте преди и след: Преди да започнете с фината настройка, определете базова линия, като оцените представянето на базовия модел по отношение на вашите ключови задачи. Това ви позволява да измерите обективно колко подобрение са постигнали вашите усилия за фина настройка.
- Повторете при неуспех: Когато вашият персонализиран модел даде грешен или неправилно форматиран отговор, не се разочаровайте. Добавете този конкретен неуспешен случай като нов, коригиран пример във вашите данни за обучение за следващата итерация.
- Документирайте процеса: Водете дневник на всеки цикъл на обучение, като отбелязвате използваната версия на набора от данни, хиперпараметрите и резултатите. Тази документация е безценна за разбирането на това, което работи и какво не работи с течение на времето.
Управлението на тези итерации, версии на набори от данни и документация изисква солидно управление на проекти. Централизирането на тази работа в платформа, проектирана за структурирани работни процеси, може да предотврати хаоса в процеса.
Често срещани предизвикателства при обучението на Gemini
Екипите често инвестират значително време и ресурси в фина настройка, само за да се сблъскат с предвидими препятствия, които водят до загуба на усилия и разочарование. Познаването на тези често срещани капани предварително може да ви помогне да преминете по-гладко през процеса.
Ето някои от най-често срещаните предизвикателства и начини за справяне с тях:
- Прекомерно приспособяване: Това се случва, когато моделът запомня перфектно вашите примери за обучение, но не успява да ги обобщи за нови, невиждани входни данни. За да поправите това, можете да добавите повече разнообразие към вашите данни за обучение, да обмислите намаляване на броя на епохите или да проучите алтернативни методи като генериране, подсилено с извличане.
- Несъответстващи резултати: Ако моделът дава различни отговори на много сходни въпроси, вероятно това се дължи на противоречиви или несъответстващи примери във вашите данни за обучение. Необходимо е цялостно почистване на данните, за да се разрешат тези конфликти.
- Отклонение от формата: Понякога моделът започва да следва желаната от вас структура на изхода, но с течение на времето се „отклонява” от нея. Решението е да включите изрични инструкции за формата в изхода на вашите примери за обучение, а не само в съдържанието.
- Бавни цикли на итерация: Когато всяко обучение отнема часове, това значително забавя вашата способност да експериментирате и да се усъвършенствате. Тествайте идеите си първо върху по-малки набори от данни, за да получите по-бърза обратна връзка, преди да стартирате пълно обучение.
- Пречка при събирането на данни: Често най-трудната част е пречката при събирането на данни, а именно простото събиране на достатъчно висококачествени примери. Започнете, като използвате най-доброто си съществуващо съдържание – като билети за поддръжка, маркетингови текстове или технически документи – и разширете оттам.
Тези предизвикателства са основната причина, поради която много екипи в крайна сметка търсят алтернативи на ръчния процес на фина настройка.
📮ClickUp Insight: 88% от участниците в нашето проучване използват AI за личните си задачи, но над 50% се въздържат да го използват на работа. Трите основни пречки? Липса на безпроблемна интеграция, пропуски в знанията или опасения за сигурността. Но какво ще стане, ако AI е вграден във вашето работно пространство и вече е сигурен? ClickUp Brain, вграденият AI асистент на ClickUp, прави това реалност. Той разбира команди на обикновен език, решавайки и трите проблема, свързани с внедряването на AI, като същевременно свързва вашия чат, задачи, документи и знания в цялото работно пространство. Намерете отговори и идеи с едно кликване!
Защо ClickUp е по-умна алтернатива
Фината настройка на Gemini е мощна, но е и временно решение.
В тази статия видяхме, че фината настройка в крайна сметка се свежда до едно: да научим AI да разбира контекста на вашия бизнес. Проблемът е, че фината настройка прави това индиректно. Вие подготвяте набори от данни, създавате примери, преобучавате модели и поддържате пипалини, за да може AI да се доближи до начина, по който работи вашият екип.
Това има смисъл за специализирани случаи на употреба. Но за повечето екипи истинската цел не е персонализацията на Gemini сама по себе си. Целта е по-проста:
Искате изкуствен интелект, който разбира вашата работа.
Тук ClickUp използва фундаментално различен и по-интелигентен подход.
Converged AI Workspace на ClickUp предоставя на вашия екип изкуствен интелект, който разбира контекста на вашата работа незабавно – без да се налага да полагате големи усилия. Вместо да обучавате изкуствения интелект да научава вашия контекст по-късно, вие работите с ClickUp Brain, интегрирания асистент с изкуствен интелект, където вашият контекст вече съществува.
Вашите задачи, документи, коментари, история на проектите и решения са свързани по подразбиране. Няма нужда да обучавате AI на вашите данни, защото той вече се намира там, където се извършва вашата работа, и се възползва от съществуващата ви екосистема за управление на знания.
| Аспект | Фина настройка на Gemini | ClickUp Brain |
|---|---|---|
| Време за настройка | Подготовка на данни за няколко дни до седмици | Незабавно – работи с съществуващите данни в работната среда |
| Източник на контекста | Ръчно подбрани примери за обучение | Автоматичен достъп до всички свързани задачи |
| Поддръжка | Преобучете го, когато нуждите ви се променят. | Непрекъснато актуализирано в зависимост от развитието на вашата работна среда |
| Необходими технически умения | Умерено до високо | Няма |
Тъй като ClickUp е вашата система за работа, ClickUp Brain работи във вашата свързана графика с данни. Няма разпространение на изкуствен интелект в несвързани инструменти, няма нестабилни процеси на обучение и няма риск моделът да се разсинхронизира с начина, по който вашият екип действително работи.
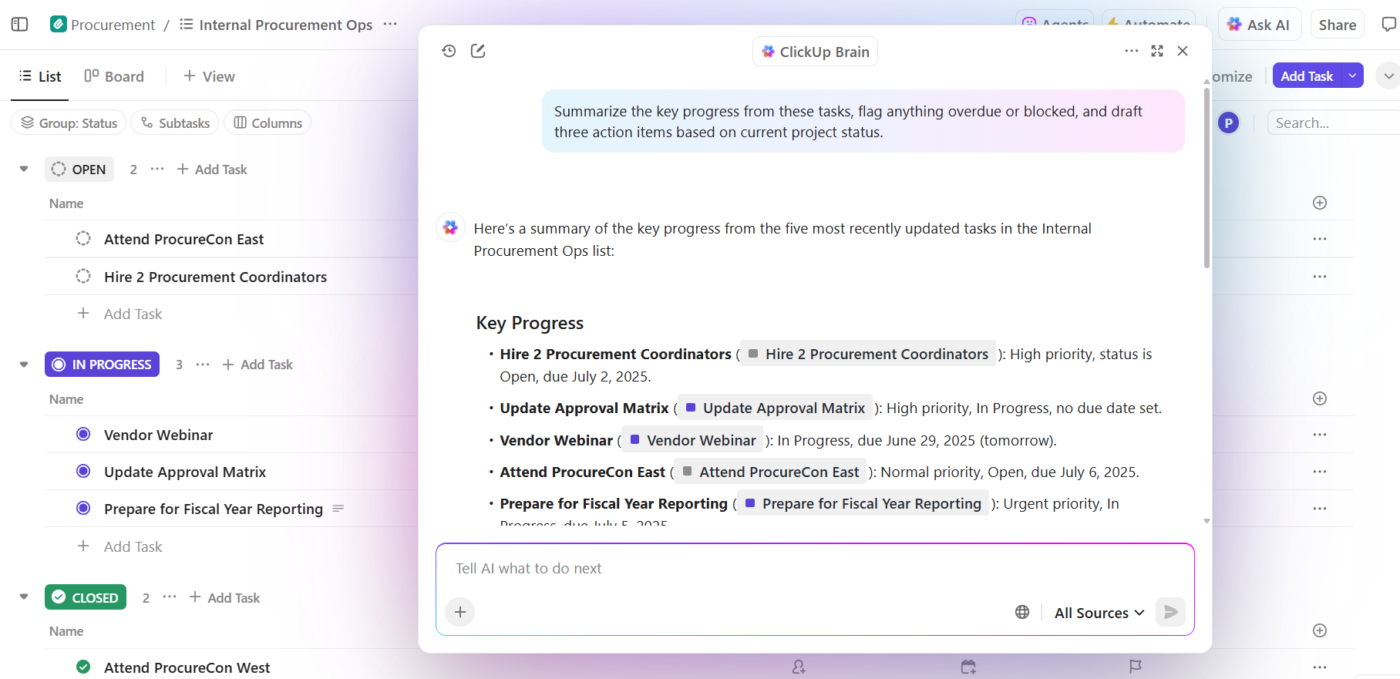
Ето как изглежда това на практика:
- Задавайте въпроси за вашите проекти: ClickUp Brain извършва търсене в работната среда сред задачи, документи, коментари и актуализации, за да отговори на въпросите, използвайки реалните данни от вашия проект, а не общи знания от обучението.
- Създавайте съдържание с контекст: ClickUp Brain вече има сигурен достъп до вашите задачи, файлове, коментари и история на проектите. Може да създава документи, резюмета и актуализации на статуса, които се позовават на вашата реална работа, графици и приоритети. Край на разпръснатия контекст, при който екипите губят часове в търсене на информация в различни приложения и файлове.
- Автоматизирайте с разбиране: С ClickUp Automations можете да създадете автоматизация, която реагира интелигентно на контекста на проекта, като крайни срокове, собственост и промени в статуса, а не само на статични правила. AI може дори да ги създаде за вас, без да е необходим код.
💡Съвет от професионалист: Използвайте истинската сила на изкуствения интелект в работното си пространство с ClickUp Super Agents.
Super Agents са AI-задвижвани съотборници на ClickUp – конфигурирани като AI „потребители“, които работят заедно с вашия екип в работната среда. Те са адаптивни и контекстуални и могат да бъдат назначени на задачи, споменавани в коментари, задействани чрез събития или графици или насочвани чрез чат – точно като човешки съотборник.
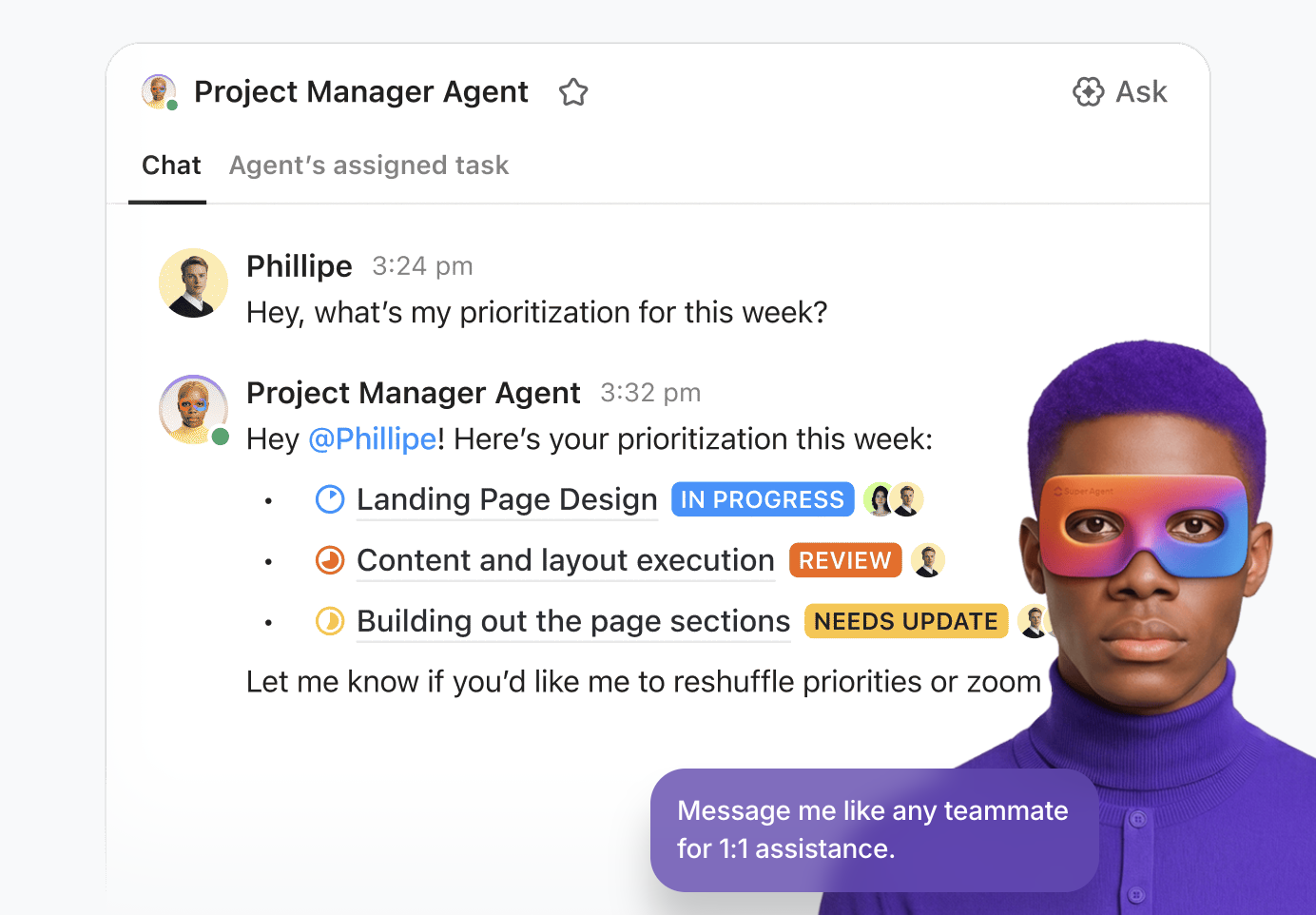
Можете да ги създадете и внедрите, използвайки визуалния конструктор без код, който ви позволява:
- Идентифицирайте началното събитие, като например съобщение или промяна в статуса на задачата.
- Очертайте оперативните правила, включително как да обобщавате данни, делегирате работа или коригирате приоритети.
- Изпълнявайте външни действия чрез интегрирани инструменти и разширения
- Предоставете подкрепящи данни, като свържете агента с подходящи бази от знания.
Научете повече за Super Agents във видеото по-долу.
Настройте стратегията си за изкуствен интелект: Използвайте ClickUp
Фината настройка учи AI вашите модели чрез статични примери, но използването на конвергентен софтуер в работна среда като ClickUp елиминира разширяването на контекста, като предоставя на AI ви жив, автоматичен контекст.
Това е същността на успешната AI трансформация: екипите, които централизират работата си в свързана платформа, прекарват по-малко време в обучение на AI и повече време в извличане на ползи от нея. С развитието на вашето работно пространство, вашата AI се развива автоматично – без да са необходими цикли на преобучение.
Готови ли сте да пропуснете обучението и да започнете с AI, който вече познава работата ви? Започнете безплатно с ClickUp и се насладете на предимствата на конвергентното работно пространство.
Често задавани въпроси (FAQ)
Вашият фино настроен модел се учи от вашите примери за обучение, но базовият модел Gemini на Google по подразбиране не запазва и не се учи от вашите данни за разговори. Вашият персонализиран модел е отделен от основния модел, който обслужва други потребители.
Самото обучение може да отнеме само няколко часа, но по-голямата част от времето се инвестира в подготовката на висококачествени данни за обучение. Тази фаза на подготовка на данните често може да отнеме дни или дори седмици, за да бъде завършена правилно.
Да, можете да настроите модела без да пишете код, като използвате Google AI Studio. Той предоставя визуален интерфейс, който се справя с по-голямата част от техническата сложност, въпреки че все пак ще трябва да разберете изискванията за форматиране на данните.
Персонализираните инструкции са временни, базирани на сесията подсказки, които насочват поведението на модела за един разговор. Фината настройка обаче трайно коригира вътрешните параметри на модела въз основа на вашите примери за обучение, създавайки трайни промени в неговото поведение.