

AI промени това, което инженерите трябва да документират сами. GitHub Copilot, Cursor и Mintlify могат да генерират документи от първи прочит: описания на параметри, обобщения на функции и README шаблони. Това, което те не могат да напишат, е слоят на намерението: взетото решение, приетият компромис, ограничението, което е имало значение, и опцията, която екипът е отхвърлил.
Кодът показва поведение. Той рядко запазва обосновката. Тази обосновка обикновено се намира в нишка в Slack, коментар към тикет, преглед на инцидент или в паметта на някого.
Проучването на Stack Overflow сред разработчиците за 2024 г. установи, че 61% от професионалните разработчици прекарват повече от 30 минути на ден в търсене на отговори по време на работа, като един на всеки четирима прекарва над час. Разбира се, някои търсения са неизбежни. Но истинската загуба е контекстът на спринта, който никога не е бил включен в документацията.
Това ръководство показва какво трябва да пишат самите инженери, къде изкуственият интелект може да помогне и как да се поддържат документите за кода полезни след края на спринта.
TL;DR
AI може да изготви механичната част от документацията: docstrings, типове параметри, обобщения на функции и README шаблони. Инженерите все още трябва да напишат частта с намеренията: решенията, компромисите, ограниченията и отхвърлените варианти, които стоят зад кода.
Инженерите все пак трябва да пишат това сами в записите за архитектурни решения, описанията на PR и коментарите с обяснения, добавени заедно с кода. Слоят с намеренията предотвратява следващият разработчик да прави обратно инженерство на решенията въз основа на имена на променливи, съобщения за потвърждаване и стари PR. Изкуственият интелект вече може да изготвя рутинните части: типове параметри, описания на връщаните стойности и основни обобщения на функциите.
Какво всъщност трябва да обяснява документацията на кода?
Документацията на кода трябва да помогне на следващия разработчик да разбере какво прави кодът, как да го използва безопасно и защо е създаден по този начин. Тя се появява на две места: вътре в изходните файлове като коментари и docstrings, и извън изходните файлове като README файлове, API справки, runbooks и бележки за архитектурата.
Повечето кодови бази стават трудни за четене, след като контекстът на взетите решения изчезне. Първоначалният разработчик може да е направил умен компромис. Следващият разработчик вижда само крайния продукт, а не мотивите.
Резултатът: всеки нов член на екипа трябва да разгадава намеренията от имената на променливите, съобщенията за потвърждаване и старите PR-и. Това забавя въвеждането в работата, прегледите, отстраняването на грешки и бъдещите промени в същата област.
Добрата документация отговаря на четири въпроса:
- За кого е предназначен този код? Вътрешни разработчици, сътрудници на отворения код, външни потребители на API или крайни потребители
- Какъв проблем решава? Бизнес или техническата необходимост, стояща зад модула
- Защо беше избран този подход? Разгледаните алтернативи и приетите компромиси
- Къде са свързаните елементи? Зависими модули, услуги нагоре по веригата, архитектурни решения, билети и ръководства за изпълнение
Въпросът „защо“ заслужава най-голямото внимание от страна на хората.
Търсенето вече е сериозен разход на интелектуална енергия и извън инженерството. Проучването на ClickUp за управлението на знанията установи, че 57% от служителите губят време в търсене на информация, свързана с работата, във вътрешни документи или бази от знания. Когато не могат да намерят това, от което се нуждаят, 1 от 6 се прибягва до лични алтернативни решения: претърсване на стари имейли, бележки или екранни снимки.
Документацията на кода се разпада по същия начин: ако разработчиците не могат да намерят обяснението, то е все едно, че то не съществува.
Цената на грешката е висока. Един коментатор в r/AskProgramming описа RPA работен процес, при който един недокументиран бутон почти предизвика автоматични банкови такси и писма до клиенти.
Търсенето вече е сериозен товар за работата с информация и извън инженерството. Проучването на ClickUp за управлението на знанията установи, че 57% от служителите губят време в търсене на информация, свързана с работата, във вътрешни документи или бази от знания. Когато не могат да намерят това, от което се нуждаят, 1 от 6 се прибягва до лични алтернативни решения: претърсване на стари имейли, бележки или екранни снимки.
Документацията на кода се разпада по същия начин: ако разработчиците не могат да намерят обяснението, то е все едно, че то не съществува.
Цената на грешката е висока. Един коментатор в r/AskProgramming описа RPA работен процес, при който недокументиран бутон почти предизвика автоматични банкови такси и писма до клиенти.
Какви са основните видове документация на кода?
Петте основни типа са вградени коментари, docstrings, README файлове, вътрешни уикита и външна API документация. Всеки от тях обслужва различен читател в различен момент. Смесването им прави документацията по-трудна за писане и по-трудна за използване. README, който се чете като docstring, губи нови сътрудници. Docstring, който се чете като уики страница, се превръща в мъртво тегло вътре в изходните файлове.
Вградени коментари и docstrings
Вградените коментари трябва да обясняват неочевидни разсъждения. Коментар, който преформулира x = x + 1 като „увеличаване на x“, не добавя нищо. Коментар, който гласи „офсет за отговор на API с индекс от нула“, си заслужава мястото, защото кодът не може да покаже това външно ограничение. Запазете вградените коментари за неочевидна логика в тялото на функцията.
Docstrings са структурирани описания, прикачени към функции, класове или модули. Те обхващат параметри, върнати стойности, изключения и примери за употреба. Всеки език има свои собствени конвенции. Следвайте конвенцията, която вашият език вече очаква: PEP 257 за Python docstrings, Javadoc за Java и JSDoc за JavaScript и TypeScript.
Сравнете тези две:
Слаб docstring:
Силна docstring:
Вторият дава ясно име на функцията, документира нейните параметри и извежда на преден план едно предположение: процесът на плащане използва данъчна ставка от 8,25%.
README файлове, уики страници и външни документи
README файлът трябва да отговаря на пет въпроса в следния ред: Какво прави този проект? Как да го инсталирам? Как да го използвам? Как да допринеса? Къде да потърся помощ? Ако нов сътрудник не може бързо да намери пътя за инсталиране, README файлът е или претрупан, или лошо организиран.
Уикита и базите от знания работят най-добре за съдържание, обхващащо множество хранилища или услуги: архитектурни решения, ръководства за въвеждане и наръчници. Уики, към което никой не поставя линк от кода, се превръща в втори проблем при търсенето.
Външната документация обхваща API справки, ръководства за SDK и документи, предназначени за потребителите. Тя служи на потребителите на вашия код, а не на сътрудниците. Външните документи се нуждаят от повече подробности за настройката, по-ясни стъпки за удостоверяване и структура от типа на справочник, тъй като читателят може изобщо да не познава вашата кодова база.
Ако екипът все още няма структура, започнете с шаблон за техническа документация за архитектура и бележки за настройка или с шаблон за проектна документация за цели, отговорни лица, етапи и решения. Адаптирайте секциите, вместо да измисляте формат от нулата.
| Тип | Основна аудитория | Честота на актуализиране | Типично местоположение |
|---|---|---|---|
| Вградени коментари | Разработчици, четящи конкретен код | Когато поведението на кода се променя | Изходни файлове |
| Docstrings | Разработчици, които извикват функция, клас или модул | Когато интерфейсът се промени | Изходни файлове |
| README | Нови сътрудници и оценители | За всяка основна версия или промяна в проекта | Корен на хранилището |
| Уики или база от знания | Вътрешни екипи и заинтересовани страни от различни екипи | С промяната на решенията или процесите | Уики на хранилището или споделена база от знания |
| Външни API документи | Потребители на API и крайни потребители | По версия или версия на API | Платформа за документация |
Как всъщност се пише документация днес?
Използвайте изкуствения интелект за частите, които той може да изготви. Отделете човешко време за решения, ограничения и компромиси.
Изкуственият интелект вече може да изготви голяма част от механичната работа: типове параметри, описания на връщаните стойности и основни обобщения на функциите. Работата по документирането, извършвана от хора, се разделя на две категории.
Първо напишете самодокументиращ се код
Най-добрата документация е кодът, който почти не се нуждае от нея. Описателните имена, функциите с една цел и последователните конвенции намаляват тежестта на документацията, още преди да сте написали и един коментар.
Самодокументиращият се код прави поведението по-лесно за четене. Той рядко обяснява логиката зад това поведение. Имената помагат на разработчиците да идентифицират какво прави даден елемент. Документацията трябва да обяснява логиката, която имената не могат да предадат.
Преди да добавите коментар, попитайте се дали преименуването на променлива или извличането на функция би направило коментара ненужен. Ако отговорът е да, първо преструктурирайте кода. Ясното име премахва коментарите, които само превеждат лошото име.
Преди:
След:
Преработената версия предава същата информация само чрез имената. Единственият полезен коментар сега би обяснил защо определени роли са изключени, което е решение на политиката, което кодът не може да изрази сам.
Напишете слоя с намеренията (частта, която изкуственият интелект не може да направи)
Реализацията е видима в кода. Намерението изчезва, освен ако някой не го запише. Кодът рядко запазва причината за даден компромис, ограничението, което е повлияло на дизайна, или коя алтернатива е била отхвърлена.
Едно често срещано правило сред разработчиците добре обобщава това: документирайте защо, а не какво. Коментар с най-много гласове в r/coding:
Виждам, че това условно разклонение е между червени и сини потребители. Кажете ми защо потребителите са класифицирани по този начин и защо правим разклонение между тях.
Виждам, че това условно разклонение е между червени и сини потребители. Кажете ми защо потребителите са класифицирани по този начин и защо правим разклонение между тях.
Съобщението за потвърждение може да помогне по време на прегледа, но не е подходящо място за обосновка на дизайна в дългосрочен план, тъй като бъдещите читатели рядко го намират в момента, когато им е необходимо.
Уил Ларсън, бивш технически директор на Calm и автор на An Elegant Puzzle, е писал за ценността на записите за архитектурни решения, тъй като те запазват инженерната обосновка извън кода.
ADR са полезни, защото осигуряват стабилна основа за обосновката на проекта. Ако вашият екип няма формат, използвайте лек шаблон за ADR: решение, контекст, разгледани варианти, компромиси и последствия.
Фокусирайте документацията си върху следните категории:
- Проектни решения и алтернативи: „Тук избрахме кеш с незабавно записване вместо кеш с отложено записване, защото за този платежен поток последователността на данните е по-важна от латентността при записване“
- Известни ограничения: Технически дълг, ограничения при мащабиране, временни решения или области, които се нуждаят от бъдещо почистване
- Предпоставки: Очаквани формати на входните данни, изисквания към средата или зависимости от по-горни нива, които кодът не налага
- Референции: Връзки към съответни тикети, RFC или записи за архитектурни решения (ADR), които обясняват по-широкия контекст
Различните контексти изискват различни места. Docstrings улавят намерението на ниво функция. Коментарите в кода се занимават с разсъжденията на ниво ред. Описанията на PR предоставят контекст на ниво промяна. ADR се занимават с решенията на ниво система. Съобщенията за потвърждение също помагат, но те не трябва да бъдат единственият запис на важно решение.
Често срещан антипаттерн: документиране на начина, по който работи алгоритъмът за сортиране ред по ред. Истинският въпрос е защо е използвано персонализирано сортиране вместо стандартната библиотека. За персонализирани кодови пътеки документирайте решението, стоящо зад имплементацията.
Кои са най-важните добри практики при документирането?
Пет практики правят документацията по-вероятно да остане полезна след края на спринта. Повечето други съвети за документацията зависят от това тези навици да работят първо.
- Документирайте докато пишете код, а не след това. Контекстът се размива бързо. До следващия спринт вече ще сте забравили коя алтернатива сте отхвърлили и защо. Напишете коментара с обяснението в същия коммит като кода, иначе изобщо няма да го напишете
- Използвайте последователен стилов наръчник. Изберете един формат за docstring, като например стилът на Google, NumPy, Javadoc или JSDoc, и го налагайте при преглед на кода или linting. Последователността е по-важна от това какъв формат ще изберете. Общият стилов наръчник елиминира въпроса „как да форматирам това?“ и прави възможно автоматизираното linting
- Разглеждайте документацията като част от прегледа на кода. Добавете проверки на документацията към списъка си за преглед на PR. Ако PR променя поведението, прегледащият трябва да провери дали документацията отразява промяната. Документацията за инженерните практики на Google изисква от прегледащите да проверяват дали кодът е подходящо документиран. Използвайте същото правило и вътрешно: ако PR променя поведението, прегледащите трябва да проверят дали коментарите, docstrings, README файловете и runbooks все още съответстват
- Изтрийте остарялата документация. Остарелите документи нанасят реална вреда, защото насочват читателите към грешна реализация, API или процес. Преглеждайте документите на тримесечие или преди всяко голямо пускане на версия. Определете отговорник, за да не бъде документацията отговорност на всички и следователно на никого
- Примерите трябва да могат да се изпълняват. Примерите за код трябва да са лесни за копиране, изпълнение и тестване. Това е най-сигурният начин да се открият отклонения, преди да го направят потребителите
Какви инструменти трябва да използвате за създаване на документация за кода?
Инструментите за документиране се разделят на две групи: традиционни генератори и AI асистенти. Те изпълняват различни задачи.
Традиционните генератори анализират структурираните коментари във вашия изходен код и създават прегледаеми справки. Подходящият генератор обикновено зависи от езика, който използвате.
| Инструмент | Език/Екосистема | Какво генерира |
|---|---|---|
| Javadoc | Java | API справка от коментари в документацията |
| JSDoc | JavaScript/TypeScript | API справка от коментари с анотации |
| Sphinx | Python (поддържа и други езици чрез плъгини) | Пълни сайтове с документация от reStructuredText или Markdown |
| Doxygen | C, C++, Java, Python и други | Референтна документация на различни езици |
| Godoc | Отидете | Документация на пакета от коментари в изходния код |
Качеството на резултата зависи изцяло от вашите docstrings. Те форматират и публикуват това, което сте написали. Те не измислят липсващи намерения.
Асистентите, задвижвани от изкуствен интелект, добавят второ ниво. GitHub Copilot, Cursor и Windsurf могат да изготвят коментари и docstrings вътре в редактора. Mintlify може да помогне за генерирането и поддържането на документация за разработчици въз основа на код и съществуваща документация. Swimm се фокусира върху поддържането на връзката между вътрешната документация и промените в кода. ReadMe и GitBook помагат на екипите да публикуват API референции и документация, насочена към разработчиците, често с функции за търсене или създаване на съдържание, подпомагани от изкуствен интелект.
Проучването на Stack Overflow установи, че документацията е най-често търсената категория за автоматизация чрез изкуствен интелект , спомената в около 33,9% от отворените отговори на разработчиците. Тези инструменти са най-ефективни, когато изходният код вече ясно показва поведението.
AI става по-слаб, когато обяснението зависи от решения, взети извън кода: нишка в Slack, среща за планиране, билет или преглед на инцидент. Той може да обобщи функцията. Не може да знае кое ограничение е било договаряемо, коя опция е била отхвърлена или защо компромисът е бил приет.
Практически работен процес:
- Нека изкуственият интелект изготви основната структура: обобщение на функциите, параметри, връщани стойности и често срещани изключения
- Сравнете я с действителното поведение на кода
- Добавете причината: решението, ограничението, предположението или отхвърлената алтернатива
- Напишете ADR за решения на системно ниво
- Не публикувайте документи, създадени от изкуствен интелект, без да ги прегледате
Къде ClickUp е подходящ и къде не е
ClickUp не е генератор на документация на ниво код. Той няма да замести Javadoc, Sphinx, JSDoc или Godoc. Той помага с документацията около кода: README файлове, ръководства за работа, наръчници за въвеждане, ADR и регистри на решения, които трябва да останат свързани със задачите, тикетите и спринтовете, които са ги създали.
ClickUp Docs ви позволява да ги изготвяте успоредно с инженерната си работа, а ClickUp Brain може да състави документ въз основа на контекста на задачата или проекта, след което разработчиците могат да добавят обосновката на решението, ограниченията и компромисите.
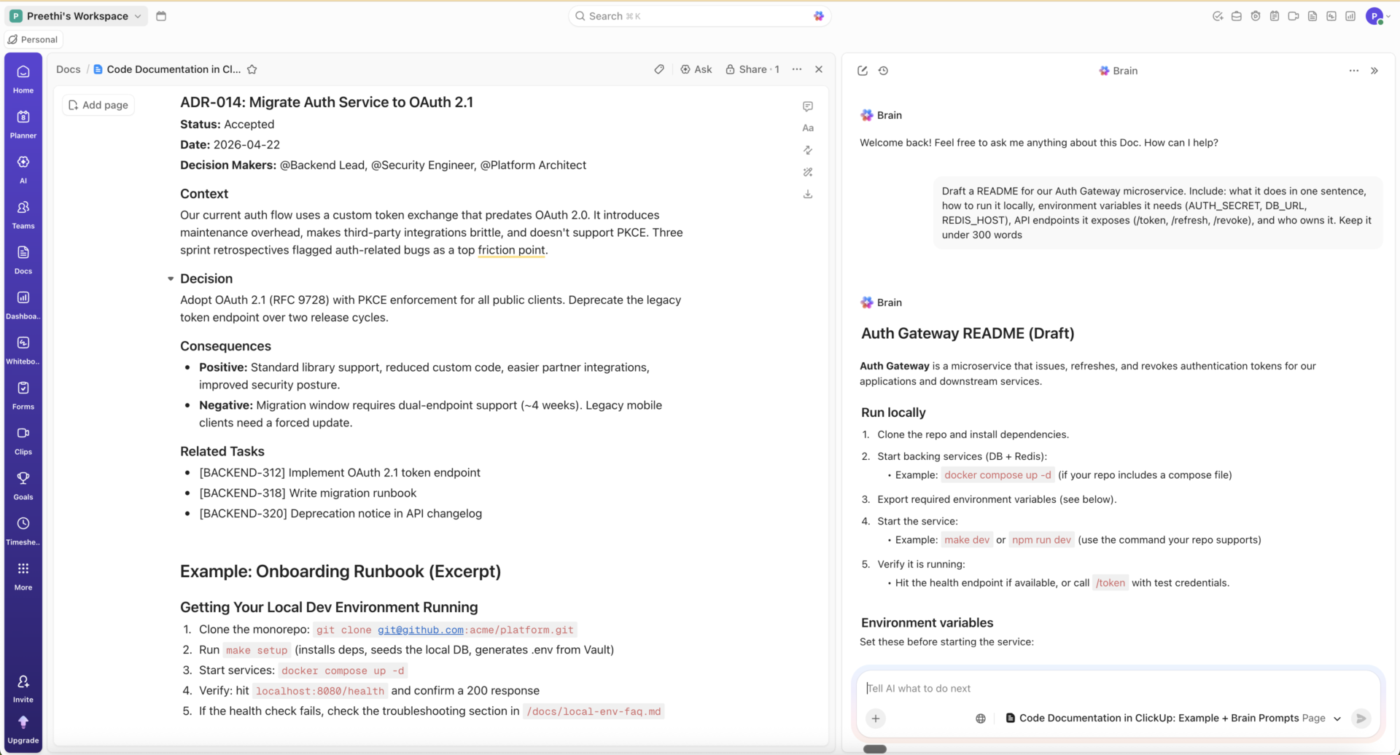
За инженерните екипи това означава по-малко време за претърсване на разпръснати документи, чатове и тикети и повече време за запазване на решенията, които тези инструменти обикновено затрупват.
Ако проблемът ви е, че „документите ни са технически пълни, но никой не може да ги намери“, това е проблем с откриваемостта. Една свързана работна среда може да ви помогне.
Ако проблемът ви е, че „нашата API референция е остаряла“, това е проблем, свързан с генератора и прегледа. Sphinx, Javadoc, JSDoc или Godoc ще ви помогнат повече от инструмент за работна среда. Не бъркайте двете неща.
Какво се променя, когато изкуственият интелект изготвя по-голямата част от документацията?
В темите в r/developersIndia, r/webdev и r/AskProgramming често се повтаря една шега за инженерната документация. Когато някой попита как екипът се справя с документацията, най-честият отговор обикновено е някаква версия на: „Аз съм документацията.“
Забавно е, защото е вярно. В продължение на години решението за липсващата документация е бил инженерът, който случайно си спомня.
AI променя стандартите. Тя може бързо да изготви рутинна документация, което прави недокументираните решения по-трудно оправдани. Когато AI може да структурира механичните части на вашите документи за секунди, „просто ще си спомня“ престава да бъде приемливо като система за записване.
Това пренасочва работата на инженера към намеренията, решенията и компромисите: частите, които синтаксисът сам по себе си не може да обясни.
Голяма част от старите съвети за документацията са написани за работни процеси отпреди ерата на изкуствения интелект. Те се фокусират предимно върху описания на параметри, сигнатури на функции и изчерпателни бележки за настройка.
Изкуственият интелект вече може да изготви голяма част от тази работа. Ако инженерите прекарват по-голямата част от времето си за документиране в изготвяне на механични обобщения, те отделят човешко внимание на нивото с най-ниска стойност.
Отделете това време за намерението: защо функцията съществува, коя опция сте отхвърлили и на какво предположение се основава кодът. Това са бележките, от които ще се нуждаят бъдещият ви екип, агентите за кодиране с изкуствен интелект и инженерът, който ще наследи кодовата база през 2027 г.
Ако проблемът ви с документацията е разпръснатият контекст, ClickUp може да ви помогне да запазите историята на решенията по-близо до задачите, документите и проектите, които са ги създали.
Често задавани въпроси относно документацията на кода
Какво е README?
README файлът издържа първия си тест, когато сътрудникът може бързо да намери пет неща: какво прави проектът, как да го инсталира, как да го използва, как да допринесе и къде да потърси помощ. Ако настройките са заровени под значки, бележки за архитектурата или подробности за промените, README файлът е лошо организиран.
Каква е разликата между коментарите в кода и документацията?
Коментарите в кода се намират в изходните файлове и обясняват конкретни редове или блокове. Документацията обикновено се намира извън изходните файлове в README файлове, уики страници, генерирани референтни сайтове или API документация. Коментарите помагат на следващия разработчик, който чете вашата функция. Документацията помага на следващия човек, който се опитва да използва, изпълни или допринесе за вашия проект.
Какво представлява слоят на намерението в документацията на кода?
Слойът на намерението е частта от документацията на кода, която улавя защо кодът съществува, а не какво прави: взетото решение, приетият компромис, ограничението, което е определило дизайна, и опцията, която екипът е отхвърлил. Кодът показва поведение; слоят на намерението запазва обосновката. AI инструменти като GitHub Copilot и Mintlify могат да изготвят механичния слой (типове параметри, обобщения на функции), но не могат да изведат слоя на намерението от синтаксиса. Той обикновено се намира в записите за архитектурни решения, описанията на PR или коментарите, които обясняват защо, а не какво.
Колко често трябва да се актуализира документацията на кода?
Актуализирайте документацията в същия pull request, който променя основното поведение. Ако сигнатурата на функцията се промени, docstring се променя в този PR. За README файловете и архитектурните документи провеждайте одит поне веднъж на версия или на тримесечие. Неактуалната документация е опасна, защото учи читателите на погрешно поведение, API или процес.
Какви са четирите вида документация?
Широко разпространената рамка Diátaxis разделя документацията на четири типа: уроци (ориентирани към обучението, за начинаещи), ръководства (ориентирани към задачите, за потребители, решаващи конкретен проблем), справки (ориентирани към информацията, за потребители, търсещи подробности) и обяснения (ориентирани към разбирането, за потребители, търсещи контекст). Смесването им създава документация, която никой не може да използва. README файл, който се опитва да бъде пълен урок, може да скрие пътя за настройка. Страница с справки, написана като есе, може да скрие API извикването.
Как се документира код с изкуствен интелект?
Използвайте ИИ за механичния слой и напишете сами слоя на намерението. Инструменти като GitHub Copilot, Cursor и Mintlify могат да изготвят чернови на docstrings, описания на параметри, връщани стойности и обобщения на функции директно във вашия редактор. Сравнете черновата с действителното поведение на кода, след което добавете частите, които ИИ не може да изведе: обосновката на решението, ограничението, което го е наложило, опцията, която сте отхвърлили, и всякакви предположения, от които зависи кодът. За решения на системно ниво напишете Архитектурен протокол за решения. Никога не публикувайте документи, генерирани от ИИ, без преглед от човек.
Надеждна ли е документацията, създадена от изкуствен интелект?
Документацията, генерирана от изкуствен интелект, е полезна за механична работа като описания на параметри, връщани стойности и обобщения на основни функции, но все пак се нуждае от човешка проверка. Инструменти като GitHub Copilot, Cursor, Codeium и Mintlify се справят добре с това. Изкуственият интелект не може да заключи защо е направен компромис, какви алтернативи са отхвърлени или какви ограничения на продукта, бизнеса или инфраструктурата са оформили дизайна. Използвайте изкуствения интелект за първия чернови вариант. Добавете намерението и контекста сами.
Всяка функция ли се нуждае от docstring?
Не. Публичните API и всяка функция, която друг разработчик ще извика, се нуждаят от docstrings. Частните помощници, използвани в един файл, обикновено не се нуждаят от такива, освен ако логиката не е очевидна. Прекаленото документиране на тривиален код създава тежест при поддръжката, без да добавя яснота. Съобразете дълбочината на документацията с аудиторията на функцията.
Кой е най-добрият инструмент за създаване на документация за код?
Подходящият инструмент зависи от езика, който използвате. Екипите, работещи с Java, използват Javadoc, екипите с JavaScript и TypeScript използват JSDoc, екипите с Python използват Sphinx, екипите с Go използват Godoc, а Doxygen поддържа C, C++ и няколко други езика. Инструменти, подпомагани от изкуствен интелект, като Mintlify, Swimm, Copilot и Cursor, могат да помогнат за изготвянето или поддържането на документация в различни части от работния процес, но те не заменят генераторите, специфични за езика.
Колко дълъг трябва да бъде README файлът?
Достатъчно дълъг, за да отговори бързо на основните въпроси: какво прави проектът, как се инсталира, как се използва, как да допринесете и къде да потърсите помощ. Поставете по-подробни данни за настройката, архитектурата и API в свързани документи или поддиректории.